 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgo-InBetween: Generating Object State Transitions in Ego-Centric Videos
Apr 20, 2026Understanding physical transformation processes is crucial for both human cognition and artificial intelligence systems, particularly from an egocentric perspective, which serves as a key bridge between humans and machines in action modeling. We define this modeling process as Egocentric Instructed Visual State Transition (EIVST), which involves generating intermediate frames that depict object transformations between initial and target states under a brief action instruction. EIVST poses two challenges for current generative models: (1) understanding the visual scenes of the initial and target states and reasoning about transformation steps from an egocentric view, and (2) generating a consistent intermediate transition that follows the given instruction while preserving object appearance across the two visual states. To address these challenges, we propose the EgoIn framework. It first infers the multi-step transition process between two given states using TransitionVLM, fine-tuned on our curated dataset to better adapt to this task and reduce hallucinated information. It then generates a sequence of frames based on transition conditions produced by the proposed Transition Conditioning module. Additionally, we introduce Object-aware Auxiliary Supervision to preserve consistent object appearance throughout the transition. Extensive experiments on human-object and robot-object interaction datasets demonstrate EgoIn's superior performance in generating semantically meaningful and visually coherent transformation sequences.
AMD-Hummingbird: Towards an Efficient Text-to-Video Model
Mar 25, 2025Text-to-Video (T2V) generation has attracted significant attention for its ability to synthesize realistic videos from textual descriptions. However, existing models struggle to balance computational efficiency and high visual quality, particularly on resource-limited devices, e.g.,iGPUs and mobile phones. Most prior work prioritizes visual fidelity while overlooking the need for smaller, more efficient models suitable for real-world deployment. To address this challenge, we propose a lightweight T2V framework, termed Hummingbird, which prunes existing models and enhances visual quality through visual feedback learning. Our approach reduces the size of the U-Net from 1.4 billion to 0.7 billion parameters, significantly improving efficiency while preserving high-quality video generation. Additionally, we introduce a novel data processing pipeline that leverages Large Language Models (LLMs) and Video Quality Assessment (VQA) models to enhance the quality of both text prompts and video data. To support user-driven training and style customization, we publicly release the full training code, including data processing and model training. Extensive experiments show that our method achieves a 31X speedup compared to state-of-the-art models such as VideoCrafter2, while also attaining the highest overall score on VBench. Moreover, our method supports the generation of videos with up to 26 frames, addressing the limitations of existing U-Net-based methods in long video generation. Notably, the entire training process requires only four GPUs, yet delivers performance competitive with existing leading methods. Hummingbird presents a practical and efficient solution for T2V generation, combining high performance, scalability, and flexibility for real-world applications.
MoTrans: Customized Motion Transfer with Text-driven Video Diffusion Models
Dec 02, 2024



Existing pretrained text-to-video (T2V) models have demonstrated impressive abilities in generating realistic videos with basic motion or camera movement. However, these models exhibit significant limitations when generating intricate, human-centric motions. Current efforts primarily focus on fine-tuning models on a small set of videos containing a specific motion. They often fail to effectively decouple motion and the appearance in the limited reference videos, thereby weakening the modeling capability of motion patterns. To this end, we propose MoTrans, a customized motion transfer method enabling video generation of similar motion in new context. Specifically, we introduce a multimodal large language model (MLLM)-based recaptioner to expand the initial prompt to focus more on appearance and an appearance injection module to adapt appearance prior from video frames to the motion modeling process. These complementary multimodal representations from recaptioned prompt and video frames promote the modeling of appearance and facilitate the decoupling of appearance and motion. In addition, we devise a motion-specific embedding for further enhancing the modeling of the specific motion. Experimental results demonstrate that our method effectively learns specific motion pattern from singular or multiple reference videos, performing favorably against existing methods in customized video generation.
Self-supervised 3D Semantic Representation Learning for Vision-and-Language Navigation
Jan 26, 2022



In the Vision-and-Language Navigation task, the embodied agent follows linguistic instructions and navigates to a specific goal. It is important in many practical scenarios and has attracted extensive attention from both computer vision and robotics communities. However, most existing works only use RGB images but neglect the 3D semantic information of the scene. To this end, we develop a novel self-supervised training framework to encode the voxel-level 3D semantic reconstruction into a 3D semantic representation. Specifically, a region query task is designed as the pretext task, which predicts the presence or absence of objects of a particular class in a specific 3D region. Then, we construct an LSTM-based navigation model and train it with the proposed 3D semantic representations and BERT language features on vision-language pairs. Experiments show that the proposed approach achieves success rates of 68% and 66% on the validation unseen and test unseen splits of the R2R dataset respectively, which are superior to most of RGB-based methods utilizing vision-language transformers.
Knowledge-based Embodied Question Answering
Sep 16, 2021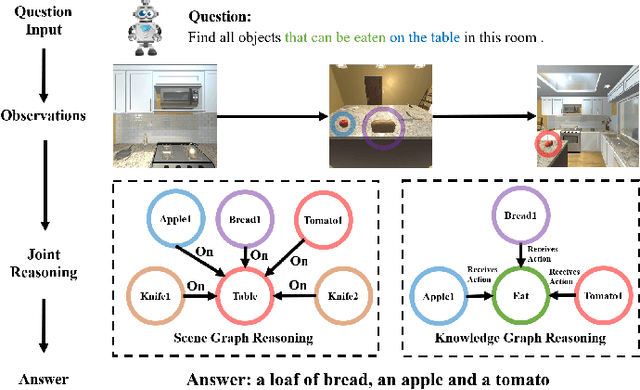


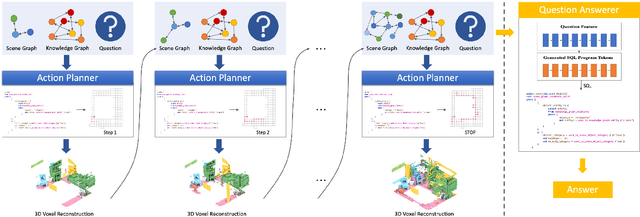
In this paper, we propose a novel Knowledge-based Embodied Question Answering (K-EQA) task, in which the agent intelligently explores the environment to answer various questions with the knowledge. Different from explicitly specifying the target object in the question as existing EQA work, the agent can resort to external knowledge to understand more complicated question such as "Please tell me what are objects used to cut food in the room?", in which the agent must know the knowledge such as "knife is used for cutting food". To address this K-EQA problem, a novel framework based on neural program synthesis reasoning is proposed, where the joint reasoning of the external knowledge and 3D scene graph is performed to realize navigation and question answering. Especially, the 3D scene graph can provide the memory to store the visual information of visited scenes, which significantly improves the efficiency for the multi-turn question answering. Experimental results have demonstrated that the proposed framework is capable of answering more complicated and realistic questions in the embodied environment. The proposed method is also applicable to multi-agent scenarios.
Automated Security Assessment for the Internet of Things
Sep 09, 2021
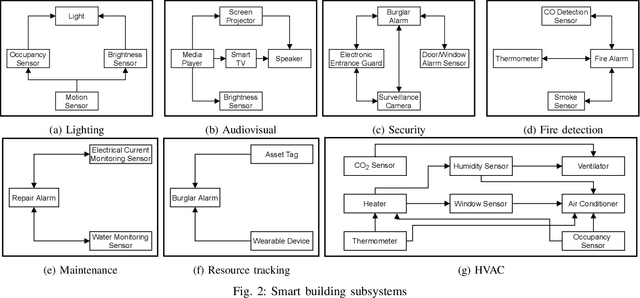
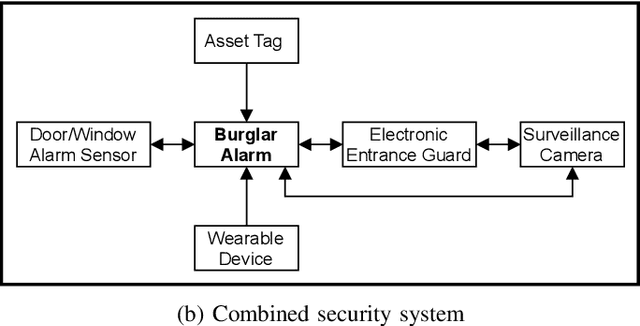
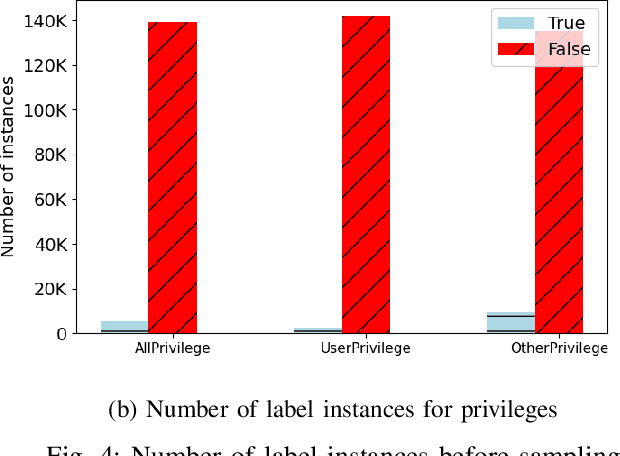
Internet of Things (IoT) based applications face an increasing number of potential security risks, which need to be systematically assessed and addressed. Expert-based manual assessment of IoT security is a predominant approach, which is usually inefficient. To address this problem, we propose an automated security assessment framework for IoT networks. Our framework first leverages machine learning and natural language processing to analyze vulnerability descriptions for predicting vulnerability metrics. The predicted metrics are then input into a two-layered graphical security model, which consists of an attack graph at the upper layer to present the network connectivity and an attack tree for each node in the network at the bottom layer to depict the vulnerability information. This security model automatically assesses the security of the IoT network by capturing potential attack paths. We evaluate the viability of our approach using a proof-of-concept smart building system model which contains a variety of real-world IoT devices and potential vulnerabilities. Our evaluation of the proposed framework demonstrates its effectiveness in terms of automatically predicting the vulnerability metrics of new vulnerabilities with more than 90% accuracy, on average, and identifying the most vulnerable attack paths within an IoT network. The produced assessment results can serve as a guideline for cybersecurity professionals to take further actions and mitigate risks in a timely manner.