 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised dense retrieval with conterfactual contrastive learning
Dec 30, 2024Efficiently retrieving a concise set of candidates from a large document corpus remains a pivotal challenge in Information Retrieval (IR). Neural retrieval models, particularly dense retrieval models built with transformers and pretrained language models, have been popular due to their superior performance. However, criticisms have also been raised on their lack of explainability and vulnerability to adversarial attacks. In response to these challenges, we propose to improve the robustness of dense retrieval models by enhancing their sensitivity of fine-graned relevance signals. A model achieving sensitivity in this context should exhibit high variances when documents' key passages determining their relevance to queries have been modified, while maintaining low variances for other changes in irrelevant passages. This sensitivity allows a dense retrieval model to produce robust results with respect to attacks that try to promote documents without actually increasing their relevance. It also makes it possible to analyze which part of a document is actually relevant to a query, and thus improve the explainability of the retrieval model. Motivated by causality and counterfactual analysis, we propose a series of counterfactual regularization methods based on game theory and unsupervised learning with counterfactual passages. Experiments show that, our method can extract key passages without reliance on the passage-level relevance annotations. Moreover, the regularized dense retrieval models exhibit heightened robustness against adversarial attacks, surpassing the state-of-the-art anti-attack methods.
Domain Adaptation with Category Attention Network for Deep Sentiment Analysis
Dec 31, 2021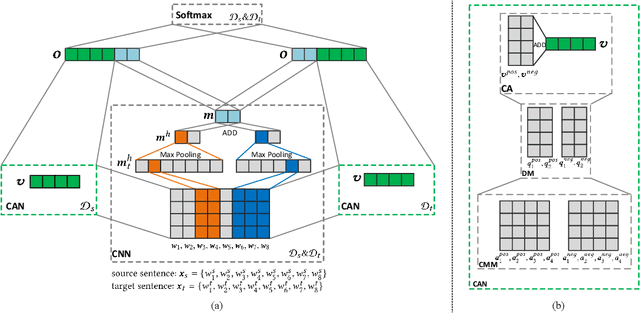
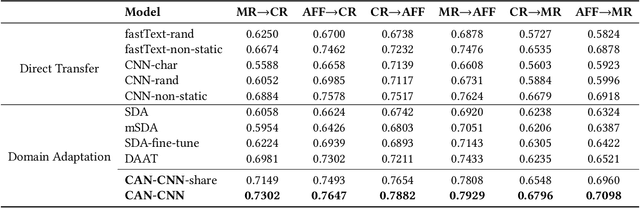
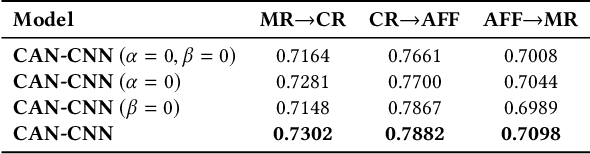
Domain adaptation tasks such as cross-domain sentiment classification aim to utilize existing labeled data in the source domain and unlabeled or few labeled data in the target domain to improve the performance in the target domain via reducing the shift between the data distributions. Existing cross-domain sentiment classification methods need to distinguish pivots, i.e., the domain-shared sentiment words, and non-pivots, i.e., the domain-specific sentiment words, for excellent adaptation performance. In this paper, we first design a Category Attention Network (CAN), and then propose a model named CAN-CNN to integrate CAN and a Convolutional Neural Network (CNN). On the one hand, the model regards pivots and non-pivots as unified category attribute words and can automatically capture them to improve the domain adaptation performance; on the other hand, the model makes an attempt at interpretability to learn the transferred category attribute words. Specifically, the optimization objective of our model has three different components: 1) the supervised classification loss; 2) the distributions loss of category feature weights; 3) the domain invariance loss. Finally, the proposed model is evaluated on three public sentiment analysis datasets and the results demonstrate that CAN-CNN can outperform other various baseline methods.
Denoising Relation Extraction from Document-level Distant Supervision
Nov 08, 2020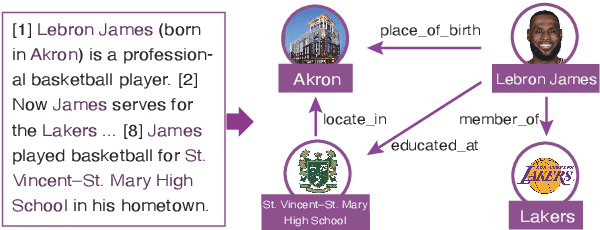
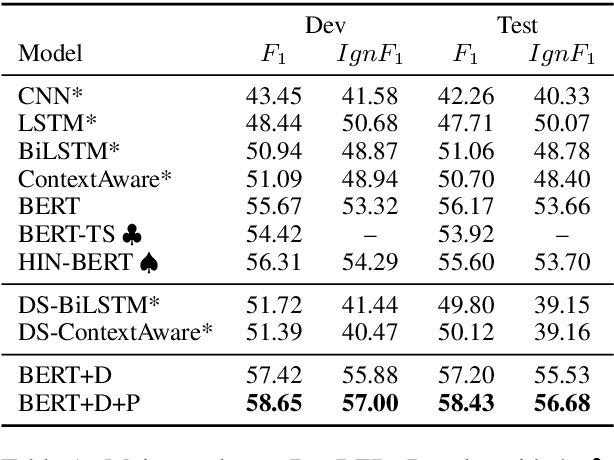
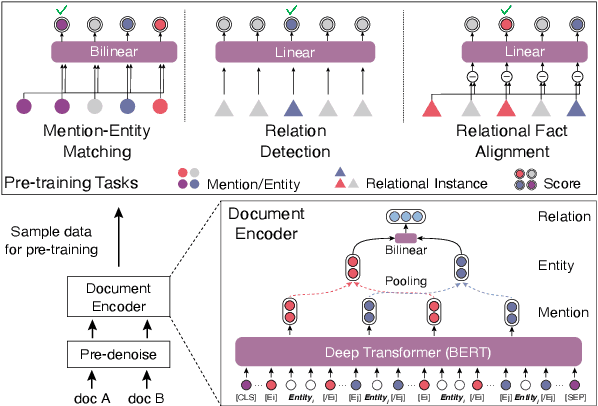

Distant supervision (DS) has been widely used to generate auto-labeled data for sentence-level relation extraction (RE), which improves RE performance. However, the existing success of DS cannot be directly transferred to the more challenging document-level relation extraction (DocRE), since the inherent noise in DS may be even multiplied in document level and significantly harm the performance of RE. To address this challenge, we propose a novel pre-trained model for DocRE, which denoises the document-level DS data via multiple pre-training tasks. Experimental results on the large-scale DocRE benchmark show that our model can capture useful information from noisy DS data and achieve promising results.
Knowledge Transfer via Pre-training for Recommendation: A Review and Prospect
Sep 19, 2020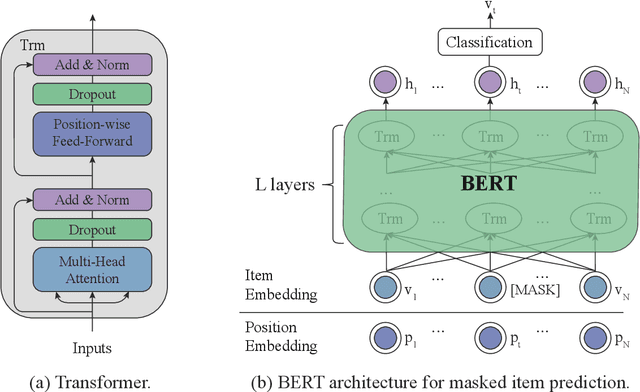
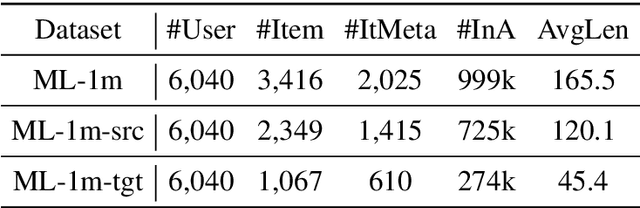
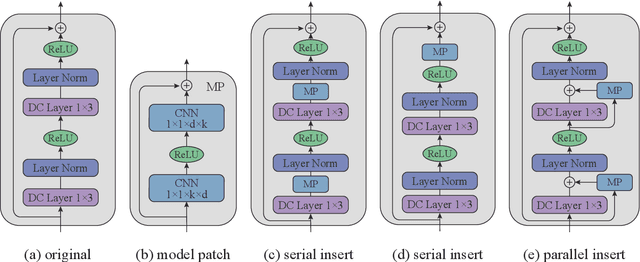
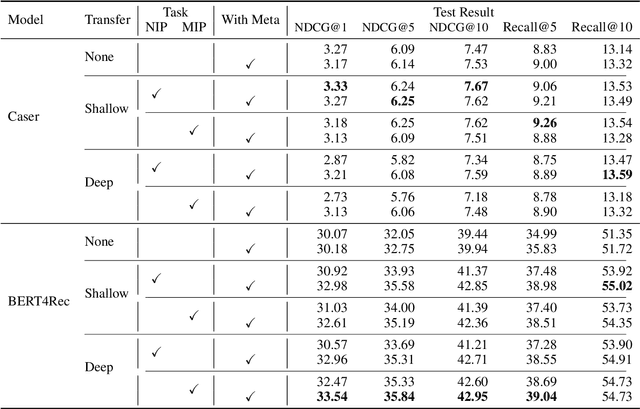
Recommender systems aim to provide item recommendations for users, and are usually faced with data sparsity problem (e.g., cold start) in real-world scenarios. Recently pre-trained models have shown their effectiveness in knowledge transfer between domains and tasks, which can potentially alleviate the data sparsity problem in recommender systems. In this survey, we first provide a review of recommender systems with pre-training. In addition, we show the benefits of pre-training to recommender systems through experiments. Finally, we discuss several promising directions for future research for recommender systems with pre-training.
FAQ-based Question Answering via Knowledge Anchors
Nov 14, 2019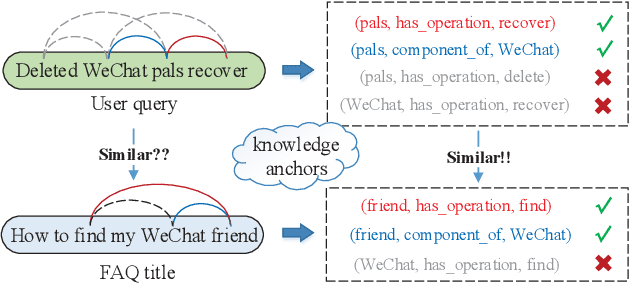


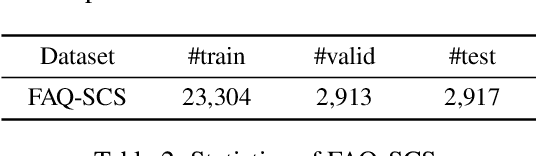
Question answering (QA) aims to understand user questions and find appropriate answers. In real-world QA systems, Frequently Asked Question (FAQ) based QA is usually a practical and effective solution, especially for some complicated questions (e.g., How and Why). Recent years have witnessed the great successes of knowledge graphs (KGs) utilized in KBQA systems, while there are still few works focusing on making full use of KGs in FAQ-based QA. In this paper, we propose a novel Knowledge Anchor based Question Answering (KAQA) framework for FAQ-based QA to better understand questions and retrieve more appropriate answers. More specifically, KAQA mainly consists of three parts: knowledge graph construction, query anchoring and query-document matching. We consider entities and triples of KGs in texts as knowledge anchors to precisely capture the core semantics, which brings in higher precision and better interpretability. The multi-channel matching strategy also enable most sentence matching models to be flexibly plugged in out KAQA framework to fit different real-world computation costs. In experiments, we evaluate our models on a query-document matching task over a real-world FAQ-based QA dataset, with detailed analysis over different settings and cases. The results confirm the effectiveness and robustness of the KAQA framework in real-world FAQ-based QA.
Neural Snowball for Few-Shot Relation Learning
Aug 29, 2019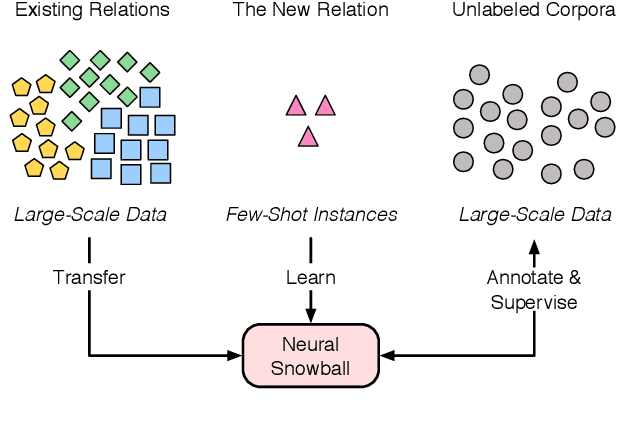

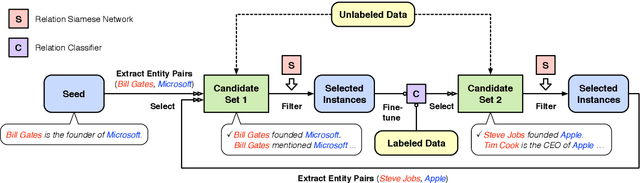
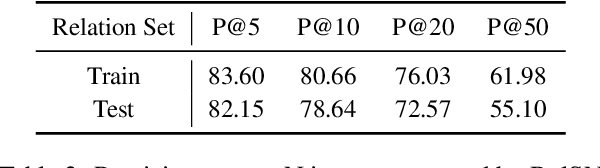
Knowledge graphs typically undergo open-ended growth of new relations. This cannot be well handled by relation extraction that focuses on pre-defined relations with sufficient training data. To address new relations with few-shot instances, we propose a novel bootstrapping approach, Neural Snowball, to learn new relations by transferring semantic knowledge about existing relations. More specifically, we design Relation Siamese Networks (RelSN) to learn the metric of relational similarities between instances based on existing relations and their labeled data. Afterwards, given a new relation and its few-shot instances, we use RelSN to accumulate reliable instances from unlabeled corpora; these instances are used to train a relation classifier, which can further identify new facts of the new relation. The process is conducted iteratively like a snowball. Experiments show that our model can gather high-quality instances for better few-shot relation learning and achieves significant improvement compared to baselines. Codes and datasets will be released soon.
Atom Responding Machine for Dialog Generation
May 15, 2019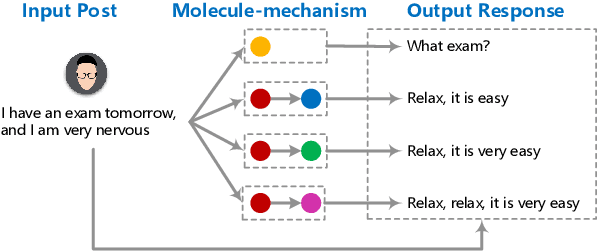
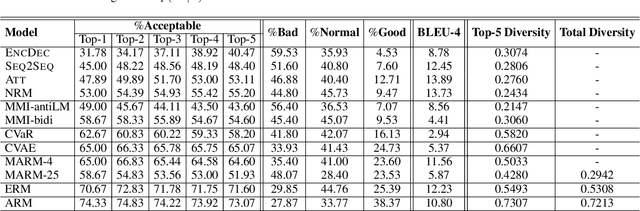
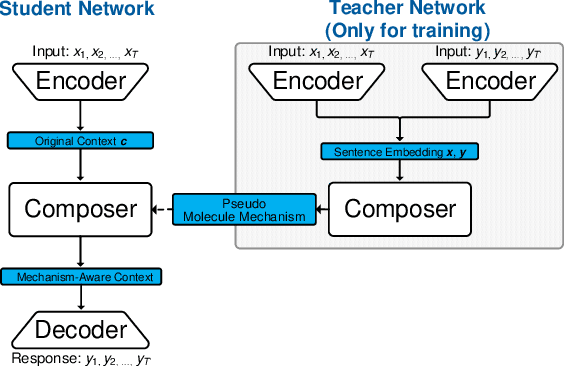
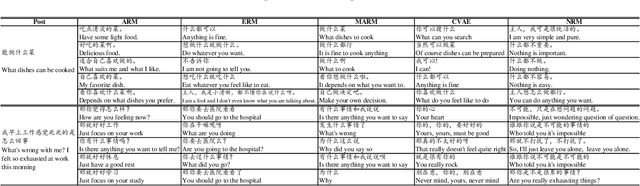
Recently, improving the relevance and diversity of dialogue system has attracted wide attention. For a post x, the corresponding response y is usually diverse in the real-world corpus, while the conventional encoder-decoder model tends to output the high-frequency (safe but trivial) responses and thus is difficult to handle the large number of responding styles. To address these issues, we propose the Atom Responding Machine (ARM), which is based on a proposed encoder-composer-decoder network trained by a teacher-student framework. To enrich the generated responses, ARM introduces a large number of molecule-mechanisms as various responding styles, which are conducted by taking different combinations from a few atom-mechanisms. In other words, even a little of atom-mechanisms can make a mickle of molecule-mechanisms. The experiments demonstrate diversity and quality of the responses generated by ARM. We also present generating process to show underlying interpretability for the result.
Language Modeling with Sparse Product of Sememe Experts
Oct 29, 2018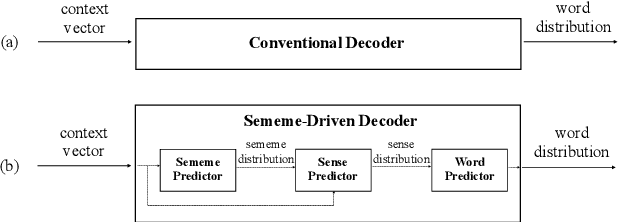
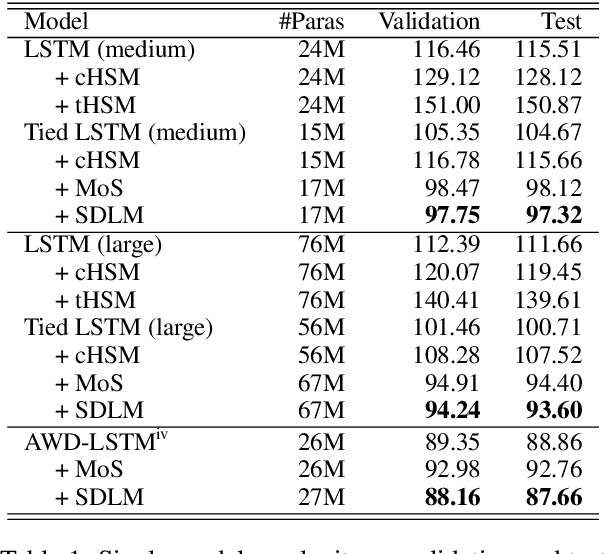
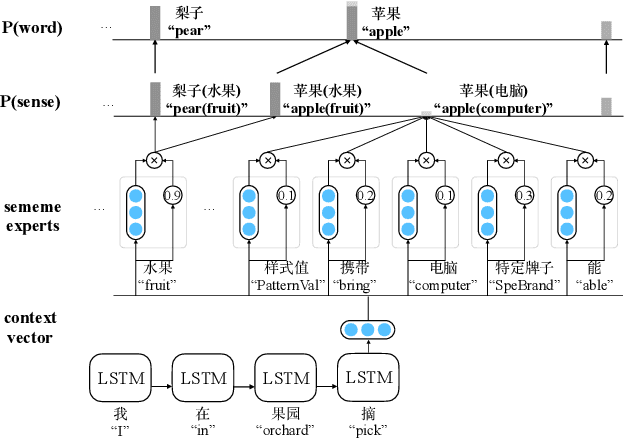
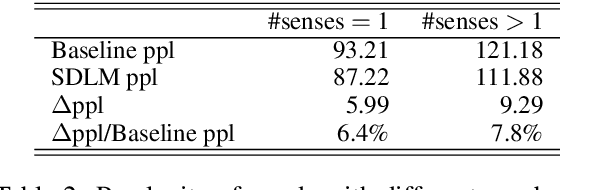
Most language modeling methods rely on large-scale data to statistically learn the sequential patterns of words. In this paper, we argue that words are atomic language units but not necessarily atomic semantic units. Inspired by HowNet, we use sememes, the minimum semantic units in human languages, to represent the implicit semantics behind words for language modeling, named Sememe-Driven Language Model (SDLM). More specifically, to predict the next word, SDLM first estimates the sememe distribution gave textual context. Afterward, it regards each sememe as a distinct semantic expert, and these experts jointly identify the most probable senses and the corresponding word. In this way, SDLM enables language models to work beyond word-level manipulation to fine-grained sememe-level semantics and offers us more powerful tools to fine-tune language models and improve the interpretability as well as the robustness of language models. Experiments on language modeling and the downstream application of headline gener- ation demonstrate the significant effect of SDLM. Source code and data used in the experiments can be accessed at https:// github.com/thunlp/SDLM-pytorch.
Hierarchical Neural Network for Extracting Knowledgeable Snippets and Documents
Aug 22, 2018

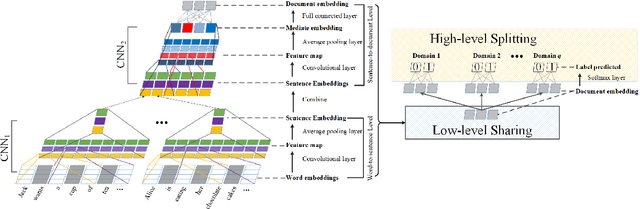

In this study, we focus on extracting knowledgeable snippets and annotating knowledgeable documents from Web corpus, consisting of the documents from social media and We-media. Informally, knowledgeable snippets refer to the text describing concepts, properties of entities, or relations among entities, while knowledgeable documents are the ones with enough knowledgeable snippets. These knowledgeable snippets and documents could be helpful in multiple applications, such as knowledge base construction and knowledge-oriented service. Previous studies extracted the knowledgeable snippets using the pattern-based method. Here, we propose the semantic-based method for this task. Specifically, a CNN based model is developed to extract knowledgeable snippets and annotate knowledgeable documents simultaneously. Additionally, a "low-level sharing, high-level splitting" structure of CNN is designed to handle the documents from different content domains. Compared with building multiple domain-specific CNNs, this joint model not only critically saves the training time, but also improves the prediction accuracy visibly. The superiority of the proposed method is demonstrated in a real dataset from Wechat public platform.
Incorporating Chinese Characters of Words for Lexical Sememe Prediction
Jun 17, 2018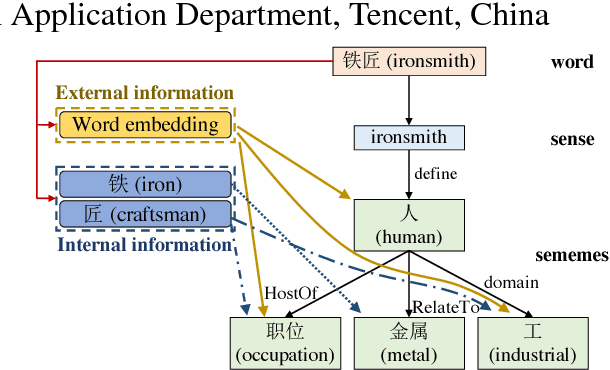
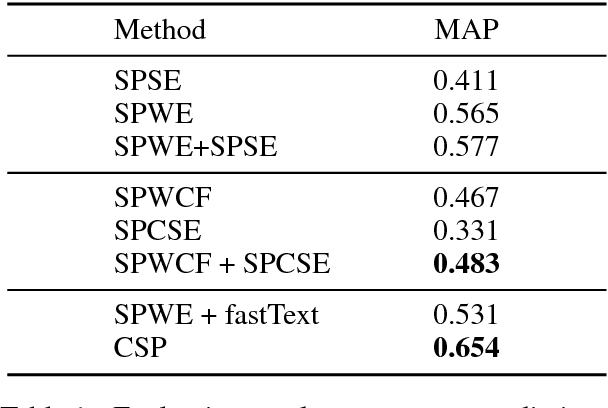

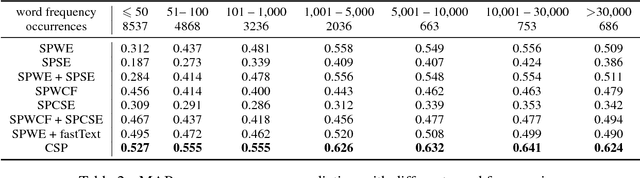
Sememes are minimum semantic units of concepts in human languages, such that each word sense is composed of one or multiple sememes. Words are usually manually annotated with their sememes by linguists, and form linguistic common-sense knowledge bases widely used in various NLP tasks. Recently, the lexical sememe prediction task has been introduced. It consists of automatically recommending sememes for words, which is expected to improve annotation efficiency and consistency. However, existing methods of lexical sememe prediction typically rely on the external context of words to represent the meaning, which usually fails to deal with low-frequency and out-of-vocabulary words. To address this issue for Chinese, we propose a novel framework to take advantage of both internal character information and external context information of words. We experiment on HowNet, a Chinese sememe knowledge base, and demonstrate that our framework outperforms state-of-the-art baselines by a large margin, and maintains a robust performance even for low-frequency words.