 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNighttime Autonomous Driving Scene Reconstruction with Physically-Based Gaussian Splatting
Feb 14, 2026This paper focuses on scene reconstruction under nighttime conditions in autonomous driving simulation. Recent methods based on Neural Radiance Fields (NeRFs) and 3D Gaussian Splatting (3DGS) have achieved photorealistic modeling in autonomous driving scene reconstruction, but they primarily focus on normal-light conditions. Low-light driving scenes are more challenging to model due to their complex lighting and appearance conditions, which often causes performance degradation of existing methods. To address this problem, this work presents a novel approach that integrates physically based rendering into 3DGS to enhance nighttime scene reconstruction for autonomous driving. Specifically, our approach integrates physically based rendering into composite scene Gaussian representations and jointly optimizes Bidirectional Reflectance Distribution Function (BRDF) based material properties. We explicitly model diffuse components through a global illumination module and specular components by anisotropic spherical Gaussians. As a result, our approach improves reconstruction quality for outdoor nighttime driving scenes, while maintaining real-time rendering. Extensive experiments across diverse nighttime scenarios on two real-world autonomous driving datasets, including nuScenes and Waymo, demonstrate that our approach outperforms the state-of-the-art methods both quantitatively and qualitatively.
Spatial4D-Bench: A Versatile 4D Spatial Intelligence Benchmark
Dec 31, 20254D spatial intelligence involves perceiving and processing how objects move or change over time. Humans naturally possess 4D spatial intelligence, supporting a broad spectrum of spatial reasoning abilities. To what extent can Multimodal Large Language Models (MLLMs) achieve human-level 4D spatial intelligence? In this work, we present Spatial4D-Bench, a versatile 4D spatial intelligence benchmark designed to comprehensively assess the 4D spatial reasoning abilities of MLLMs. Unlike existing spatial intelligence benchmarks that are often small-scale or limited in diversity, Spatial4D-Bench provides a large-scale, multi-task evaluation benchmark consisting of ~40,000 question-answer pairs covering 18 well-defined tasks. We systematically organize these tasks into six cognitive categories: object understanding, scene understanding, spatial relationship understanding, spatiotemporal relationship understanding, spatial reasoning and spatiotemporal reasoning. Spatial4D-Bench thereby offers a structured and comprehensive benchmark for evaluating the spatial cognition abilities of MLLMs, covering a broad spectrum of tasks that parallel the versatility of human spatial intelligence. We benchmark various state-of-the-art open-source and proprietary MLLMs on Spatial4D-Bench and reveal their substantial limitations in a wide variety of 4D spatial reasoning aspects, such as route plan, action recognition, and physical plausibility reasoning. We hope that the findings provided in this work offer valuable insights to the community and that our benchmark can facilitate the development of more capable MLLMs toward human-level 4D spatial intelligence. More resources can be found on our project page.
UniGaussian: Driving Scene Reconstruction from Multiple Camera Models via Unified Gaussian Representations
Nov 22, 2024



Urban scene reconstruction is crucial for real-world autonomous driving simulators. Although existing methods have achieved photorealistic reconstruction, they mostly focus on pinhole cameras and neglect fisheye cameras. In fact, how to effectively simulate fisheye cameras in driving scene remains an unsolved problem. In this work, we propose UniGaussian, a novel approach that learns a unified 3D Gaussian representation from multiple camera models for urban scene reconstruction in autonomous driving. Our contributions are two-fold. First, we propose a new differentiable rendering method that distorts 3D Gaussians using a series of affine transformations tailored to fisheye camera models. This addresses the compatibility issue of 3D Gaussian splatting with fisheye cameras, which is hindered by light ray distortion caused by lenses or mirrors. Besides, our method maintains real-time rendering while ensuring differentiability. Second, built on the differentiable rendering method, we design a new framework that learns a unified Gaussian representation from multiple camera models. By applying affine transformations to adapt different camera models and regularizing the shared Gaussians with supervision from different modalities, our framework learns a unified 3D Gaussian representation with input data from multiple sources and achieves holistic driving scene understanding. As a result, our approach models multiple sensors (pinhole and fisheye cameras) and modalities (depth, semantic, normal and LiDAR point clouds). Our experiments show that our method achieves superior rendering quality and fast rendering speed for driving scene simulation.
Domain Adaptation in 3D Object Detection with Gradual Batch Alternation Training
Oct 18, 2022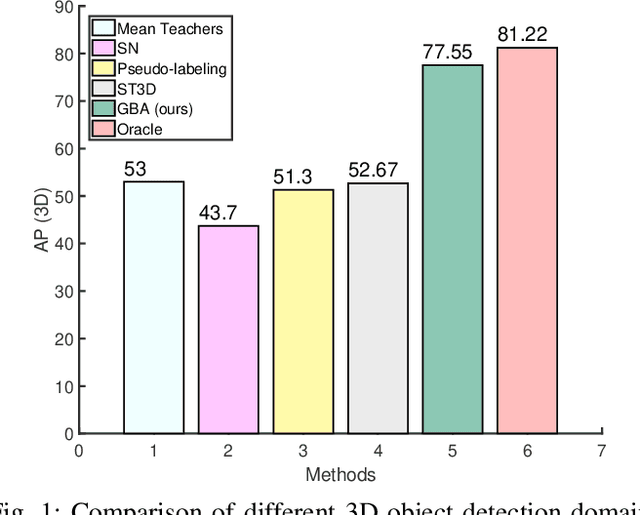
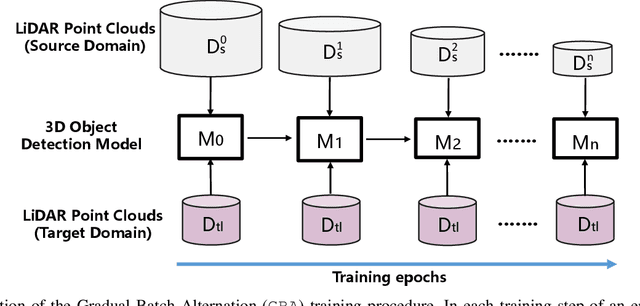
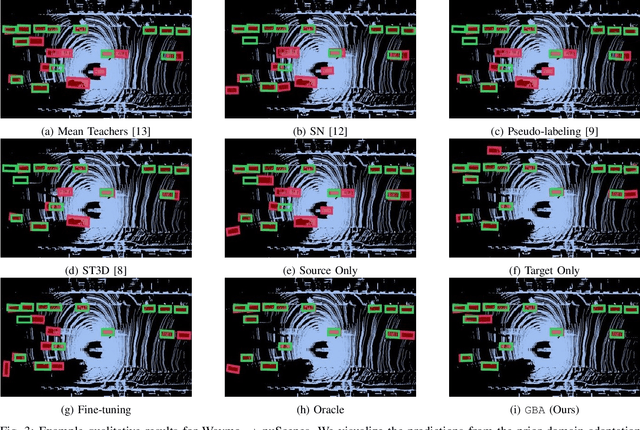
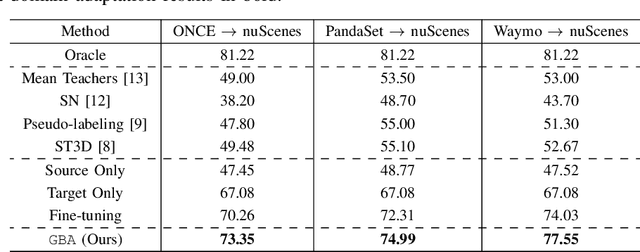
We consider the problem of domain adaptation in LiDAR-based 3D object detection. Towards this, we propose a simple yet effective training strategy called Gradual Batch Alternation that can adapt from a large labeled source domain to an insufficiently labeled target domain. The idea is to initiate the training with the batch of samples from the source and target domain data in an alternate fashion, but then gradually reduce the amount of the source domain data over time as the training progresses. This way the model slowly shifts towards the target domain and eventually better adapt to it. The domain adaptation experiments for 3D object detection on four benchmark autonomous driving datasets, namely ONCE, PandaSet, Waymo, and nuScenes, demonstrate significant performance gains over prior arts and strong baselines.
A Spontaneous Driver Emotion Facial Expression (DEFE) Dataset for Intelligent Vehicles
Apr 26, 2020
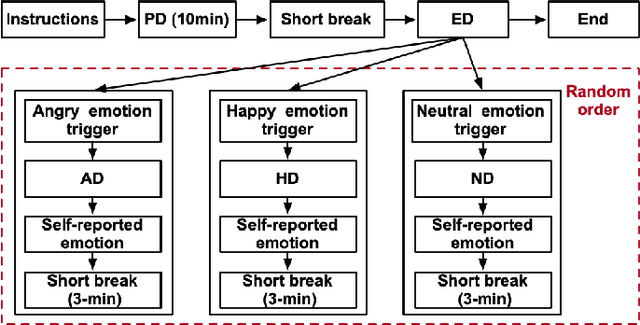

In this paper, we introduce a new dataset, the driver emotion facial expression (DEFE) dataset, for driver spontaneous emotions analysis. The dataset includes facial expression recordings from 60 participants during driving. After watching a selected video-audio clip to elicit a specific emotion, each participant completed the driving tasks in the same driving scenario and rated their emotional responses during the driving processes from the aspects of dimensional emotion and discrete emotion. We also conducted classification experiments to recognize the scales of arousal, valence, dominance, as well as the emotion category and intensity to establish baseline results for the proposed dataset. Besides, this paper compared and discussed the differences in facial expressions between driving and non-driving scenarios. The results show that there were significant differences in AUs (Action Units) presence of facial expressions between driving and non-driving scenarios, indicating that human emotional expressions in driving scenarios were different from other life scenarios. Therefore, publishing a human emotion dataset specifically for the driver is necessary for traffic safety improvement. The proposed dataset will be publicly available so that researchers worldwide can use it to develop and examine their driver emotion analysis methods. To the best of our knowledge, this is currently the only public driver facial expression dataset.