 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Morphological Paradigm Completion
May 20, 2020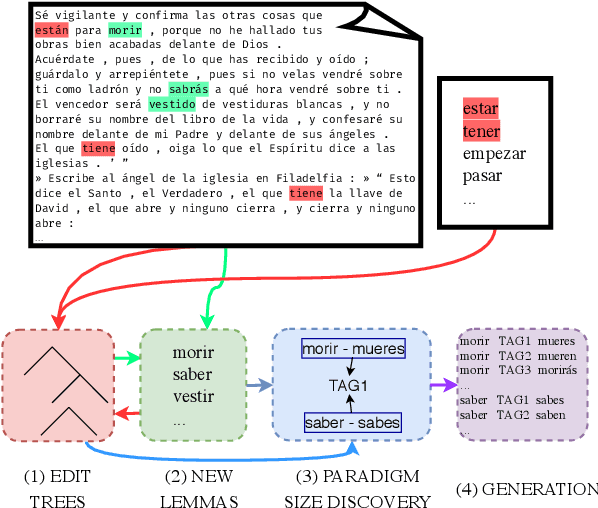
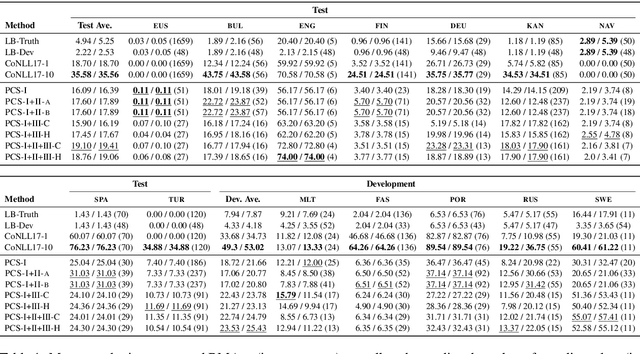
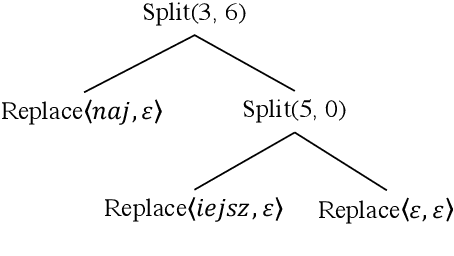
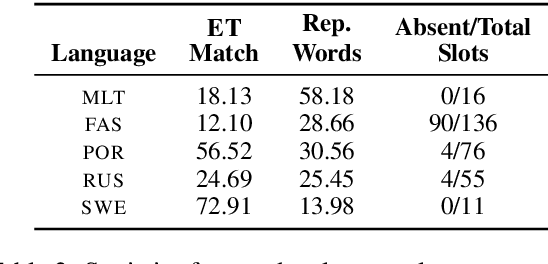
We propose the task of unsupervised morphological paradigm completion. Given only raw text and a lemma list, the task consists of generating the morphological paradigms, i.e., all inflected forms, of the lemmas. From a natural language processing (NLP) perspective, this is a challenging unsupervised task, and high-performing systems have the potential to improve tools for low-resource languages or to assist linguistic annotators. From a cognitive science perspective, this can shed light on how children acquire morphological knowledge. We further introduce a system for the task, which generates morphological paradigms via the following steps: (i) EDIT TREE retrieval, (ii) additional lemma retrieval, (iii) paradigm size discovery, and (iv) inflection generation. We perform an evaluation on 14 typologically diverse languages. Our system outperforms trivial baselines with ease and, for some languages, even obtains a higher accuracy than minimally supervised systems.
Incorporating Chinese Characters of Words for Lexical Sememe Prediction
Jun 17, 2018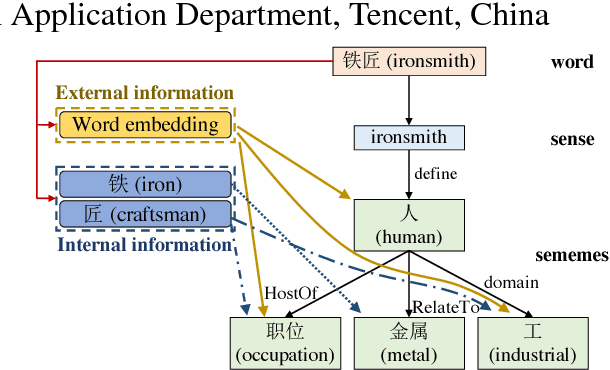
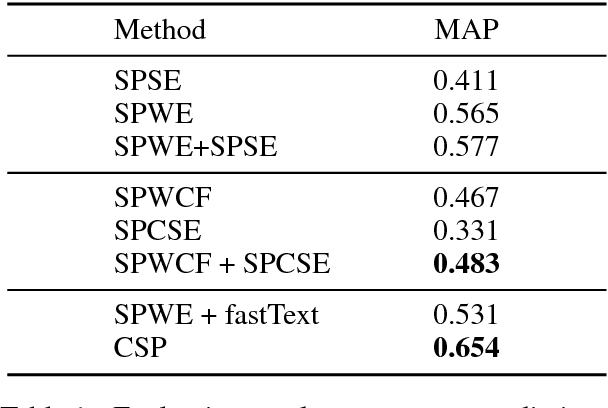

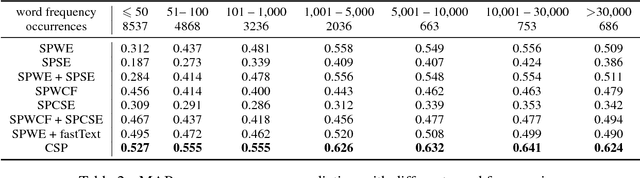
Sememes are minimum semantic units of concepts in human languages, such that each word sense is composed of one or multiple sememes. Words are usually manually annotated with their sememes by linguists, and form linguistic common-sense knowledge bases widely used in various NLP tasks. Recently, the lexical sememe prediction task has been introduced. It consists of automatically recommending sememes for words, which is expected to improve annotation efficiency and consistency. However, existing methods of lexical sememe prediction typically rely on the external context of words to represent the meaning, which usually fails to deal with low-frequency and out-of-vocabulary words. To address this issue for Chinese, we propose a novel framework to take advantage of both internal character information and external context information of words. We experiment on HowNet, a Chinese sememe knowledge base, and demonstrate that our framework outperforms state-of-the-art baselines by a large margin, and maintains a robust performance even for low-frequency words.