 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Data Quality through Self-learning on Imbalanced Financial Risk Data
Sep 15, 2024



In the financial risk domain, particularly in credit default prediction and fraud detection, accurate identification of high-risk class instances is paramount, as their occurrence can have significant economic implications. Although machine learning models have gained widespread adoption for risk prediction, their performance is often hindered by the scarcity and diversity of high-quality data. This limitation stems from factors in datasets such as small risk sample sizes, high labeling costs, and severe class imbalance, which impede the models' ability to learn effectively and accurately forecast critical events. This study investigates data pre-processing techniques to enhance existing financial risk datasets by introducing TriEnhance, a straightforward technique that entails: (1) generating synthetic samples specifically tailored to the minority class, (2) filtering using binary feedback to refine samples, and (3) self-learning with pseudo-labels. Our experiments across six benchmark datasets reveal the efficacy of TriEnhance, with a notable focus on improving minority class calibration, a key factor for developing more robust financial risk prediction systems.
Ensemble BERT: A student social network text sentiment classification model based on ensemble learning and BERT architecture
Aug 09, 2024



The mental health assessment of middle school students has always been one of the focuses in the field of education. This paper introduces a new ensemble learning network based on BERT, employing the concept of enhancing model performance by integrating multiple classifiers. We trained a range of BERT-based learners, which combined using the majority voting method. We collect social network text data of middle school students through China's Weibo and apply the method to the task of classifying emotional tendencies in middle school students' social network texts. Experimental results suggest that the ensemble learning network has a better performance than the base model and the performance of the ensemble learning model, consisting of three single-layer BERT models, is barely the same as a three-layer BERT model but requires 11.58% more training time. Therefore, in terms of balancing prediction effect and efficiency, the deeper BERT network should be preferred for training. However, for interpretability, network ensembles can provide acceptable solutions.
Large-Scale Multi-Domain Recommendation: an Automatic Domain Feature Extraction and Personalized Integration Framework
Apr 15, 2024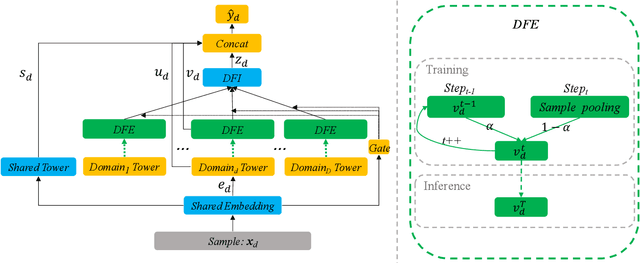

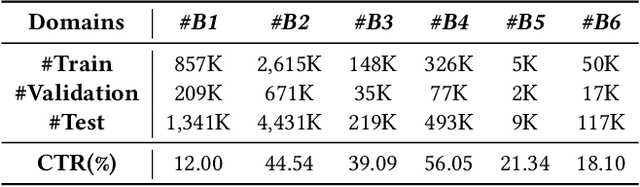
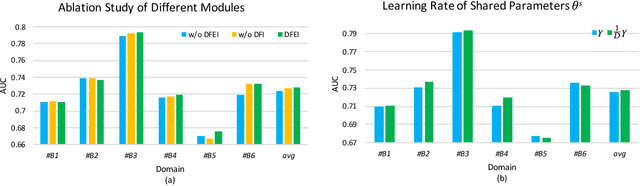
Feed recommendation is currently the mainstream mode for many real-world applications (e.g., TikTok, Dianping), it is usually necessary to model and predict user interests in multiple scenarios (domains) within and even outside the application. Multi-domain learning is a typical solution in this regard. While considerable efforts have been made in this regard, there are still two long-standing challenges: (1) Accurately depicting the differences among domains using domain features is crucial for enhancing the performance of each domain. However, manually designing domain features and models for numerous domains can be a laborious task. (2) Users typically have limited impressions in only a few domains. Extracting features automatically from other domains and leveraging them to improve the predictive capabilities of each domain has consistently posed a challenging problem. In this paper, we propose an Automatic Domain Feature Extraction and Personalized Integration (DFEI) framework for the large-scale multi-domain recommendation. The framework automatically transforms the behavior of each individual user into an aggregation of all user behaviors within the domain, which serves as the domain features. Unlike offline feature engineering methods, the extracted domain features are higher-order representations and directly related to the target label. Besides, by personalized integration of domain features from other domains for each user and the innovation in the training mode, the DFEI framework can yield more accurate conversion identification. Experimental results on both public and industrial datasets, consisting of over 20 domains, clearly demonstrate that the proposed framework achieves significantly better performance compared with SOTA baselines. Furthermore, we have released the source code of the proposed framework at https://github.com/xidongbo/DFEI.