 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Matching: Category-Guided Latent Intent Reasoning for Generative Retrieval in E-Commerce
Jun 05, 2026Generative retrieval offers a new paradigm for e-commerce search by mapping user queries directly to product Semantic Identifiers (SIDs). However, e-commerce queries are often short, noisy, attribute-heavy, and associated with multiple category-consistent products, creating a substantial representation gap between natural-language shopping intent and artificially constructed item SIDs. Explicit Chain-of-Thought (CoT) reasoning can help bridge this gap, but its extra generation cost is difficult to reconcile with the low-latency requirements of online e-commerce systems. To address this challenge, we propose CaLIR (Category-guided Latent Intent Reasoning), a category-guided latent intent reasoning framework for e-commerce generative retrieval. Rather than generating explicit textual rationales, CaLIR learns continuous latent intent states before SID decoding and uses product category hierarchies as a natural scaffold for coarse-to-fine intent reasoning. Specifically, we introduce hierarchical semantic reasoning to align latent states with category-level shopping intent, and query-wise reasoning enhancement to model diverse intent paths under multi-positive queries. CaLIR further combines a query-specific dynamic prefix trie, assembled from pre-indexed category-level tries, with reasoning-aware constrained decoding. Experiments on multilingual e-commerce search datasets show that CaLIR achieves a better balance between retrieval effectiveness and inference efficiency than existing methods, while also demonstrating transferability and robustness across induced hierarchies and different generative backbones.
Multi-Aspect Cross-modal Quantization for Generative Recommendation
Nov 19, 2025Generative Recommendation (GR) has emerged as a new paradigm in recommender systems. This approach relies on quantized representations to discretize item features, modeling users' historical interactions as sequences of discrete tokens. Based on these tokenized sequences, GR predicts the next item by employing next-token prediction methods. The challenges of GR lie in constructing high-quality semantic identifiers (IDs) that are hierarchically organized, minimally conflicting, and conducive to effective generative model training. However, current approaches remain limited in their ability to harness multimodal information and to capture the deep and intricate interactions among diverse modalities, both of which are essential for learning high-quality semantic IDs and for effectively training GR models. To address this, we propose Multi-Aspect Cross-modal quantization for generative Recommendation (MACRec), which introduces multimodal information and incorporates it into both semantic ID learning and generative model training from different aspects. Specifically, we first introduce cross-modal quantization during the ID learning process, which effectively reduces conflict rates and thus improves codebook usability through the complementary integration of multimodal information. In addition, to further enhance the generative ability of our GR model, we incorporate multi-aspect cross-modal alignments, including the implicit and explicit alignments. Finally, we conduct extensive experiments on three well-known recommendation datasets to demonstrate the effectiveness of our proposed method.
Large-Scale Multi-Domain Recommendation: an Automatic Domain Feature Extraction and Personalized Integration Framework
Apr 15, 2024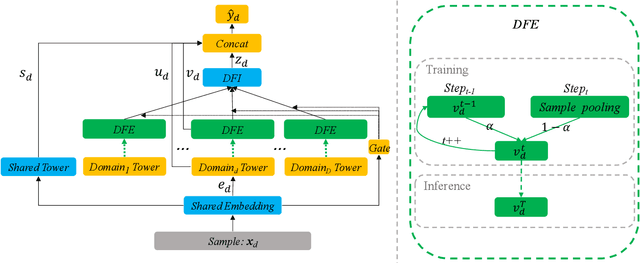

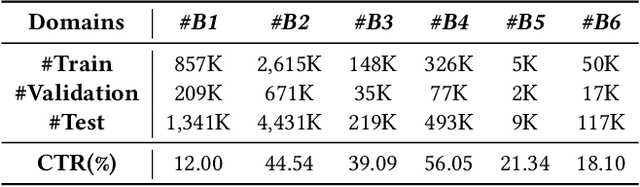
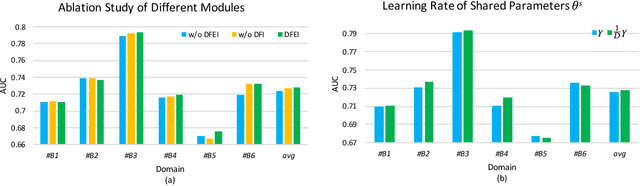
Feed recommendation is currently the mainstream mode for many real-world applications (e.g., TikTok, Dianping), it is usually necessary to model and predict user interests in multiple scenarios (domains) within and even outside the application. Multi-domain learning is a typical solution in this regard. While considerable efforts have been made in this regard, there are still two long-standing challenges: (1) Accurately depicting the differences among domains using domain features is crucial for enhancing the performance of each domain. However, manually designing domain features and models for numerous domains can be a laborious task. (2) Users typically have limited impressions in only a few domains. Extracting features automatically from other domains and leveraging them to improve the predictive capabilities of each domain has consistently posed a challenging problem. In this paper, we propose an Automatic Domain Feature Extraction and Personalized Integration (DFEI) framework for the large-scale multi-domain recommendation. The framework automatically transforms the behavior of each individual user into an aggregation of all user behaviors within the domain, which serves as the domain features. Unlike offline feature engineering methods, the extracted domain features are higher-order representations and directly related to the target label. Besides, by personalized integration of domain features from other domains for each user and the innovation in the training mode, the DFEI framework can yield more accurate conversion identification. Experimental results on both public and industrial datasets, consisting of over 20 domains, clearly demonstrate that the proposed framework achieves significantly better performance compared with SOTA baselines. Furthermore, we have released the source code of the proposed framework at https://github.com/xidongbo/DFEI.
Modeling Users' Behavior Sequences with Hierarchical Explainable Network for Cross-domain Fraud Detection
Jan 04, 2022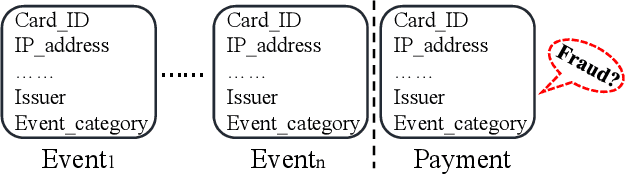
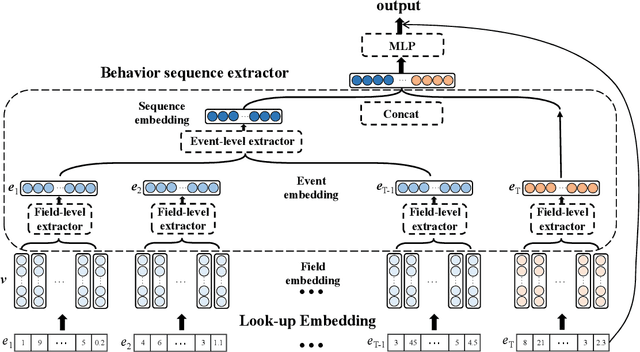
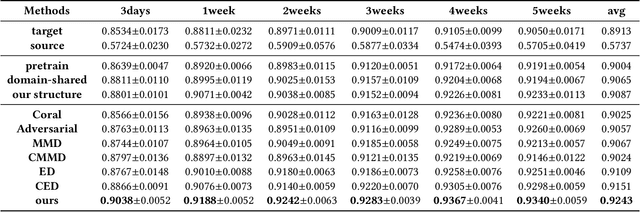
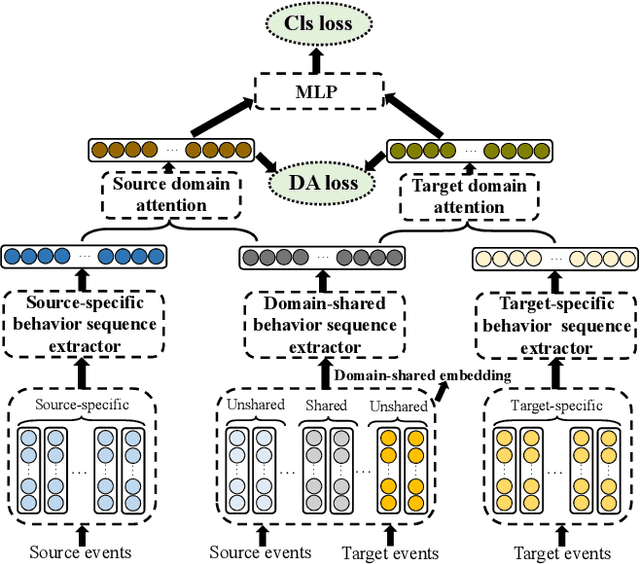
With the explosive growth of the e-commerce industry, detecting online transaction fraud in real-world applications has become increasingly important to the development of e-commerce platforms. The sequential behavior history of users provides useful information in differentiating fraudulent payments from regular ones. Recently, some approaches have been proposed to solve this sequence-based fraud detection problem. However, these methods usually suffer from two problems: the prediction results are difficult to explain and the exploitation of the internal information of behaviors is insufficient. To tackle the above two problems, we propose a Hierarchical Explainable Network (HEN) to model users' behavior sequences, which could not only improve the performance of fraud detection but also make the inference process interpretable. Meanwhile, as e-commerce business expands to new domains, e.g., new countries or new markets, one major problem for modeling user behavior in fraud detection systems is the limitation of data collection, e.g., very few data/labels available. Thus, in this paper, we further propose a transfer framework to tackle the cross-domain fraud detection problem, which aims to transfer knowledge from existing domains (source domains) with enough and mature data to improve the performance in the new domain (target domain). Our proposed method is a general transfer framework that could not only be applied upon HEN but also various existing models in the Embedding & MLP paradigm. Based on 90 transfer task experiments, we also demonstrate that our transfer framework could not only contribute to the cross-domain fraud detection task with HEN, but also be universal and expandable for various existing models.
Exploiting Bi-directional Global Transition Patterns and Personal Preferences for Missing POI Category Identification
Dec 31, 2021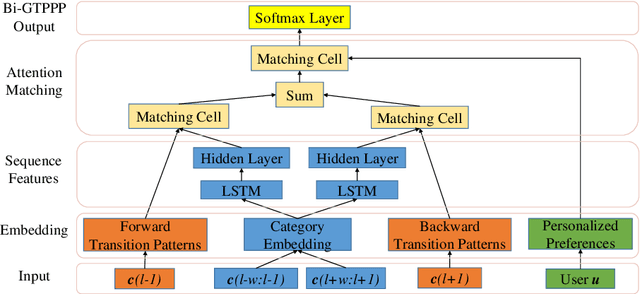

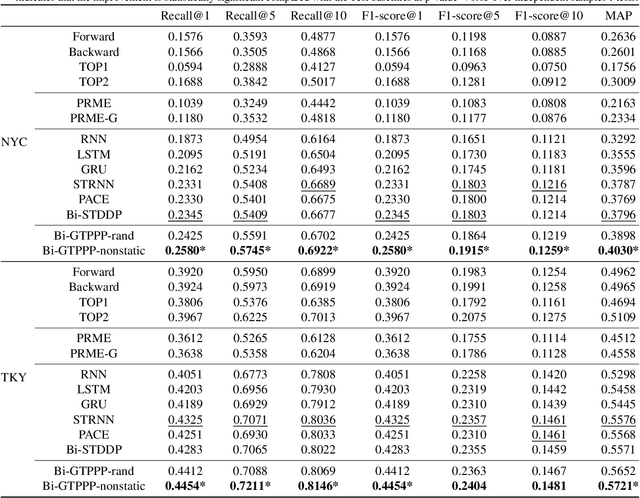
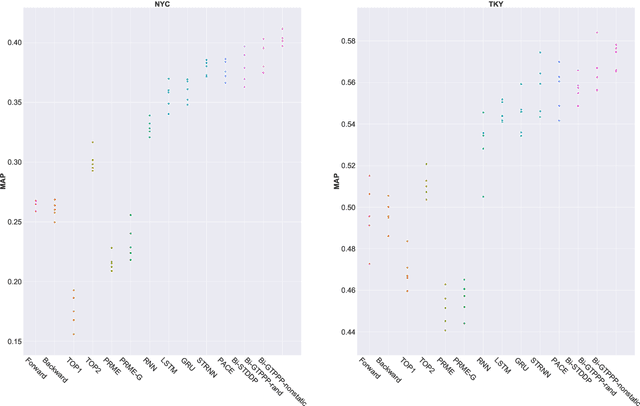
Recent years have witnessed the increasing popularity of Location-based Social Network (LBSN) services, which provides unparalleled opportunities to build personalized Point-of-Interest (POI) recommender systems. Existing POI recommendation and location prediction tasks utilize past information for future recommendation or prediction from a single direction perspective, while the missing POI category identification task needs to utilize the check-in information both before and after the missing category. Therefore, a long-standing challenge is how to effectively identify the missing POI categories at any time in the real-world check-in data of mobile users. To this end, in this paper, we propose a novel neural network approach to identify the missing POI categories by integrating both bi-directional global non-personal transition patterns and personal preferences of users. Specifically, we delicately design an attention matching cell to model how well the check-in category information matches their non-personal transition patterns and personal preferences. Finally, we evaluate our model on two real-world datasets, which clearly validate its effectiveness compared with the state-of-the-art baselines. Furthermore, our model can be naturally extended to address next POI category recommendation and prediction tasks with competitive performance.
Neural Hierarchical Factorization Machines for User's Event Sequence Analysis
Dec 31, 2021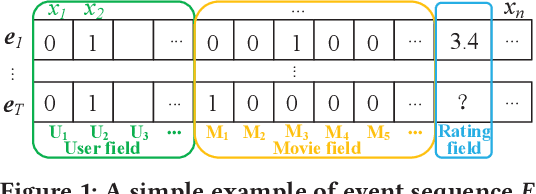
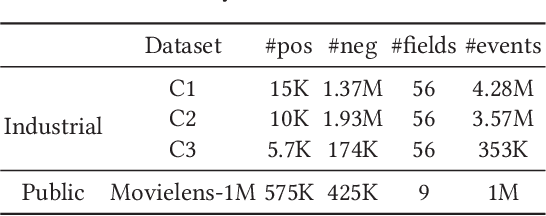
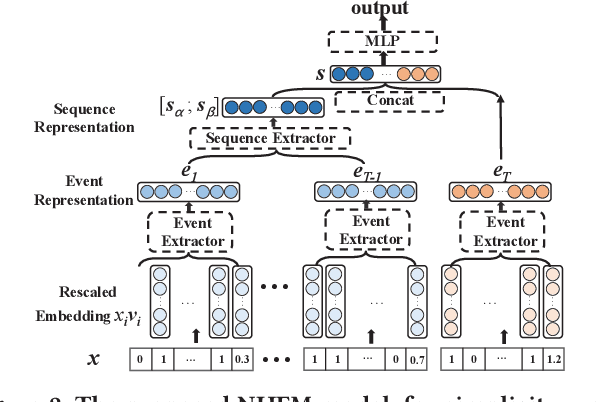
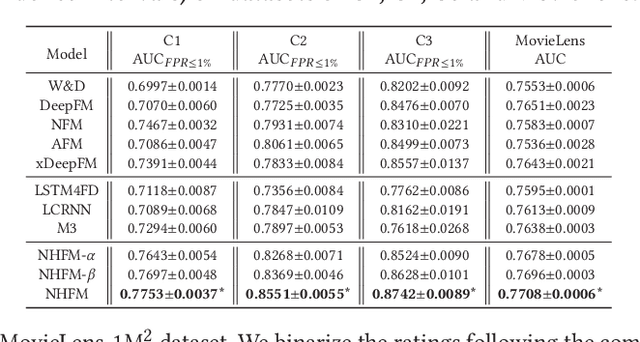
Many prediction tasks of real-world applications need to model multi-order feature interactions in user's event sequence for better detection performance. However, existing popular solutions usually suffer two key issues: 1) only focusing on feature interactions and failing to capture the sequence influence; 2) only focusing on sequence information, but ignoring internal feature relations of each event, thus failing to extract a better event representation. In this paper, we consider a two-level structure for capturing the hierarchical information over user's event sequence: 1) learning effective feature interactions based event representation; 2) modeling the sequence representation of user's historical events. Experimental results on both industrial and public datasets clearly demonstrate that our model achieves significantly better performance compared with state-of-the-art baselines.
Domain Adaptation with Category Attention Network for Deep Sentiment Analysis
Dec 31, 2021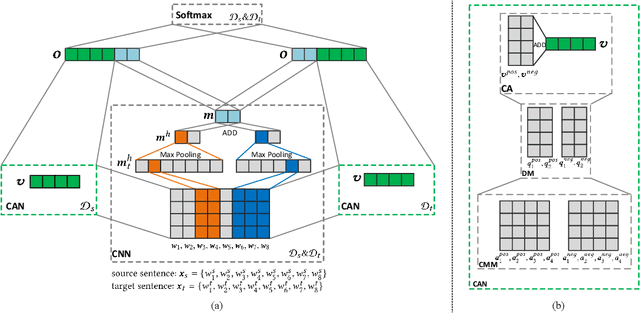
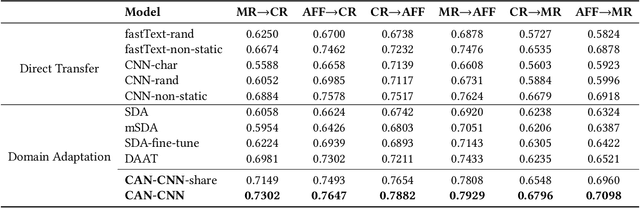
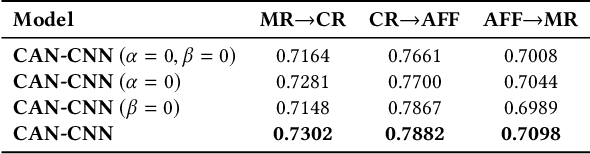
Domain adaptation tasks such as cross-domain sentiment classification aim to utilize existing labeled data in the source domain and unlabeled or few labeled data in the target domain to improve the performance in the target domain via reducing the shift between the data distributions. Existing cross-domain sentiment classification methods need to distinguish pivots, i.e., the domain-shared sentiment words, and non-pivots, i.e., the domain-specific sentiment words, for excellent adaptation performance. In this paper, we first design a Category Attention Network (CAN), and then propose a model named CAN-CNN to integrate CAN and a Convolutional Neural Network (CNN). On the one hand, the model regards pivots and non-pivots as unified category attribute words and can automatically capture them to improve the domain adaptation performance; on the other hand, the model makes an attempt at interpretability to learn the transferred category attribute words. Specifically, the optimization objective of our model has three different components: 1) the supervised classification loss; 2) the distributions loss of category feature weights; 3) the domain invariance loss. Finally, the proposed model is evaluated on three public sentiment analysis datasets and the results demonstrate that CAN-CNN can outperform other various baseline methods.
Modelling of Bi-directional Spatio-Temporal Dependence and Users' Dynamic Preferences for Missing POI Check-in Identification
Dec 31, 2021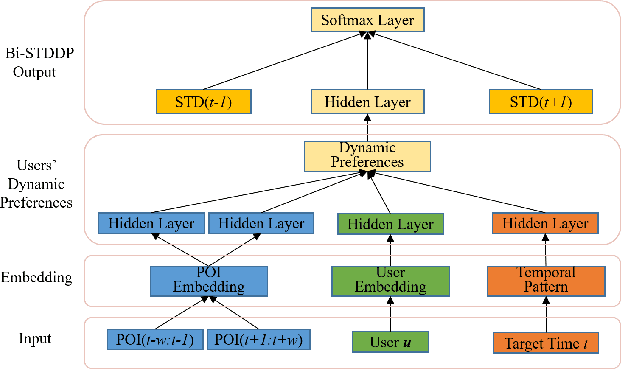
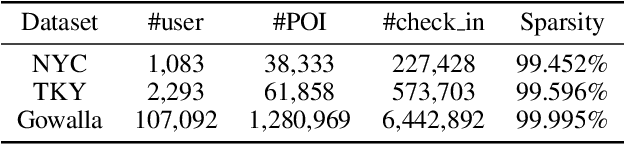

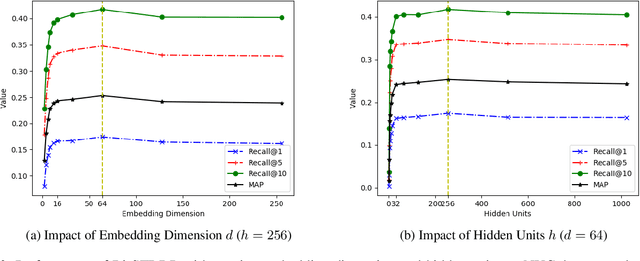
Human mobility data accumulated from Point-of-Interest (POI) check-ins provides great opportunity for user behavior understanding. However, data quality issues (e.g., geolocation information missing, unreal check-ins, data sparsity) in real-life mobility data limit the effectiveness of existing POI-oriented studies, e.g., POI recommendation and location prediction, when applied to real applications. To this end, in this paper, we develop a model, named Bi-STDDP, which can integrate bi-directional spatio-temporal dependence and users' dynamic preferences, to identify the missing POI check-in where a user has visited at a specific time. Specifically, we first utilize bi-directional global spatial and local temporal information of POIs to capture the complex dependence relationships. Then, target temporal pattern in combination with user and POI information are fed into a multi-layer network to capture users' dynamic preferences. Moreover, the dynamic preferences are transformed into the same space as the dependence relationships to form the final model. Finally, the proposed model is evaluated on three large-scale real-world datasets and the results demonstrate significant improvements of our model compared with state-of-the-art methods. Also, it is worth noting that the proposed model can be naturally extended to address POI recommendation and location prediction tasks with competitive performances.
Modeling the Sequential Dependence among Audience Multi-step Conversions with Multi-task Learning in Targeted Display Advertising
May 24, 2021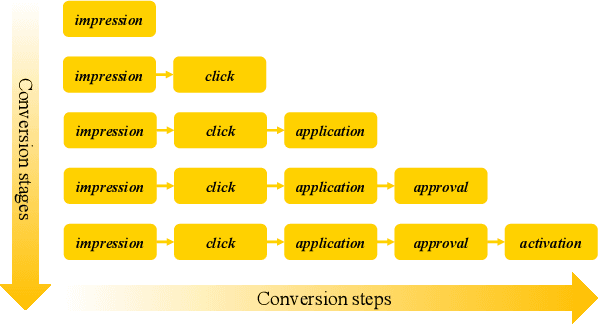

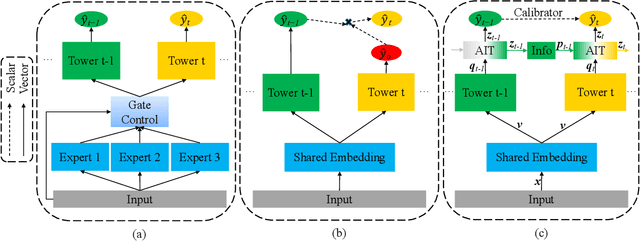
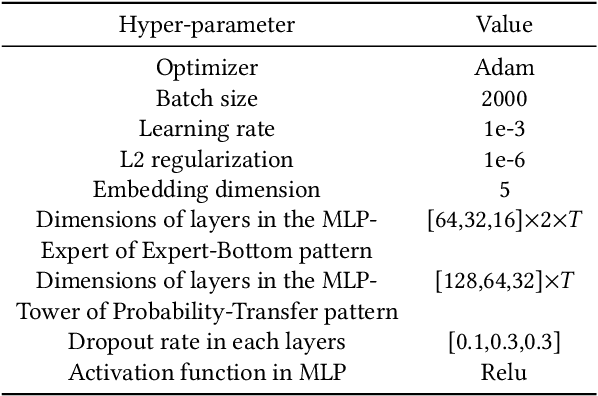
In most real-world large-scale online applications (e.g., e-commerce or finance), customer acquisition is usually a multi-step conversion process of audiences. For example, an impression->click->purchase process is usually performed of audiences for e-commerce platforms. However, it is more difficult to acquire customers in financial advertising (e.g., credit card advertising) than in traditional advertising. On the one hand, the audience multi-step conversion path is longer. On the other hand, the positive feedback is sparser (class imbalance) step by step, and it is difficult to obtain the final positive feedback due to the delayed feedback of activation. Multi-task learning is a typical solution in this direction. While considerable multi-task efforts have been made in this direction, a long-standing challenge is how to explicitly model the long-path sequential dependence among audience multi-step conversions for improving the end-to-end conversion. In this paper, we propose an Adaptive Information Transfer Multi-task (AITM) framework, which models the sequential dependence among audience multi-step conversions via the Adaptive Information Transfer (AIT) module. The AIT module can adaptively learn what and how much information to transfer for different conversion stages. Besides, by combining the Behavioral Expectation Calibrator in the loss function, the AITM framework can yield more accurate end-to-end conversion identification. The proposed framework is deployed in Meituan app, which utilizes it to real-timely show a banner to the audience with a high end-to-end conversion rate for Meituan Co-Branded Credit Cards. Offline experimental results on both industrial and public real-world datasets clearly demonstrate that the proposed framework achieves significantly better performance compared with state-of-the-art baselines.
Transfer-Meta Framework for Cross-domain Recommendation to Cold-Start Users
May 11, 2021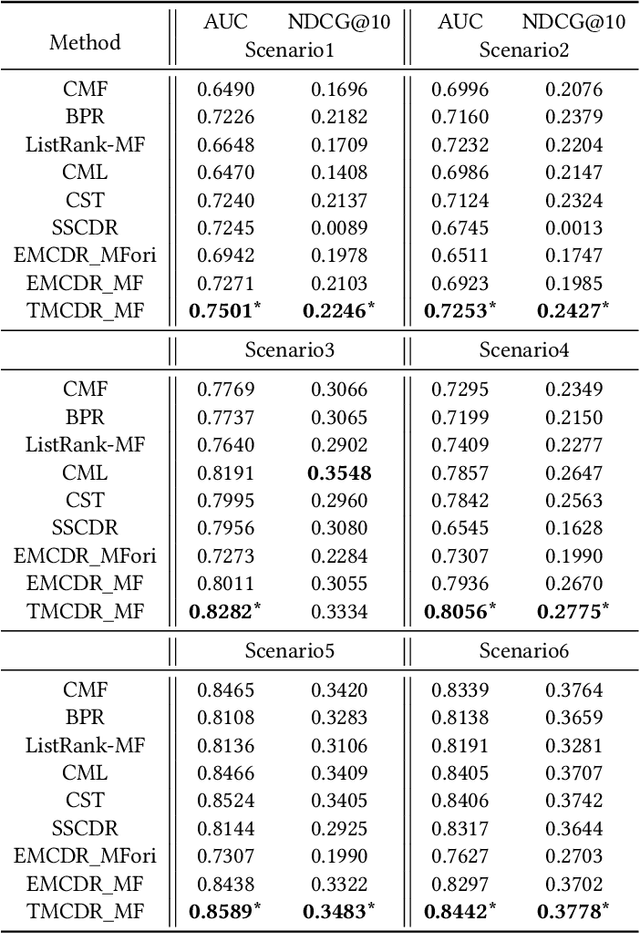
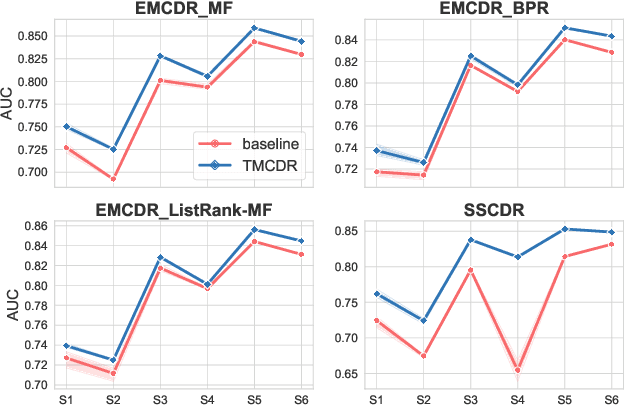
Cold-start problems are enormous challenges in practical recommender systems. One promising solution for this problem is cross-domain recommendation (CDR) which leverages rich information from an auxiliary (source) domain to improve the performance of recommender system in the target domain. In these CDR approaches, the family of Embedding and Mapping methods for CDR (EMCDR) is very effective, which explicitly learn a mapping function from source embeddings to target embeddings with overlapping users. However, these approaches suffer from one serious problem: the mapping function is only learned on limited overlapping users, and the function would be biased to the limited overlapping users, which leads to unsatisfying generalization ability and degrades the performance on cold-start users in the target domain. With the advantage of meta learning which has good generalization ability to novel tasks, we propose a transfer-meta framework for CDR (TMCDR) which has a transfer stage and a meta stage. In the transfer (pre-training) stage, a source model and a target model are trained on source and target domains, respectively. In the meta stage, a task-oriented meta network is learned to implicitly transform the user embedding in the source domain to the target feature space. In addition, the TMCDR is a general framework that can be applied upon various base models, e.g., MF, BPR, CML. By utilizing data from Amazon and Douban, we conduct extensive experiments on 6 cross-domain tasks to demonstrate the superior performance and compatibility of TMCDR.