 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Neural Network for Extracting Knowledgeable Snippets and Documents
Paper and Code
Aug 22, 2018

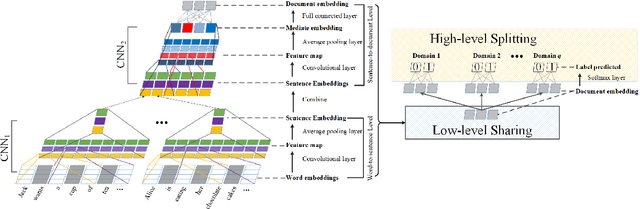

In this study, we focus on extracting knowledgeable snippets and annotating knowledgeable documents from Web corpus, consisting of the documents from social media and We-media. Informally, knowledgeable snippets refer to the text describing concepts, properties of entities, or relations among entities, while knowledgeable documents are the ones with enough knowledgeable snippets. These knowledgeable snippets and documents could be helpful in multiple applications, such as knowledge base construction and knowledge-oriented service. Previous studies extracted the knowledgeable snippets using the pattern-based method. Here, we propose the semantic-based method for this task. Specifically, a CNN based model is developed to extract knowledgeable snippets and annotate knowledgeable documents simultaneously. Additionally, a "low-level sharing, high-level splitting" structure of CNN is designed to handle the documents from different content domains. Compared with building multiple domain-specific CNNs, this joint model not only critically saves the training time, but also improves the prediction accuracy visibly. The superiority of the proposed method is demonstrated in a real dataset from Wechat public platform.