 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion Matters: Length-Aware Analysis of Positional-Encoding Fusion in Transformers
Jan 09, 2026Transformers require positional encodings to represent sequence order, yet most prior work focuses on designing new positional encodings rather than examining how positional information is fused with token embeddings. In this paper, we study whether the fusion mechanism itself affects performance, particularly in long-sequence settings. We conduct a controlled empirical study comparing three canonical fusion strategies--element-wise addition, concatenation with projection, and scalar gated fusion--under identical Transformer architectures, data splits, and random seeds. Experiments on three text classification datasets spanning short (AG News), medium (IMDB), and long (ArXiv) sequences show that fusion choice has negligible impact on short texts but produces consistent gains on long documents. To verify that these gains are structural rather than stochastic, we perform paired-seed analysis and cross-dataset comparison across sequence-length regimes. Additional experiments on the ArXiv dataset indicate that the benefit of learnable fusion generalizes across multiple positional encoding families. Finally, we explore a lightweight convolutional gating mechanism that introduces local inductive bias at the fusion level, evaluated on long documents only. Our results indicate that positional-encoding fusion is a non-trivial design choice for long-sequence Transformers and should be treated as an explicit modeling decision rather than a fixed default.
RoboGSim: A Real2Sim2Real Robotic Gaussian Splatting Simulator
Nov 18, 2024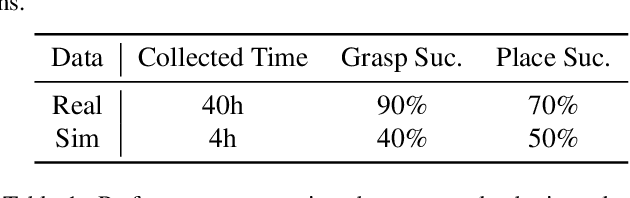
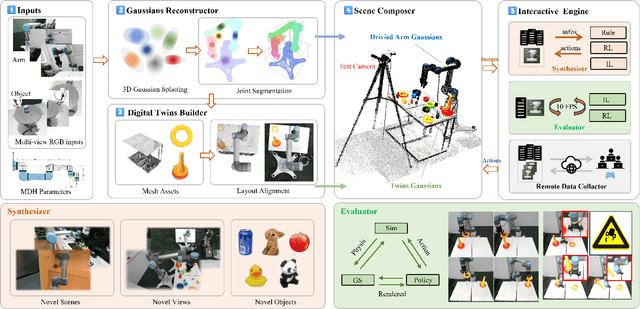


Efficient acquisition of real-world embodied data has been increasingly critical. However, large-scale demonstrations captured by remote operation tend to take extremely high costs and fail to scale up the data size in an efficient manner. Sampling the episodes under a simulated environment is a promising way for large-scale collection while existing simulators fail to high-fidelity modeling on texture and physics. To address these limitations, we introduce the RoboGSim, a real2sim2real robotic simulator, powered by 3D Gaussian Splatting and the physics engine. RoboGSim mainly includes four parts: Gaussian Reconstructor, Digital Twins Builder, Scene Composer, and Interactive Engine. It can synthesize the simulated data with novel views, objects, trajectories, and scenes. RoboGSim also provides an online, reproducible, and safe evaluation for different manipulation policies. The real2sim and sim2real transfer experiments show a high consistency in the texture and physics. Moreover, the effectiveness of synthetic data is validated under the real-world manipulated tasks. We hope RoboGSim serves as a closed-loop simulator for fair comparison on policy learning. More information can be found on our project page https://robogsim.github.io/ .
GaussianDiffusion: 3D Gaussian Splatting for Denoising Diffusion Probabilistic Models with Structured Noise
Nov 19, 2023Text-to-3D, known for its efficient generation methods and expansive creative potential, has garnered significant attention in the AIGC domain. However, the amalgamation of Nerf and 2D diffusion models frequently yields oversaturated images, posing severe limitations on downstream industrial applications due to the constraints of pixelwise rendering method. Gaussian splatting has recently superseded the traditional pointwise sampling technique prevalent in NeRF-based methodologies, revolutionizing various aspects of 3D reconstruction. This paper introduces a novel text to 3D content generation framework based on Gaussian splatting, enabling fine control over image saturation through individual Gaussian sphere transparencies, thereby producing more realistic images. The challenge of achieving multi-view consistency in 3D generation significantly impedes modeling complexity and accuracy. Taking inspiration from SJC, we explore employing multi-view noise distributions to perturb images generated by 3D Gaussian splatting, aiming to rectify inconsistencies in multi-view geometry. We ingeniously devise an efficient method to generate noise that produces Gaussian noise from diverse viewpoints, all originating from a shared noise source. Furthermore, vanilla 3D Gaussian-based generation tends to trap models in local minima, causing artifacts like floaters, burrs, or proliferative elements. To mitigate these issues, we propose the variational Gaussian splatting technique to enhance the quality and stability of 3D appearance. To our knowledge, our approach represents the first comprehensive utilization of Gaussian splatting across the entire spectrum of 3D content generation processes.