 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Jan 05, 2026Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal Large Language Models (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.
FAQ-based Question Answering via Knowledge Anchors
Nov 14, 2019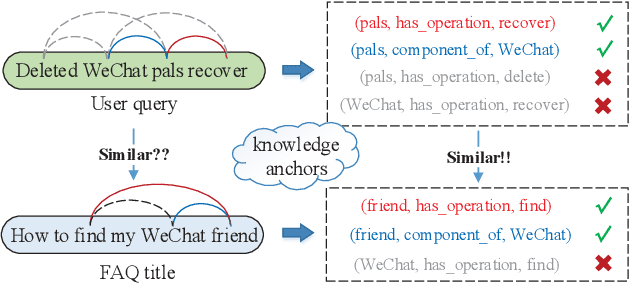


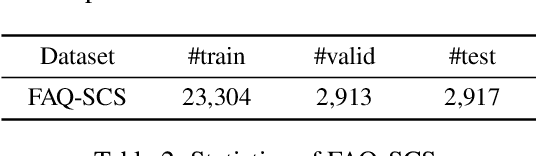
Question answering (QA) aims to understand user questions and find appropriate answers. In real-world QA systems, Frequently Asked Question (FAQ) based QA is usually a practical and effective solution, especially for some complicated questions (e.g., How and Why). Recent years have witnessed the great successes of knowledge graphs (KGs) utilized in KBQA systems, while there are still few works focusing on making full use of KGs in FAQ-based QA. In this paper, we propose a novel Knowledge Anchor based Question Answering (KAQA) framework for FAQ-based QA to better understand questions and retrieve more appropriate answers. More specifically, KAQA mainly consists of three parts: knowledge graph construction, query anchoring and query-document matching. We consider entities and triples of KGs in texts as knowledge anchors to precisely capture the core semantics, which brings in higher precision and better interpretability. The multi-channel matching strategy also enable most sentence matching models to be flexibly plugged in out KAQA framework to fit different real-world computation costs. In experiments, we evaluate our models on a query-document matching task over a real-world FAQ-based QA dataset, with detailed analysis over different settings and cases. The results confirm the effectiveness and robustness of the KAQA framework in real-world FAQ-based QA.