 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLRT-Based Metric Learning for Remote Sensing Object Retrieval
Oct 08, 2024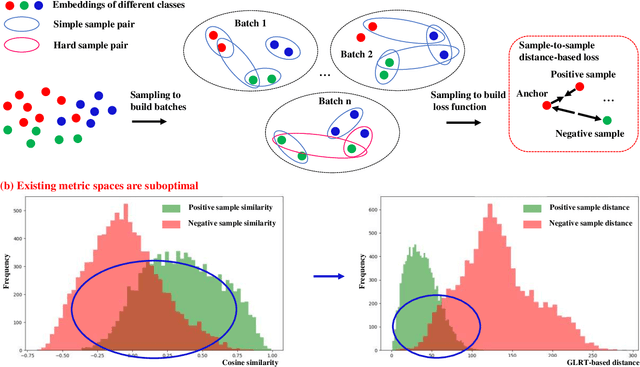
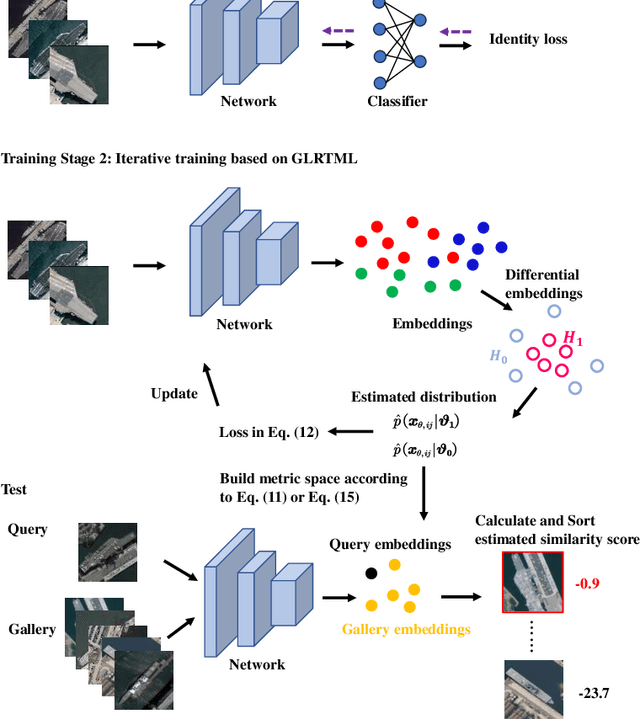
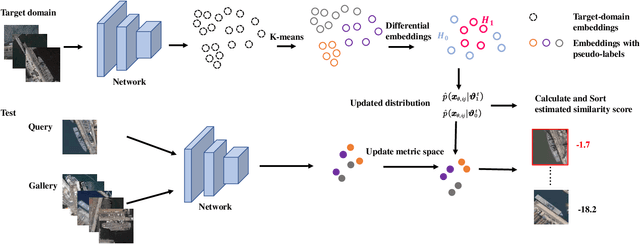
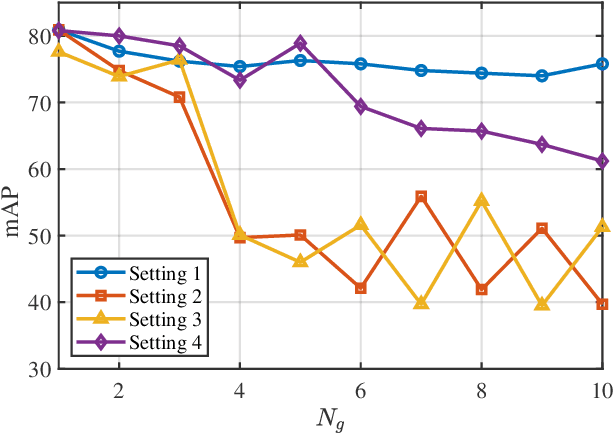
With the improvement in the quantity and quality of remote sensing images, content-based remote sensing object retrieval (CBRSOR) has become an increasingly important topic. However, existing CBRSOR methods neglect the utilization of global statistical information during both training and test stages, which leads to the overfitting of neural networks to simple sample pairs of samples during training and suboptimal metric performance. Inspired by the Neyman-Pearson theorem, we propose a generalized likelihood ratio test-based metric learning (GLRTML) approach, which can estimate the relative difficulty of sample pairs by incorporating global data distribution information during training and test phases. This guides the network to focus more on difficult samples during the training process, thereby encourages the network to learn more discriminative feature embeddings. In addition, GLRT is a more effective than traditional metric space due to the utilization of global data distribution information. Accurately estimating the distribution of embeddings is critical for GLRTML. However, in real-world applications, there is often a distribution shift between the training and target domains, which diminishes the effectiveness of directly using the distribution estimated on training data. To address this issue, we propose the clustering pseudo-labels-based fast parameter adaptation (CPLFPA) method. CPLFPA efficiently estimates the distribution of embeddings in the target domain by clustering target domain instances and re-estimating the distribution parameters for GLRTML. We reorganize datasets for CBRSOR tasks based on fine-grained ship remote sensing image slices (FGSRSI-23) and military aircraft recognition (MAR20) datasets. Extensive experiments on these datasets demonstrate the effectiveness of our proposed GLRTML and CPLFPA.