 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Sampling and Joint Semantic-Channel Coding under Dynamic Channel Environment
Feb 11, 2025Deep learning enabled semantic communications are attracting extensive attention. However, most works normally ignore the data acquisition process and suffer from robustness issues under dynamic channel environment. In this paper, we propose an adaptive joint sampling-semantic-channel coding (Adaptive-JSSCC) framework. Specifically, we propose a semantic-aware sampling and reconstruction method to optimize the number of samples dynamically for each region of the images. According to semantic significance, we optimize sampling matrices for each region of the most individually and obtain a semantic sampling ratio distribution map shared with the receiver. Through the guidance of the map, high-quality reconstruction is achieved. Meanwhile, attention-based channel adaptive module (ACAM) is designed to overcome the neural network model mismatch between the training and testing channel environment during sampling-reconstruction and encoding-decoding. To this end, signal-to-noise ratio (SNR) is employed as an extra parameter input to integrate and reorganize intermediate characteristics. Simulation results show that the proposed Adaptive-JSSCC effectively reduces the amount of data acquisition without degrading the reconstruction performance in comparison to the state-of-the-art, and it is highly adaptable and adjustable to dynamic channel environments.
PRASEMap: A Probabilistic Reasoning and Semantic Embedding based Knowledge Graph Alignment System
Jun 16, 2021



Knowledge Graph (KG) alignment aims at finding equivalent entities and relations (i.e., mappings) between two KGs. The existing approaches utilize either reasoning-based or semantic embedding-based techniques, but few studies explore their combination. In this demonstration, we present PRASEMap, an unsupervised KG alignment system that iteratively computes the Mappings with both Probabilistic Reasoning (PR) And Semantic Embedding (SE) techniques. PRASEMap can support various embedding-based KG alignment approaches as the SE module, and enables easy human computer interaction that additionally provides an option for users to feed the mapping annotations back to the system for better results. The demonstration showcases these features via a stand-alone Web application with user friendly interfaces.
Unsupervised Knowledge Graph Alignment by Probabilistic Reasoning and Semantic Embedding
May 19, 2021
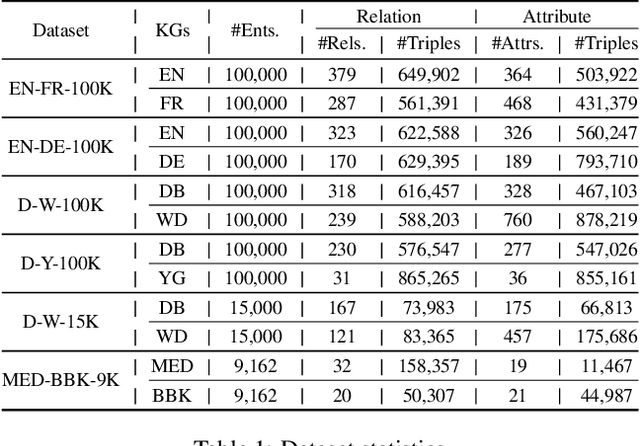
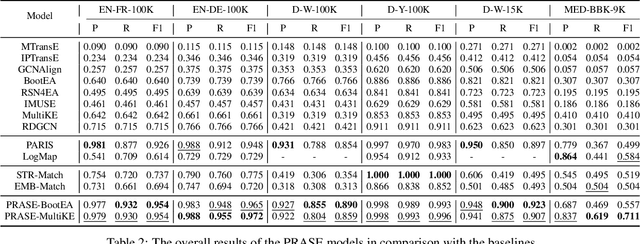
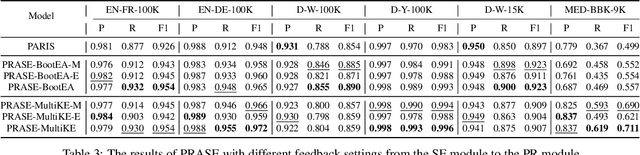
Knowledge Graph (KG) alignment is to discover the mappings (i.e., equivalent entities, relations, and others) between two KGs. The existing methods can be divided into the embedding-based models, and the conventional reasoning and lexical matching based systems. The former compute the similarity of entities via their cross-KG embeddings, but they usually rely on an ideal supervised learning setting for good performance and lack appropriate reasoning to avoid logically wrong mappings; while the latter address the reasoning issue but are poor at utilizing the KG graph structures and the entity contexts. In this study, we aim at combining the above two solutions and thus propose an iterative framework named PRASE which is based on probabilistic reasoning and semantic embedding. It learns the KG embeddings via entity mappings from a probabilistic reasoning system named PARIS, and feeds the resultant entity mappings and embeddings back into PARIS for augmentation. The PRASE framework is compatible with different embedding-based models, and our experiments on multiple datasets have demonstrated its state-of-the-art performance.
Combat Data Shift in Few-shot Learning with Knowledge Graph
Feb 26, 2021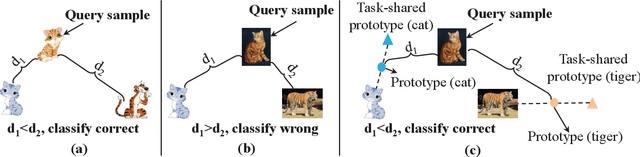
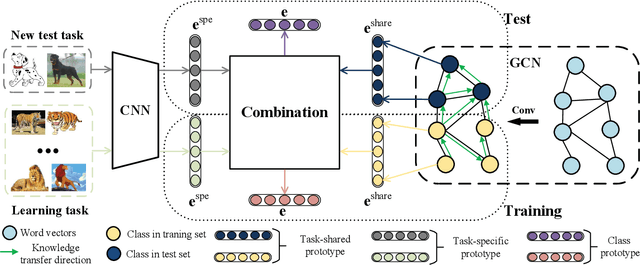
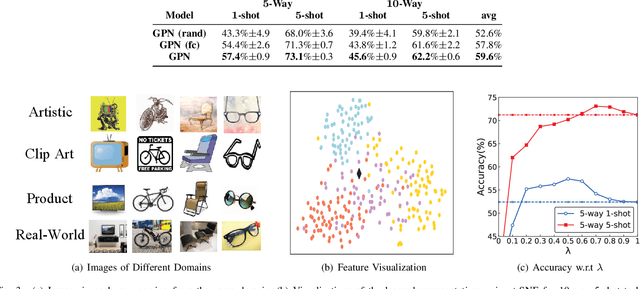
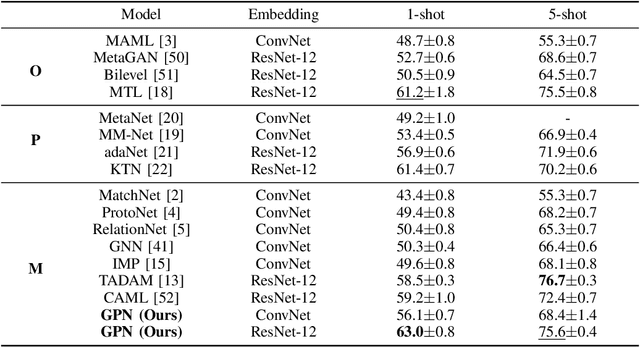
Many few-shot learning approaches have been designed under the meta-learning framework, which learns from a variety of learning tasks and generalizes to new tasks. These meta-learning approaches achieve the expected performance in the scenario where all samples are drawn from the same distributions (i.i.d. observations). However, in real-world applications, few-shot learning paradigm often suffers from data shift, i.e., samples in different tasks, even in the same task, could be drawn from various data distributions. Most existing few-shot learning approaches are not designed with the consideration of data shift, and thus show downgraded performance when data distribution shifts. However, it is non-trivial to address the data shift problem in few-shot learning, due to the limited number of labeled samples in each task. Targeting at addressing this problem, we propose a novel metric-based meta-learning framework to extract task-specific representations and task-shared representations with the help of knowledge graph. The data shift within/between tasks can thus be combated by the combination of task-shared and task-specific representations. The proposed model is evaluated on popular benchmarks and two constructed new challenging datasets. The evaluation results demonstrate its remarkable performance.
A Comprehensive Survey on Transfer Learning
Dec 17, 2019
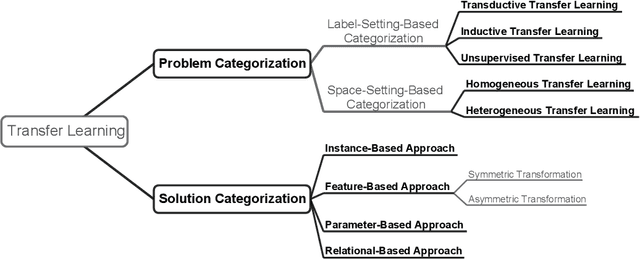
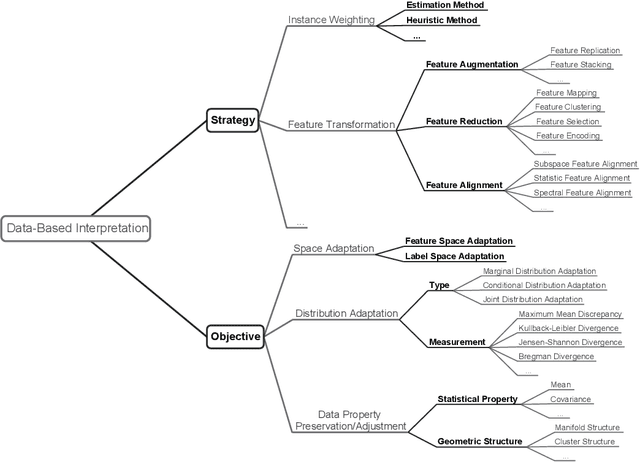

Transfer learning aims at improving the performance of target learners on target domains by transferring the knowledge contained in different but related source domains. In this way, the dependence on a large number of target domain data can be reduced for constructing target learners. Due to the wide application prospects, transfer learning has become a popular and promising area in machine learning. Although there are already some valuable and impressive surveys on transfer learning, these surveys introduce approaches in a relatively isolated way and lack the recent advances in transfer learning. As the rapid expansion of the transfer learning area, it is both necessary and challenging to comprehensively review the relevant studies. This survey attempts to connect and systematize the existing transfer learning researches, as well as to summarize and interpret the mechanisms and the strategies in a comprehensive way, which may help readers have a better understanding of the current research status and ideas. Different from previous surveys, this survey paper reviews over forty representative transfer learning approaches from the perspectives of data and model. The applications of transfer learning are also briefly introduced. In order to show the performance of different transfer learning models, twenty representative transfer learning models are used for experiments. The models are performed on three different datasets, i.e., Amazon Reviews, Reuters-21578, and Office-31. And the experimental results demonstrate the importance of selecting appropriate transfer learning models for different applications in practice.
Transfer Learning Toolkit: Primers and Benchmarks
Nov 20, 2019

The transfer learning toolkit wraps the codes of 17 transfer learning models and provides integrated interfaces, allowing users to use those models by calling a simple function. It is easy for primary researchers to use this toolkit and to choose proper models for real-world applications. The toolkit is written in Python and distributed under MIT open source license. In this paper, the current state of this toolkit is described and the necessary environment setting and usage are introduced.