 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV2X-DSC: Multi-Agent Collaborative Perception with Distributed Source Coding Guided Communication
Jan 31, 2026Collaborative perception improves 3D understanding by fusing multi-agent observations, yet intermediate-feature sharing faces strict bandwidth constraints as dense BEV features saturate V2X links. We observe that collaborators view the same physical world, making their features strongly correlated; thus receivers only need innovation beyond their local context. Revisiting this from a distributed source coding perspective, we propose V2X-DSC, a framework with a Conditional Codec (DCC) for bandwidth-constrained fusion. The sender compresses BEV features into compact codes, while the receiver performs conditional reconstruction using its local features as side information, allocating bits to complementary cues rather than redundant content. This conditional structure regularizes learning, encouraging incremental representation and yielding lower-noise features. Experiments on DAIR-V2X, OPV2V, and V2X-Real demonstrate state-of-the-art accuracy-bandwidth trade-offs under KB-level communication, and generalizes as a plug-and-play communication layer across multiple fusion backbones.
From Observations to Events: Event-Aware World Model for Reinforcement Learning
Jan 27, 2026While model-based reinforcement learning (MBRL) improves sample efficiency by learning world models from raw observations, existing methods struggle to generalize across structurally similar scenes and remain vulnerable to spurious variations such as textures or color shifts. From a cognitive science perspective, humans segment continuous sensory streams into discrete events and rely on these key events for decision-making. Motivated by this principle, we propose the Event-Aware World Model (EAWM), a general framework that learns event-aware representations to streamline policy learning without requiring handcrafted labels. EAWM employs an automated event generator to derive events from raw observations and introduces a Generic Event Segmentor (GES) to identify event boundaries, which mark the start and end time of event segments. Through event prediction, the representation space is shaped to capture meaningful spatio-temporal transitions. Beyond this, we present a unified formulation of seemingly distinct world model architectures and show the broad applicability of our methods. Experiments on Atari 100K, Craftax 1M, and DeepMind Control 500K, DMC-GB2 500K demonstrate that EAWM consistently boosts the performance of strong MBRL baselines by 10%-45%, setting new state-of-the-art results across benchmarks. Our code is released at https://github.com/MarquisDarwin/EAWM.
Towards Cross-Platform Generalization: Domain Adaptive 3D Detection with Augmentation and Pseudo-Labeling
Jan 13, 2026This technical report represents the award-winning solution to the Cross-platform 3D Object Detection task in the RoboSense2025 Challenge. Our approach is built upon PVRCNN++, an efficient 3D object detection framework that effectively integrates point-based and voxel-based features. On top of this foundation, we improve cross-platform generalization by narrowing domain gaps through tailored data augmentation and a self-training strategy with pseudo-labels. These enhancements enabled our approach to secure the 3rd place in the challenge, achieving a 3D AP of 62.67% for the Car category on the phase-1 target domain, and 58.76% and 49.81% for Car and Pedestrian categories respectively on the phase-2 target domain.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Plug-and-Play Clarifier: A Zero-Shot Multimodal Framework for Egocentric Intent Disambiguation
Nov 12, 2025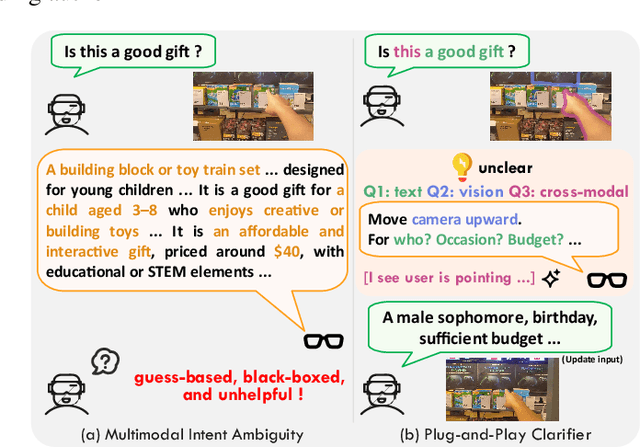
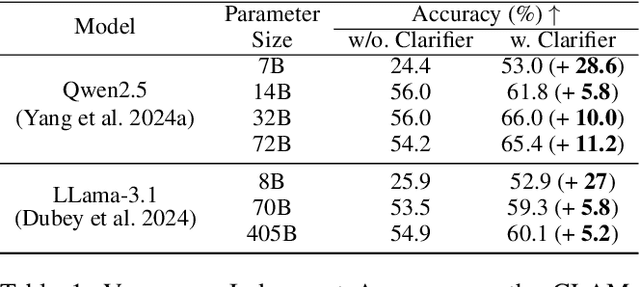
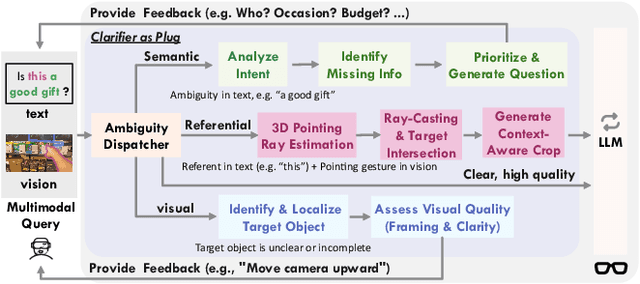
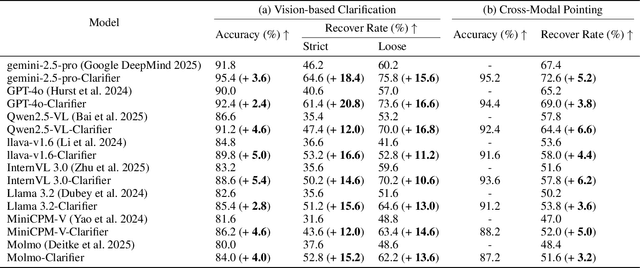
The performance of egocentric AI agents is fundamentally limited by multimodal intent ambiguity. This challenge arises from a combination of underspecified language, imperfect visual data, and deictic gestures, which frequently leads to task failure. Existing monolithic Vision-Language Models (VLMs) struggle to resolve these multimodal ambiguous inputs, often failing silently or hallucinating responses. To address these ambiguities, we introduce the Plug-and-Play Clarifier, a zero-shot and modular framework that decomposes the problem into discrete, solvable sub-tasks. Specifically, our framework consists of three synergistic modules: (1) a text clarifier that uses dialogue-driven reasoning to interactively disambiguate linguistic intent, (2) a vision clarifier that delivers real-time guidance feedback, instructing users to adjust their positioning for improved capture quality, and (3) a cross-modal clarifier with grounding mechanism that robustly interprets 3D pointing gestures and identifies the specific objects users are pointing to. Extensive experiments demonstrate that our framework improves the intent clarification performance of small language models (4--8B) by approximately 30%, making them competitive with significantly larger counterparts. We also observe consistent gains when applying our framework to these larger models. Furthermore, our vision clarifier increases corrective guidance accuracy by over 20%, and our cross-modal clarifier improves semantic answer accuracy for referential grounding by 5%. Overall, our method provides a plug-and-play framework that effectively resolves multimodal ambiguity and significantly enhances user experience in egocentric interaction.
A Survey of Multi-sensor Fusion Perception for Embodied AI: Background, Methods, Challenges and Prospects
Jun 24, 2025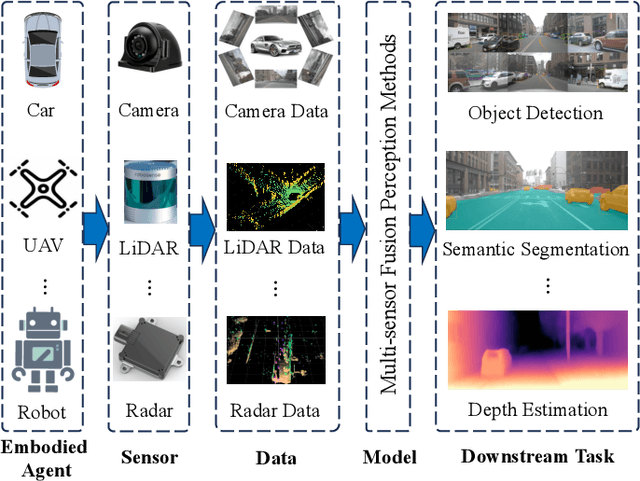
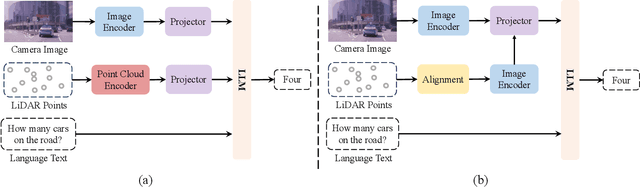
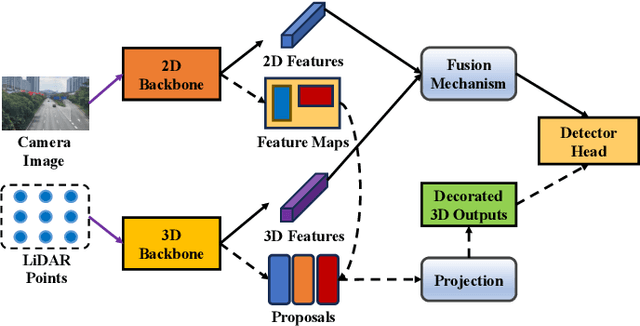
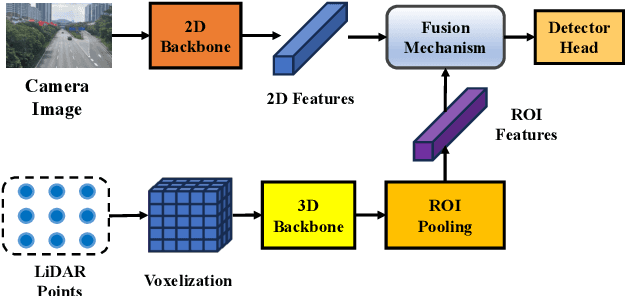
Multi-sensor fusion perception (MSFP) is a key technology for embodied AI, which can serve a variety of downstream tasks (e.g., 3D object detection and semantic segmentation) and application scenarios (e.g., autonomous driving and swarm robotics). Recently, impressive achievements on AI-based MSFP methods have been reviewed in relevant surveys. However, we observe that the existing surveys have some limitations after a rigorous and detailed investigation. For one thing, most surveys are oriented to a single task or research field, such as 3D object detection or autonomous driving. Therefore, researchers in other related tasks often find it difficult to benefit directly. For another, most surveys only introduce MSFP from a single perspective of multi-modal fusion, while lacking consideration of the diversity of MSFP methods, such as multi-view fusion and time-series fusion. To this end, in this paper, we hope to organize MSFP research from a task-agnostic perspective, where methods are reported from various technical views. Specifically, we first introduce the background of MSFP. Next, we review multi-modal and multi-agent fusion methods. A step further, time-series fusion methods are analyzed. In the era of LLM, we also investigate multimodal LLM fusion methods. Finally, we discuss open challenges and future directions for MSFP. We hope this survey can help researchers understand the important progress in MSFP and provide possible insights for future research.
EffOWT: Transfer Visual Language Models to Open-World Tracking Efficiently and Effectively
Apr 09, 2025Open-World Tracking (OWT) aims to track every object of any category, which requires the model to have strong generalization capabilities. Trackers can improve their generalization ability by leveraging Visual Language Models (VLMs). However, challenges arise with the fine-tuning strategies when VLMs are transferred to OWT: full fine-tuning results in excessive parameter and memory costs, while the zero-shot strategy leads to sub-optimal performance. To solve the problem, EffOWT is proposed for efficiently transferring VLMs to OWT. Specifically, we build a small and independent learnable side network outside the VLM backbone. By freezing the backbone and only executing backpropagation on the side network, the model's efficiency requirements can be met. In addition, EffOWT enhances the side network by proposing a hybrid structure of Transformer and CNN to improve the model's performance in the OWT field. Finally, we implement sparse interactions on the MLP, thus reducing parameter updates and memory costs significantly. Thanks to the proposed methods, EffOWT achieves an absolute gain of 5.5% on the tracking metric OWTA for unknown categories, while only updating 1.3% of the parameters compared to full fine-tuning, with a 36.4% memory saving. Other metrics also demonstrate obvious improvement.
ReNeg: Learning Negative Embedding with Reward Guidance
Dec 27, 2024In text-to-image (T2I) generation applications, negative embeddings have proven to be a simple yet effective approach for enhancing generation quality. Typically, these negative embeddings are derived from user-defined negative prompts, which, while being functional, are not necessarily optimal. In this paper, we introduce ReNeg, an end-to-end method designed to learn improved Negative embeddings guided by a Reward model. We employ a reward feedback learning framework and integrate classifier-free guidance (CFG) into the training process, which was previously utilized only during inference, thus enabling the effective learning of negative embeddings. We also propose two strategies for learning both global and per-sample negative embeddings. Extensive experiments show that the learned negative embedding significantly outperforms null-text and handcrafted counterparts, achieving substantial improvements in human preference alignment. Additionally, the negative embedding learned within the same text embedding space exhibits strong generalization capabilities. For example, using the same CLIP text encoder, the negative embedding learned on SD1.5 can be seamlessly transferred to text-to-image or even text-to-video models such as ControlNet, ZeroScope, and VideoCrafter2, resulting in consistent performance improvements across the board.
GaLore$+$: Boosting Low-Rank Adaptation for LLMs with Cross-Head Projection
Dec 15, 2024



Recent low-rank training methods, such as GaLore, have significantly reduced the memory required to optimize large language models (LLMs). However, these methods often suffer from time-consuming low-rank projection estimations. In particular, the singular value decomposition (SVD) in GaLore can consume more than 80\% of the total training time. To address this issue, we propose GaLore$+$, which uses cross-head low-rank projection to reduce the substantial time consumption in estimating low-rank projections for multi-head attention. In addition, we employ randomized subspace iteration to achieve fast SVD. To further enhance performance, we propose sparsely coded residuals to reduce the errors caused by low-rank approximation on the first- and second-order moments of the optimizers and weight updates. We evaluate GaLore$+$ on arithmetic reasoning and natural language generation datasets. Our experiments demonstrate that GaLore$+$ delivers superior performance while achieving approximately $4\times$ fine-tuning speed compared to vanilla GaLore.
MoTrans: Customized Motion Transfer with Text-driven Video Diffusion Models
Dec 02, 2024



Existing pretrained text-to-video (T2V) models have demonstrated impressive abilities in generating realistic videos with basic motion or camera movement. However, these models exhibit significant limitations when generating intricate, human-centric motions. Current efforts primarily focus on fine-tuning models on a small set of videos containing a specific motion. They often fail to effectively decouple motion and the appearance in the limited reference videos, thereby weakening the modeling capability of motion patterns. To this end, we propose MoTrans, a customized motion transfer method enabling video generation of similar motion in new context. Specifically, we introduce a multimodal large language model (MLLM)-based recaptioner to expand the initial prompt to focus more on appearance and an appearance injection module to adapt appearance prior from video frames to the motion modeling process. These complementary multimodal representations from recaptioned prompt and video frames promote the modeling of appearance and facilitate the decoupling of appearance and motion. In addition, we devise a motion-specific embedding for further enhancing the modeling of the specific motion. Experimental results demonstrate that our method effectively learns specific motion pattern from singular or multiple reference videos, performing favorably against existing methods in customized video generation.