 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnMA-CapSumT: Unified and Multi-Head Attention-driven Caption Summarization Transformer
Dec 16, 2024



Image captioning is the generation of natural language descriptions of images which have increased immense popularity in the recent past. With this different deep-learning techniques are devised for the development of factual and stylized image captioning models. Previous models focused more on the generation of factual and stylized captions separately providing more than one caption for a single image. The descriptions generated from these suffer from out-of-vocabulary and repetition issues. To the best of our knowledge, no such work exists that provided a description that integrates different captioning methods to describe the contents of an image with factual and stylized (romantic and humorous) elements. To overcome these limitations, this paper presents a novel Unified Attention and Multi-Head Attention-driven Caption Summarization Transformer (UnMA-CapSumT) based Captioning Framework. It utilizes both factual captions and stylized captions generated by the Modified Adaptive Attention-based factual image captioning model (MAA-FIC) and Style Factored Bi-LSTM with attention (SF-Bi-ALSTM) driven stylized image captioning model respectively. SF-Bi-ALSTM-based stylized IC model generates two prominent styles of expression- {romance, and humor}. The proposed summarizer UnMHA-ST combines both factual and stylized descriptions of an input image to generate styled rich coherent summarized captions. The proposed UnMHA-ST transformer learns and summarizes different linguistic styles efficiently by incorporating proposed word embedding fastText with Attention Word Embedding (fTA-WE) and pointer-generator network with coverage mechanism concept to solve the out-of-vocabulary issues and repetition problem. Extensive experiments are conducted on Flickr8K and a subset of FlickrStyle10K with supporting ablation studies to prove the efficiency and efficacy of the proposed framework.
Multi-Class Abnormality Classification Task in Video Capsule Endoscopy
Oct 25, 2024


In this work we addressed the challenge of multi-class anomaly classification in Video Capsule Endoscopy (VCE)[1] with a variety of deep learning models, ranging from custom CNNs to advanced transformer architectures. The purpose is to correctly classify diverse gastrointestinal disorders, which is critical for increasing diagnostic efficiency in clinical settings. We started with a proprietary CNN and improved performance with ResNet[7] for better feature extraction, followed by Vision Transformer (ViT)[2] to capture global dependencies. Multiscale Vision Transformer (MViT)[6] improved hierarchical feature extraction, while Dual Attention Vision Transformer (DaViT)[4] delivered cutting-edge results by combining spatial and channel attention methods. This methodology enabled us to improve model accuracy across a wide range of criteria, greatly surpassing older methods.
AutoSplat: Constrained Gaussian Splatting for Autonomous Driving Scene Reconstruction
Jul 02, 2024



Realistic scene reconstruction and view synthesis are essential for advancing autonomous driving systems by simulating safety-critical scenarios. 3D Gaussian Splatting excels in real-time rendering and static scene reconstructions but struggles with modeling driving scenarios due to complex backgrounds, dynamic objects, and sparse views. We propose AutoSplat, a framework employing Gaussian splatting to achieve highly realistic reconstructions of autonomous driving scenes. By imposing geometric constraints on Gaussians representing the road and sky regions, our method enables multi-view consistent simulation of challenging scenarios including lane changes. Leveraging 3D templates, we introduce a reflected Gaussian consistency constraint to supervise both the visible and unseen side of foreground objects. Moreover, to model the dynamic appearance of foreground objects, we estimate residual spherical harmonics for each foreground Gaussian. Extensive experiments on Pandaset and KITTI demonstrate that AutoSplat outperforms state-of-the-art methods in scene reconstruction and novel view synthesis across diverse driving scenarios. Visit our $\href{https://autosplat.github.io/}{\text{project page}}$.
Augmenting Imitation Experience via Equivariant Representations
Oct 14, 2021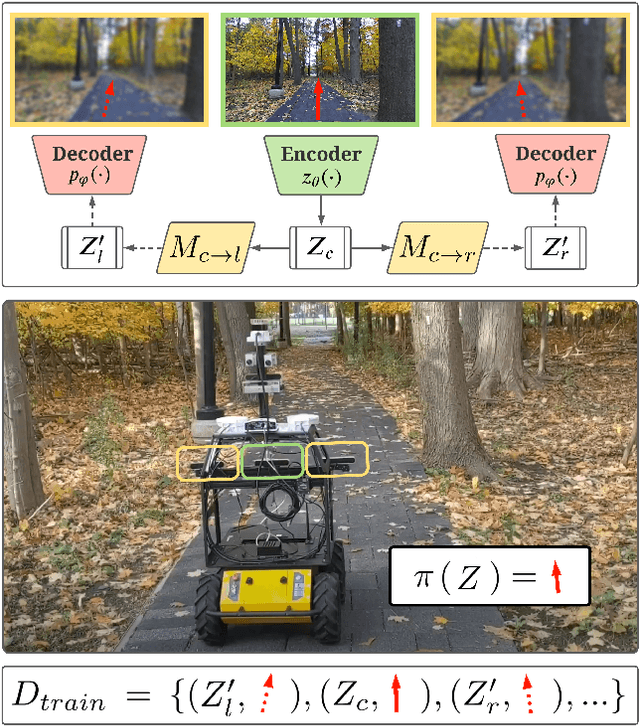
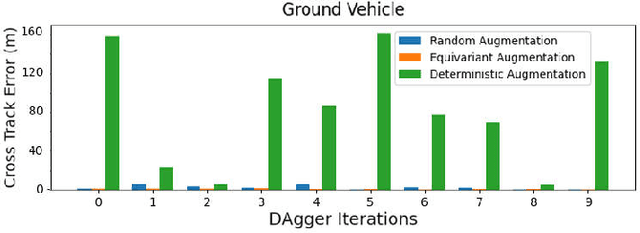
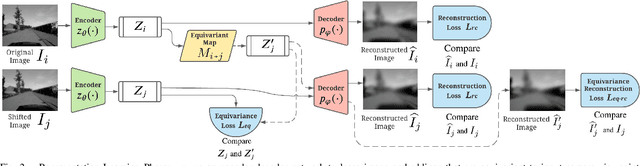

The robustness of visual navigation policies trained through imitation often hinges on the augmentation of the training image-action pairs. Traditionally, this has been done by collecting data from multiple cameras, by using standard data augmentations from computer vision, such as adding random noise to each image, or by synthesizing training images. In this paper we show that there is another practical alternative for data augmentation for visual navigation based on extrapolating viewpoint embeddings and actions nearby the ones observed in the training data. Our method makes use of the geometry of the visual navigation problem in 2D and 3D and relies on policies that are functions of equivariant embeddings, as opposed to images. Given an image-action pair from a training navigation dataset, our neural network model predicts the latent representations of images at nearby viewpoints, using the equivariance property, and augments the dataset. We then train a policy on the augmented dataset. Our simulation results indicate that policies trained in this way exhibit reduced cross-track error, and require fewer interventions compared to policies trained using standard augmentation methods. We also show similar results in autonomous visual navigation by a real ground robot along a path of over 500m.
Facial Recognition with Encoded Local Projections
Sep 11, 2018
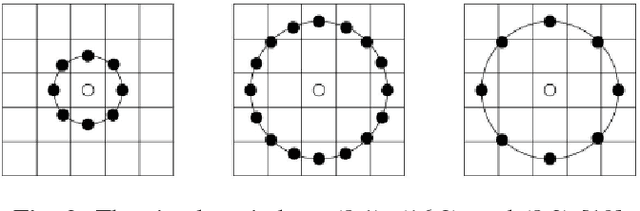

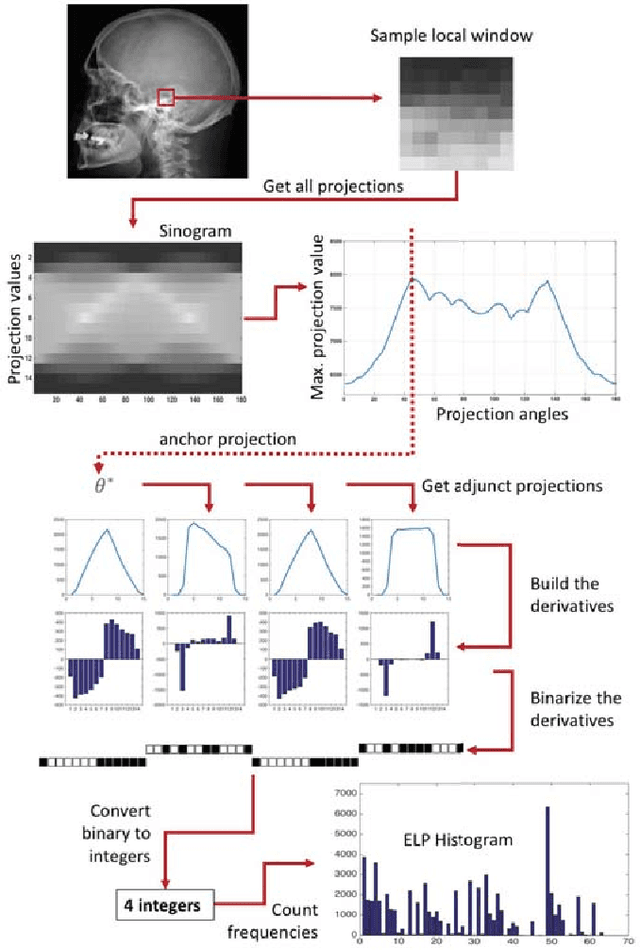
Encoded Local Projections (ELP) is a recently introduced dense sampling image descriptor which uses projections in small neighbourhoods to construct a histogram/descriptor for the entire image. ELP has shown to be as accurate as other state-of-the-art features in searching medical images while being time and resource efficient. This paper attempts for the first time to utilize ELP descriptor as primary features for facial recognition and compare the results with LBP histogram on the Labeled Faces in the Wild dataset. We have evaluated descriptors by comparing the chi-squared distance of each image descriptor versus all others as well as training Support Vector Machines (SVM) with each feature vector. In both cases, the results of ELP were better than LBP in the same sub-image configuration.