 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQA-Diff: Exploiting VQA and Diffusion for Zero-Shot Image-to-3D Vehicle Asset Generation in Autonomous Driving
Jul 10, 2024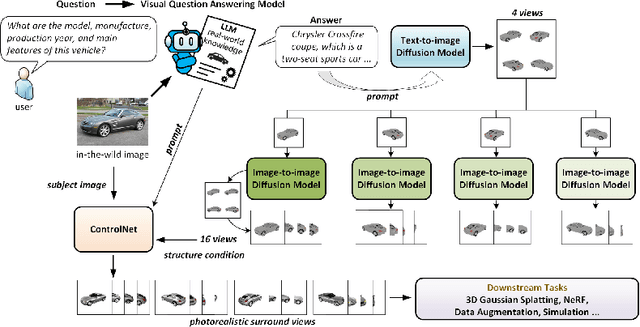
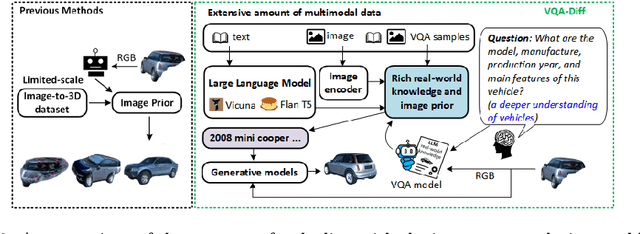
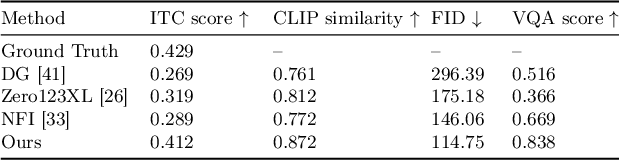
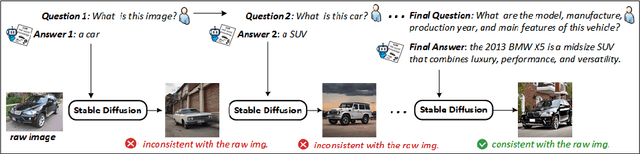
Generating 3D vehicle assets from in-the-wild observations is crucial to autonomous driving. Existing image-to-3D methods cannot well address this problem because they learn generation merely from image RGB information without a deeper understanding of in-the-wild vehicles (such as car models, manufacturers, etc.). This leads to their poor zero-shot prediction capability to handle real-world observations with occlusion or tricky viewing angles. To solve this problem, in this work, we propose VQA-Diff, a novel framework that leverages in-the-wild vehicle images to create photorealistic 3D vehicle assets for autonomous driving. VQA-Diff exploits the real-world knowledge inherited from the Large Language Model in the Visual Question Answering (VQA) model for robust zero-shot prediction and the rich image prior knowledge in the Diffusion model for structure and appearance generation. In particular, we utilize a multi-expert Diffusion Models strategy to generate the structure information and employ a subject-driven structure-controlled generation mechanism to model appearance information. As a result, without the necessity to learn from a large-scale image-to-3D vehicle dataset collected from the real world, VQA-Diff still has a robust zero-shot image-to-novel-view generation ability. We conduct experiments on various datasets, including Pascal 3D+, Waymo, and Objaverse, to demonstrate that VQA-Diff outperforms existing state-of-the-art methods both qualitatively and quantitatively.
L-PR: Exploiting LiDAR Fiducial Marker for Unordered Low Overlap Multiview Point Cloud Registration
Jun 05, 2024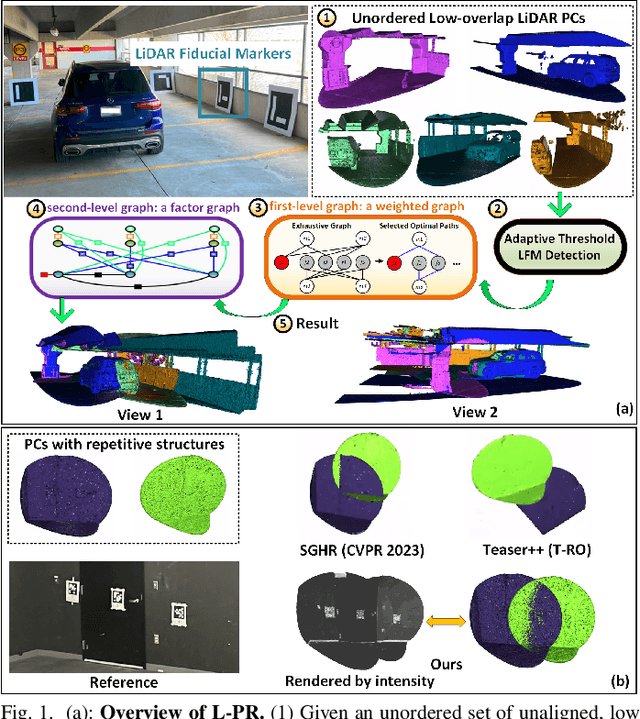



Point cloud registration is a prerequisite for many applications in computer vision and robotics. Most existing methods focus on pairwise registration of two point clouds with high overlap. Although there have been some methods for low overlap cases, they struggle in degraded scenarios. This paper introduces a novel framework named L-PR, designed to register unordered low overlap multiview point clouds leveraging LiDAR fiducial markers. We refer to them as LiDAR fiducial markers, but they are the same as the popular AprilTag and ArUco markers, thin sheets of paper that do not affect the 3D geometry of the environment. We first propose an improved adaptive threshold marker detection method to provide robust detection results when the viewpoints among point clouds change dramatically. Then, we formulate the unordered multiview point cloud registration problem as a maximum a-posteriori (MAP) problem and develop a framework consisting of two levels of graphs to address it. The first-level graph, constructed as a weighted graph, is designed to efficiently and optimally infer initial values of scan poses from the unordered set. The second-level graph is constructed as a factor graph. By globally optimizing the variables on the graph, including scan poses, marker poses, and marker corner positions, we tackle the MAP problem. We conduct qualitative and quantitative experiments to demonstrate that the proposed method exhibits superiority over competitors in four aspects: registration accuracy, instance reconstruction quality, localization accuracy, and robustness to the degraded scene. To benefit the community, we open-source our method and dataset at https://github.com/yorklyb/LiDAR-SFM.