 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDarwinian Memory: A Training-Free Self-Regulating Memory System for GUI Agent Evolution
Jan 30, 2026Multimodal Large Language Model (MLLM) agents facilitate Graphical User Interface (GUI) automation but struggle with long-horizon, cross-application tasks due to limited context windows. While memory systems provide a viable solution, existing paradigms struggle to adapt to dynamic GUI environments, suffering from a granularity mismatch between high-level intent and low-level execution, and context pollution where the static accumulation of outdated experiences drives agents into hallucination. To address these bottlenecks, we propose the Darwinian Memory System (DMS), a self-evolving architecture that constructs memory as a dynamic ecosystem governed by the law of survival of the fittest. DMS decomposes complex trajectories into independent, reusable units for compositional flexibility, and implements Utility-driven Natural Selection to track survival value, actively pruning suboptimal paths and inhibiting high-risk plans. This evolutionary pressure compels the agent to derive superior strategies. Extensive experiments on real-world multi-app benchmarks validate that DMS boosts general-purpose MLLMs without training costs or architectural overhead, achieving average gains of 18.0% in success rate and 33.9% in execution stability, while reducing task latency, establishing it as an effective self-evolving memory system for GUI tasks.
AMD-Hummingbird: Towards an Efficient Text-to-Video Model
Mar 25, 2025Text-to-Video (T2V) generation has attracted significant attention for its ability to synthesize realistic videos from textual descriptions. However, existing models struggle to balance computational efficiency and high visual quality, particularly on resource-limited devices, e.g.,iGPUs and mobile phones. Most prior work prioritizes visual fidelity while overlooking the need for smaller, more efficient models suitable for real-world deployment. To address this challenge, we propose a lightweight T2V framework, termed Hummingbird, which prunes existing models and enhances visual quality through visual feedback learning. Our approach reduces the size of the U-Net from 1.4 billion to 0.7 billion parameters, significantly improving efficiency while preserving high-quality video generation. Additionally, we introduce a novel data processing pipeline that leverages Large Language Models (LLMs) and Video Quality Assessment (VQA) models to enhance the quality of both text prompts and video data. To support user-driven training and style customization, we publicly release the full training code, including data processing and model training. Extensive experiments show that our method achieves a 31X speedup compared to state-of-the-art models such as VideoCrafter2, while also attaining the highest overall score on VBench. Moreover, our method supports the generation of videos with up to 26 frames, addressing the limitations of existing U-Net-based methods in long video generation. Notably, the entire training process requires only four GPUs, yet delivers performance competitive with existing leading methods. Hummingbird presents a practical and efficient solution for T2V generation, combining high performance, scalability, and flexibility for real-world applications.
Large-Scale Multi-Domain Recommendation: an Automatic Domain Feature Extraction and Personalized Integration Framework
Apr 15, 2024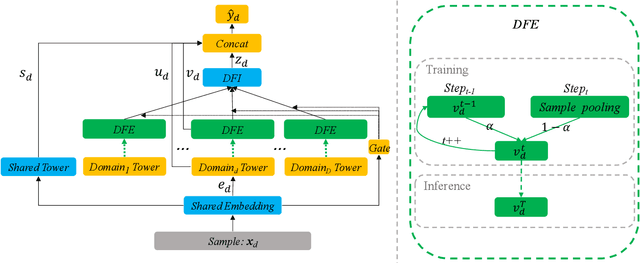

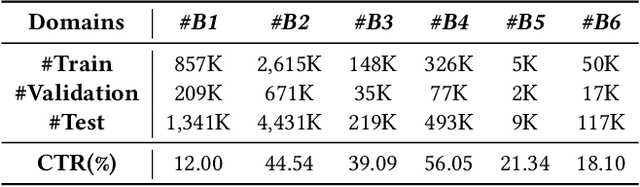
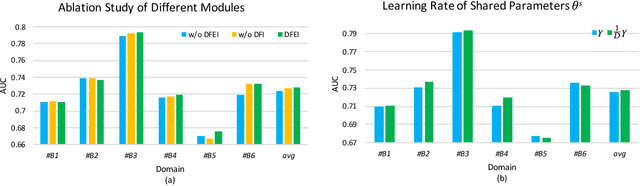
Feed recommendation is currently the mainstream mode for many real-world applications (e.g., TikTok, Dianping), it is usually necessary to model and predict user interests in multiple scenarios (domains) within and even outside the application. Multi-domain learning is a typical solution in this regard. While considerable efforts have been made in this regard, there are still two long-standing challenges: (1) Accurately depicting the differences among domains using domain features is crucial for enhancing the performance of each domain. However, manually designing domain features and models for numerous domains can be a laborious task. (2) Users typically have limited impressions in only a few domains. Extracting features automatically from other domains and leveraging them to improve the predictive capabilities of each domain has consistently posed a challenging problem. In this paper, we propose an Automatic Domain Feature Extraction and Personalized Integration (DFEI) framework for the large-scale multi-domain recommendation. The framework automatically transforms the behavior of each individual user into an aggregation of all user behaviors within the domain, which serves as the domain features. Unlike offline feature engineering methods, the extracted domain features are higher-order representations and directly related to the target label. Besides, by personalized integration of domain features from other domains for each user and the innovation in the training mode, the DFEI framework can yield more accurate conversion identification. Experimental results on both public and industrial datasets, consisting of over 20 domains, clearly demonstrate that the proposed framework achieves significantly better performance compared with SOTA baselines. Furthermore, we have released the source code of the proposed framework at https://github.com/xidongbo/DFEI.