 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectral Anomaly Detection with Self-Supervised Anomaly Prior
Paper and Code
Apr 20, 2024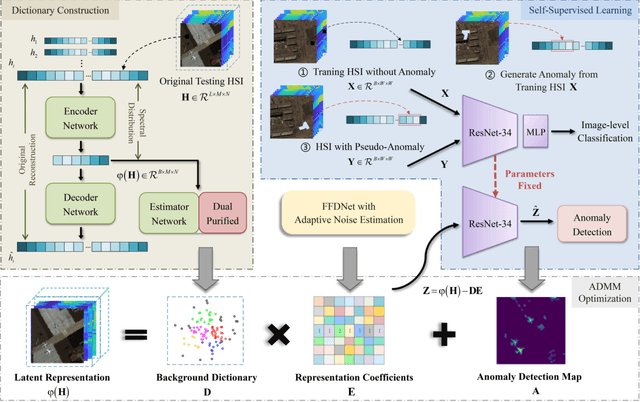


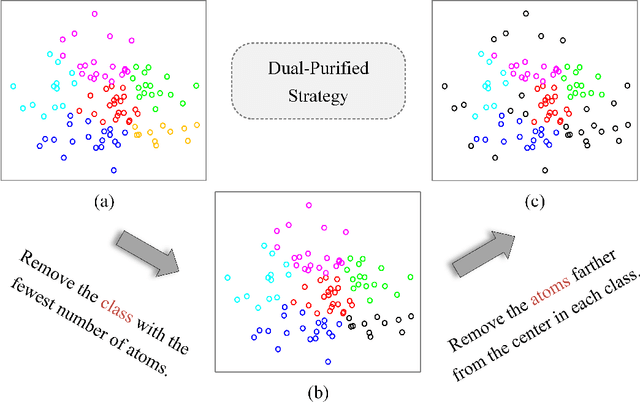
The majority of existing hyperspectral anomaly detection (HAD) methods use the low-rank representation (LRR) model to separate the background and anomaly components, where the anomaly component is optimized by handcrafted sparse priors (e.g., $\ell_{2,1}$-norm). However, this may not be ideal since they overlook the spatial structure present in anomalies and make the detection result largely dependent on manually set sparsity. To tackle these problems, we redefine the optimization criterion for the anomaly component in the LRR model with a self-supervised network called self-supervised anomaly prior (SAP). This prior is obtained by the pretext task of self-supervised learning, which is customized to learn the characteristics of hyperspectral anomalies. Specifically, this pretext task is a classification task to distinguish the original hyperspectral image (HSI) and the pseudo-anomaly HSI, where the pseudo-anomaly is generated from the original HSI and designed as a prism with arbitrary polygon bases and arbitrary spectral bands. In addition, a dual-purified strategy is proposed to provide a more refined background representation with an enriched background dictionary, facilitating the separation of anomalies from complex backgrounds. Extensive experiments on various hyperspectral datasets demonstrate that the proposed SAP offers a more accurate and interpretable solution than other advanced HAD methods.