 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Camera Pose Augmentation for View Generalization in Robotic Policy Learning
Mar 31, 2026Prevailing 2D-centric visuomotor policies exhibit a pronounced deficiency in novel view generalization, as their reliance on static observations hinders consistent action mapping across unseen views. In response, we introduce GenSplat, a feed-forward 3D Gaussian Splatting framework that facilitates view-generalized policy learning through novel view rendering. GenSplat employs a permutation-equivariant architecture to reconstruct high-fidelity 3D scenes from sparse, uncalibrated inputs in a single forward pass. To ensure structural integrity, we design a 3D-prior distillation strategy that regularizes the 3DGS optimization, preventing the geometric collapse typical of purely photometric supervision. By rendering diverse synthetic views from these stable 3D representations, we systematically augment the observational manifold during training. This augmentation forces the policy to ground its decisions in underlying 3D structures, thereby ensuring robust execution under severe spatial perturbations where baselines severely degrade.
Do World Action Models Generalize Better than VLAs? A Robustness Study
Mar 23, 2026Robot action planning in the real world is challenging as it requires not only understanding the current state of the environment but also predicting how it will evolve in response to actions. Vision-language-action (VLA), which repurpose large-scale vision-language models for robot action generation using action experts, have achieved notable success across a variety of robotic tasks. Nevertheless, their performance remains constrained by the scope of their training data, exhibiting limited generalization to unseen scenarios and vulnerability to diverse contextual perturbations. More recently, world models have been revisited as an alternative to VLAs. These models, referred to as world action models (WAMs), are built upon world models that are trained on large corpora of video data to predict future states. With minor adaptations, their latent representation can be decoded into robot actions. It has been suggested that their explicit dynamic prediction capacity, combined with spatiotemporal priors acquired from web-scale video pretraining, enables WAMs to generalize more effectively than VLAs. In this paper, we conduct a comparative study of prominent state-of-the-art VLA policies and recently released WAMs. We evaluate their performance on the LIBERO-Plus and RoboTwin 2.0-Plus benchmarks under various visual and language perturbations. Our results show that WAMs achieve strong robustness, with LingBot-VA reaching 74.2% success rate on RoboTwin 2.0-Plus and Cosmos-Policy achieving 82.2% on LIBERO-Plus. While VLAs such as $π_{0.5}$ can achieve comparable robustness on certain tasks, they typically require extensive training with diverse robotic datasets and varied learning objectives. Hybrid approaches that partially incorporate video-based dynamic learning exhibit intermediate robustness, highlighting the importance of how video priors are integrated.
H-WM: Robotic Task and Motion Planning Guided by Hierarchical World Model
Feb 11, 2026World models are becoming central to robotic planning and control, as they enable prediction of future state transitions. Existing approaches often emphasize video generation or natural language prediction, which are difficult to directly ground in robot actions and suffer from compounding errors over long horizons. Traditional task and motion planning relies on symbolic logic world models, such as planning domains, that are robot-executable and robust for long-horizon reasoning. However, these methods typically operate independently of visual perception, preventing synchronized symbolic and perceptual state prediction. We propose a Hierarchical World Model (H-WM) that jointly predicts logical and visual state transitions within a unified bilevel framework. H-WM combines a high-level logical world model with a low-level visual world model, integrating the robot-executable, long-horizon robustness of symbolic reasoning with perceptual grounding from visual observations. The hierarchical outputs provide stable and consistent intermediate guidance for long-horizon tasks, mitigating error accumulation and enabling robust execution across extended task sequences. To train H-WM, we introduce a robotic dataset that aligns robot motion with symbolic states, actions, and visual observations. Experiments across vision-language-action (VLA) control policies demonstrate the effectiveness and generality of the approach.
Mem2Ego: Empowering Vision-Language Models with Global-to-Ego Memory for Long-Horizon Embodied Navigation
Feb 20, 2025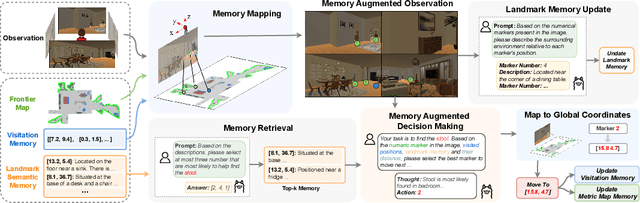
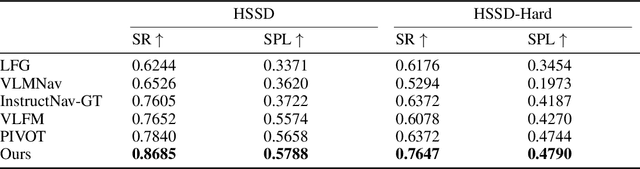
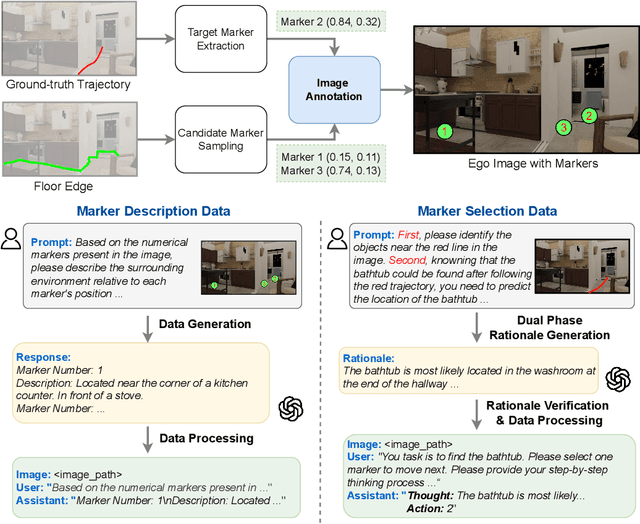

Recent advancements in Large Language Models (LLMs) and Vision-Language Models (VLMs) have made them powerful tools in embodied navigation, enabling agents to leverage commonsense and spatial reasoning for efficient exploration in unfamiliar environments. Existing LLM-based approaches convert global memory, such as semantic or topological maps, into language descriptions to guide navigation. While this improves efficiency and reduces redundant exploration, the loss of geometric information in language-based representations hinders spatial reasoning, especially in intricate environments. To address this, VLM-based approaches directly process ego-centric visual inputs to select optimal directions for exploration. However, relying solely on a first-person perspective makes navigation a partially observed decision-making problem, leading to suboptimal decisions in complex environments. In this paper, we present a novel vision-language model (VLM)-based navigation framework that addresses these challenges by adaptively retrieving task-relevant cues from a global memory module and integrating them with the agent's egocentric observations. By dynamically aligning global contextual information with local perception, our approach enhances spatial reasoning and decision-making in long-horizon tasks. Experimental results demonstrate that the proposed method surpasses previous state-of-the-art approaches in object navigation tasks, providing a more effective and scalable solution for embodied navigation.
SpatialCoT: Advancing Spatial Reasoning through Coordinate Alignment and Chain-of-Thought for Embodied Task Planning
Jan 17, 2025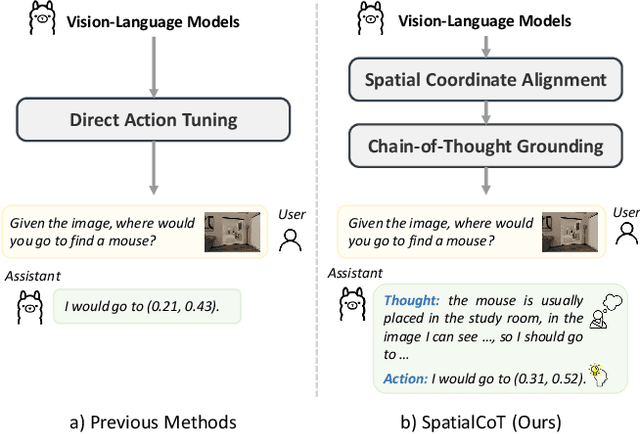
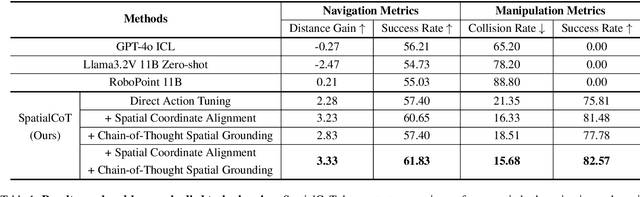
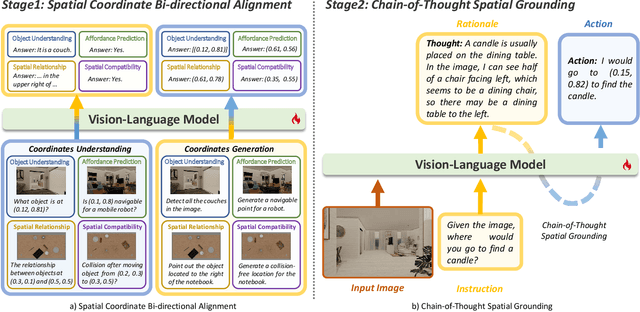
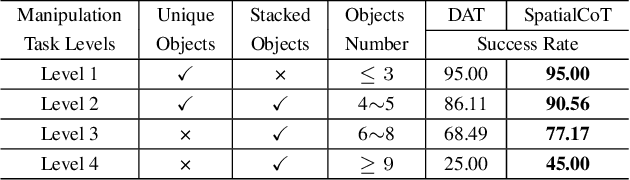
Spatial reasoning is an essential problem in embodied AI research. Efforts to enhance spatial reasoning abilities through supplementary spatial data and fine-tuning have proven limited and ineffective when addressing complex embodied tasks, largely due to their dependence on language-based outputs. While some approaches have introduced a point-based action space to mitigate this issue, they fall short in managing more intricate tasks within complex environments. This deficiency arises from their failure to fully exploit the inherent thinking and reasoning capabilities that are fundamental strengths of Vision-Language Models (VLMs). To address these limitations, we propose a novel approach named SpatialCoT, specifically designed to bolster the spatial reasoning capabilities of VLMs. Our approach comprises two stages: spatial coordinate bi-directional alignment, which aligns vision-language inputs with spatial coordinates, and chain-of-thought spatial grounding, which harnesses the reasoning capabilities of language models for advanced spatial reasoning. We evaluate SpatialCoT on challenging navigation and manipulation tasks, both in simulation and real-world settings. Experimental results demonstrate that our method significantly outperforms previous state-of-the-art approaches in both tasks.
UniGaussian: Driving Scene Reconstruction from Multiple Camera Models via Unified Gaussian Representations
Nov 22, 2024



Urban scene reconstruction is crucial for real-world autonomous driving simulators. Although existing methods have achieved photorealistic reconstruction, they mostly focus on pinhole cameras and neglect fisheye cameras. In fact, how to effectively simulate fisheye cameras in driving scene remains an unsolved problem. In this work, we propose UniGaussian, a novel approach that learns a unified 3D Gaussian representation from multiple camera models for urban scene reconstruction in autonomous driving. Our contributions are two-fold. First, we propose a new differentiable rendering method that distorts 3D Gaussians using a series of affine transformations tailored to fisheye camera models. This addresses the compatibility issue of 3D Gaussian splatting with fisheye cameras, which is hindered by light ray distortion caused by lenses or mirrors. Besides, our method maintains real-time rendering while ensuring differentiability. Second, built on the differentiable rendering method, we design a new framework that learns a unified Gaussian representation from multiple camera models. By applying affine transformations to adapt different camera models and regularizing the shared Gaussians with supervision from different modalities, our framework learns a unified 3D Gaussian representation with input data from multiple sources and achieves holistic driving scene understanding. As a result, our approach models multiple sensors (pinhole and fisheye cameras) and modalities (depth, semantic, normal and LiDAR point clouds). Our experiments show that our method achieves superior rendering quality and fast rendering speed for driving scene simulation.
3DArticCyclists: Generating Simulated Dynamic 3D Cyclists for Human-Object Interaction (HOI) and Autonomous Driving Applications
Oct 14, 2024



Human-object interaction (HOI) and human-scene interaction (HSI) are crucial for human-centric scene understanding applications in Embodied Artificial Intelligence (EAI), robotics, and augmented reality (AR). A common limitation faced in these research areas is the data scarcity problem: insufficient labeled human-scene object pairs on the input images, and limited interaction complexity and granularity between them. Recent HOI and HSI methods have addressed this issue by generating dynamic interactions with rigid objects. But more complex dynamic interactions such as a human rider pedaling an articulated bicycle have been unexplored. To address this limitation, and to enable research on complex dynamic human-articulated object interactions, in this paper we propose a method to generate simulated 3D dynamic cyclist assets and interactions. We designed a methodology for creating a new part-based multi-view articulated synthetic 3D bicycle dataset that we call 3DArticBikes that can be used to train NeRF and 3DGS-based 3D reconstruction methods. We then propose a 3DGS-based parametric bicycle composition model to assemble 8-DoF pose-controllable 3D bicycles. Finally, using dynamic information from cyclist videos, we build a complete synthetic dynamic 3D cyclist (rider pedaling a bicycle) by re-posing a selectable synthetic 3D person while automatically placing the rider onto one of our new articulated 3D bicycles using a proposed 3D Keypoint optimization-based Inverse Kinematics pose refinement. We present both, qualitative and quantitative results where we compare our generated cyclists against those from a recent stable diffusion-based method.
AutoSplat: Constrained Gaussian Splatting for Autonomous Driving Scene Reconstruction
Jul 02, 2024



Realistic scene reconstruction and view synthesis are essential for advancing autonomous driving systems by simulating safety-critical scenarios. 3D Gaussian Splatting excels in real-time rendering and static scene reconstructions but struggles with modeling driving scenarios due to complex backgrounds, dynamic objects, and sparse views. We propose AutoSplat, a framework employing Gaussian splatting to achieve highly realistic reconstructions of autonomous driving scenes. By imposing geometric constraints on Gaussians representing the road and sky regions, our method enables multi-view consistent simulation of challenging scenarios including lane changes. Leveraging 3D templates, we introduce a reflected Gaussian consistency constraint to supervise both the visible and unseen side of foreground objects. Moreover, to model the dynamic appearance of foreground objects, we estimate residual spherical harmonics for each foreground Gaussian. Extensive experiments on Pandaset and KITTI demonstrate that AutoSplat outperforms state-of-the-art methods in scene reconstruction and novel view synthesis across diverse driving scenarios. Visit our $\href{https://autosplat.github.io/}{\text{project page}}$.
Learning Effective NeRFs and SDFs Representations with 3D Generative Adversarial Networks for 3D Object Generation: Technical Report for ICCV 2023 OmniObject3D Challenge
Sep 28, 2023



In this technical report, we present a solution for 3D object generation of ICCV 2023 OmniObject3D Challenge. In recent years, 3D object generation has made great process and achieved promising results, but it remains a challenging task due to the difficulty of generating complex, textured and high-fidelity results. To resolve this problem, we study learning effective NeRFs and SDFs representations with 3D Generative Adversarial Networks (GANs) for 3D object generation. Specifically, inspired by recent works, we use the efficient geometry-aware 3D GANs as the backbone incorporating with label embedding and color mapping, which enables to train the model on different taxonomies simultaneously. Then, through a decoder, we aggregate the resulting features to generate Neural Radiance Fields (NeRFs) based representations for rendering high-fidelity synthetic images. Meanwhile, we optimize Signed Distance Functions (SDFs) to effectively represent objects with 3D meshes. Besides, we observe that this model can be effectively trained with only a few images of each object from a variety of classes, instead of using a great number of images per object or training one model per class. With this pipeline, we can optimize an effective model for 3D object generation. This solution is one of the final top-3-place solutions in the ICCV 2023 OmniObject3D Challenge.
GPA-3D: Geometry-aware Prototype Alignment for Unsupervised Domain Adaptive 3D Object Detection from Point Clouds
Aug 16, 2023



LiDAR-based 3D detection has made great progress in recent years. However, the performance of 3D detectors is considerably limited when deployed in unseen environments, owing to the severe domain gap problem. Existing domain adaptive 3D detection methods do not adequately consider the problem of the distributional discrepancy in feature space, thereby hindering generalization of detectors across domains. In this work, we propose a novel unsupervised domain adaptive \textbf{3D} detection framework, namely \textbf{G}eometry-aware \textbf{P}rototype \textbf{A}lignment (\textbf{GPA-3D}), which explicitly leverages the intrinsic geometric relationship from point cloud objects to reduce the feature discrepancy, thus facilitating cross-domain transferring. Specifically, GPA-3D assigns a series of tailored and learnable prototypes to point cloud objects with distinct geometric structures. Each prototype aligns BEV (bird's-eye-view) features derived from corresponding point cloud objects on source and target domains, reducing the distributional discrepancy and achieving better adaptation. The evaluation results obtained on various benchmarks, including Waymo, nuScenes and KITTI, demonstrate the superiority of our GPA-3D over the state-of-the-art approaches for different adaptation scenarios. The MindSpore version code will be publicly available at \url{https://github.com/Liz66666/GPA3D}.