 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS3Net: 3D LiDAR Sparse Semantic Segmentation Network
Paper and Code
Mar 15, 2021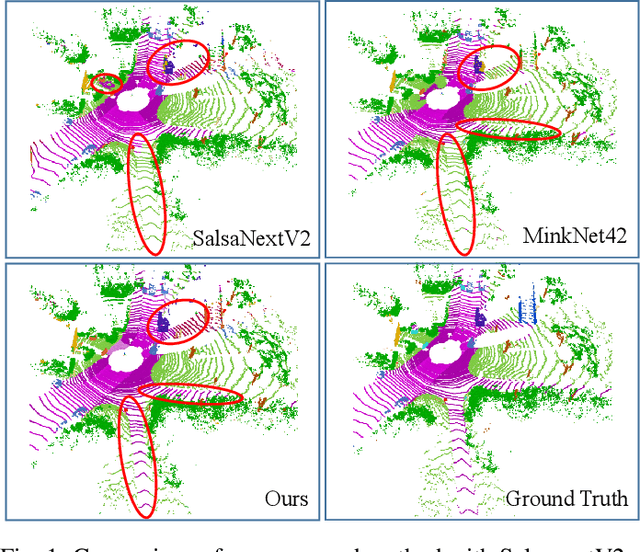

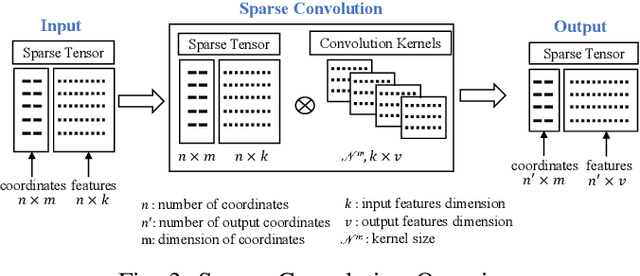
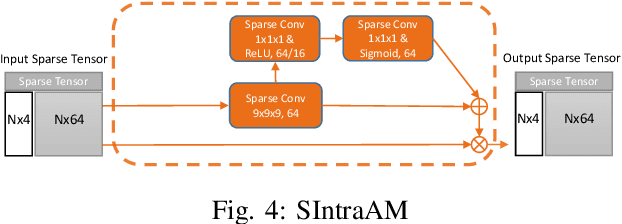
Semantic Segmentation is a crucial component in the perception systems of many applications, such as robotics and autonomous driving that rely on accurate environmental perception and understanding. In literature, several approaches are introduced to attempt LiDAR semantic segmentation task, such as projection-based (range-view or birds-eye-view), and voxel-based approaches. However, they either abandon the valuable 3D topology and geometric relations and suffer from information loss introduced in the projection process or are inefficient. Therefore, there is a need for accurate models capable of processing the 3D driving-scene point cloud in 3D space. In this paper, we propose S3Net, a novel convolutional neural network for LiDAR point cloud semantic segmentation. It adopts an encoder-decoder backbone that consists of Sparse Intra-channel Attention Module (SIntraAM), and Sparse Inter-channel Attention Module (SInterAM) to emphasize the fine details of both within each feature map and among nearby feature maps. To extract the global contexts in deeper layers, we introduce Sparse Residual Tower based upon sparse convolution that suits varying sparsity of LiDAR point cloud. In addition, geo-aware anisotrophic loss is leveraged to emphasize the semantic boundaries and penalize the noise within each predicted regions, leading to a robust prediction. Our experimental results show that the proposed method leads to a large improvement (12\%) compared to its baseline counterpart (MinkNet42 \cite{choy20194d}) on SemanticKITTI \cite{DBLP:conf/iccv/BehleyGMQBSG19} test set and achieves state-of-the-art mIoU accuracy of semantic segmentation approaches.