 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Generate High-Quality Test Cases for Algorithm Problems? TestCase-Eval: A Systematic Evaluation of Fault Coverage and Exposure
Jun 13, 2025We introduce TestCase-Eval, a new benchmark for systematic evaluation of LLMs in test-case generation. TestCase-Eval includes 500 algorithm problems and 100,000 human-crafted solutions from the Codeforces platform. It focuses on two pivotal tasks: (1) Fault Coverage, which measures how well LLM-generated test sets probe diverse input scenarios and cover a wide range of potential failure modes. (2) Fault Exposure, which evaluates whether LLMs can craft a tailored test input that reveals a specific incorrect code implementation. We provide a comprehensive assessment of 19 state-of-the-art open-source and proprietary LLMs on TestCase-Eval, offering insights into their strengths and limitations in generating effective test cases for algorithm problems.
Table-R1: Inference-Time Scaling for Table Reasoning
May 29, 2025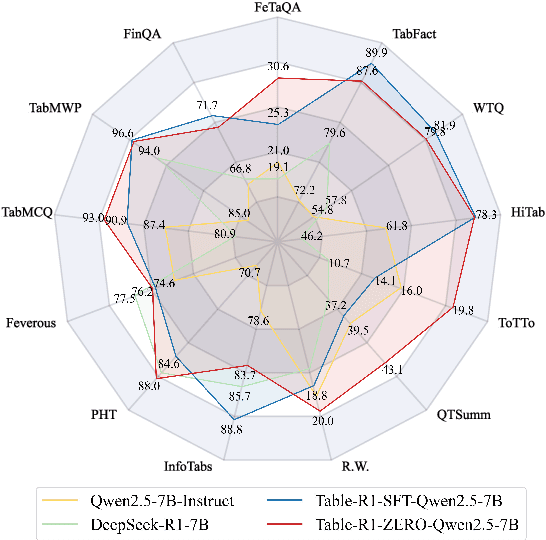



In this work, we present the first study to explore inference-time scaling on table reasoning tasks. We develop and evaluate two post-training strategies to enable inference-time scaling: distillation from frontier model reasoning traces and reinforcement learning with verifiable rewards (RLVR). For distillation, we introduce a large-scale dataset of reasoning traces generated by DeepSeek-R1, which we use to fine-tune LLMs into the Table-R1-SFT model. For RLVR, we propose task-specific verifiable reward functions and apply the GRPO algorithm to obtain the Table-R1-Zero model. We evaluate our Table-R1-series models across diverse table reasoning tasks, including short-form QA, fact verification, and free-form QA. Notably, the Table-R1-Zero model matches or exceeds the performance of GPT-4.1 and DeepSeek-R1, while using only a 7B-parameter LLM. It also demonstrates strong generalization to out-of-domain datasets. Extensive ablation and qualitative analyses reveal the benefits of instruction tuning, model architecture choices, and cross-task generalization, as well as emergence of essential table reasoning skills during RL training.
UniGaussian: Driving Scene Reconstruction from Multiple Camera Models via Unified Gaussian Representations
Nov 22, 2024



Urban scene reconstruction is crucial for real-world autonomous driving simulators. Although existing methods have achieved photorealistic reconstruction, they mostly focus on pinhole cameras and neglect fisheye cameras. In fact, how to effectively simulate fisheye cameras in driving scene remains an unsolved problem. In this work, we propose UniGaussian, a novel approach that learns a unified 3D Gaussian representation from multiple camera models for urban scene reconstruction in autonomous driving. Our contributions are two-fold. First, we propose a new differentiable rendering method that distorts 3D Gaussians using a series of affine transformations tailored to fisheye camera models. This addresses the compatibility issue of 3D Gaussian splatting with fisheye cameras, which is hindered by light ray distortion caused by lenses or mirrors. Besides, our method maintains real-time rendering while ensuring differentiability. Second, built on the differentiable rendering method, we design a new framework that learns a unified Gaussian representation from multiple camera models. By applying affine transformations to adapt different camera models and regularizing the shared Gaussians with supervision from different modalities, our framework learns a unified 3D Gaussian representation with input data from multiple sources and achieves holistic driving scene understanding. As a result, our approach models multiple sensors (pinhole and fisheye cameras) and modalities (depth, semantic, normal and LiDAR point clouds). Our experiments show that our method achieves superior rendering quality and fast rendering speed for driving scene simulation.
VQA-Diff: Exploiting VQA and Diffusion for Zero-Shot Image-to-3D Vehicle Asset Generation in Autonomous Driving
Jul 10, 2024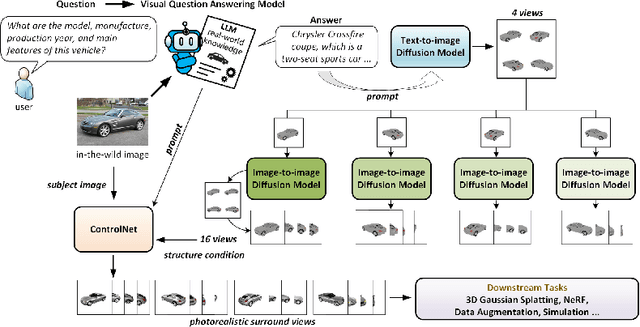
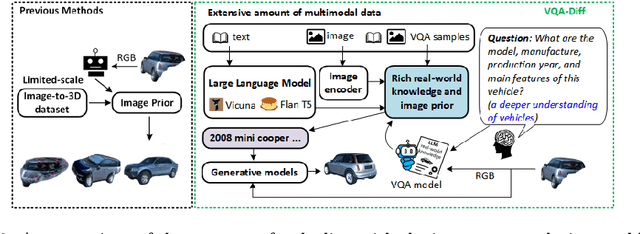
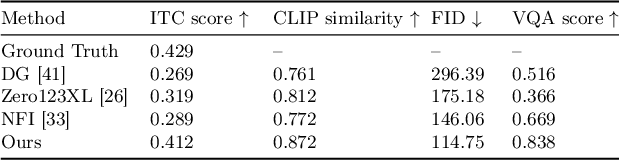
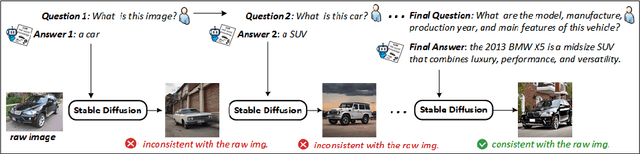
Generating 3D vehicle assets from in-the-wild observations is crucial to autonomous driving. Existing image-to-3D methods cannot well address this problem because they learn generation merely from image RGB information without a deeper understanding of in-the-wild vehicles (such as car models, manufacturers, etc.). This leads to their poor zero-shot prediction capability to handle real-world observations with occlusion or tricky viewing angles. To solve this problem, in this work, we propose VQA-Diff, a novel framework that leverages in-the-wild vehicle images to create photorealistic 3D vehicle assets for autonomous driving. VQA-Diff exploits the real-world knowledge inherited from the Large Language Model in the Visual Question Answering (VQA) model for robust zero-shot prediction and the rich image prior knowledge in the Diffusion model for structure and appearance generation. In particular, we utilize a multi-expert Diffusion Models strategy to generate the structure information and employ a subject-driven structure-controlled generation mechanism to model appearance information. As a result, without the necessity to learn from a large-scale image-to-3D vehicle dataset collected from the real world, VQA-Diff still has a robust zero-shot image-to-novel-view generation ability. We conduct experiments on various datasets, including Pascal 3D+, Waymo, and Objaverse, to demonstrate that VQA-Diff outperforms existing state-of-the-art methods both qualitatively and quantitatively.
Learning Effective NeRFs and SDFs Representations with 3D Generative Adversarial Networks for 3D Object Generation: Technical Report for ICCV 2023 OmniObject3D Challenge
Sep 28, 2023



In this technical report, we present a solution for 3D object generation of ICCV 2023 OmniObject3D Challenge. In recent years, 3D object generation has made great process and achieved promising results, but it remains a challenging task due to the difficulty of generating complex, textured and high-fidelity results. To resolve this problem, we study learning effective NeRFs and SDFs representations with 3D Generative Adversarial Networks (GANs) for 3D object generation. Specifically, inspired by recent works, we use the efficient geometry-aware 3D GANs as the backbone incorporating with label embedding and color mapping, which enables to train the model on different taxonomies simultaneously. Then, through a decoder, we aggregate the resulting features to generate Neural Radiance Fields (NeRFs) based representations for rendering high-fidelity synthetic images. Meanwhile, we optimize Signed Distance Functions (SDFs) to effectively represent objects with 3D meshes. Besides, we observe that this model can be effectively trained with only a few images of each object from a variety of classes, instead of using a great number of images per object or training one model per class. With this pipeline, we can optimize an effective model for 3D object generation. This solution is one of the final top-3-place solutions in the ICCV 2023 OmniObject3D Challenge.
Dynamic Trajectory and Offloading Control of UAV-enabled MEC under User Mobility
May 19, 2021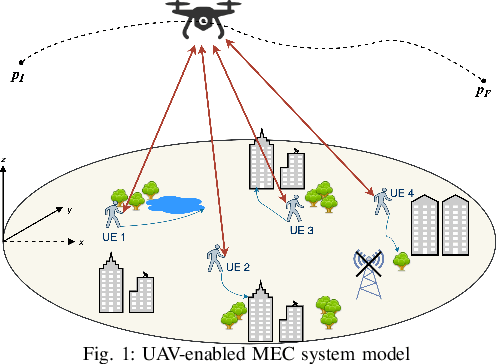
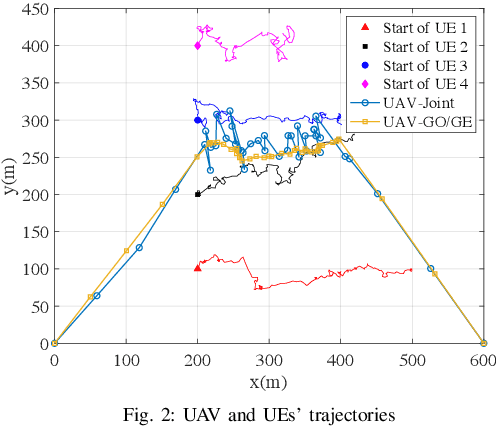
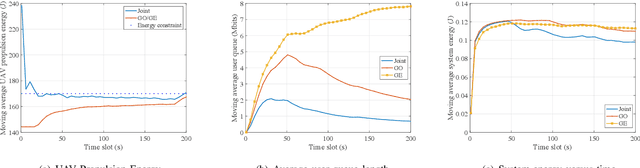
In this paper, we consider a UAV-enabled MEC platform that serves multiple mobile ground users with random movements and task arrivals. We aim to minimize the average weighted energy consumption of all users subject to the average UAV energy consumption and data queue stability constraints. To control the system operation in sequential time slots, we formulate the problem as a multi-stage stochastic optimization, and propose an online algorithm that optimizes the resource allocation and the UAV trajectory in each stage. We adopt Lyapunov optimization to convert the multi-stage stochastic problem into per-slot deterministic problems with much less optimizing variables. To tackle the non-convex per-slot problem, we use the successive convex approximation (SCA) technique to jointly optimize the resource allocation and the UAV movement. Simulation results show that the proposed online algorithm can satisfy the average UAV energy and queue stability constraints, and significantly outperform the other considered benchmark methods in reducing the energy consumption of ground users.