 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Imitation Experience via Equivariant Representations
Paper and Code
Oct 14, 2021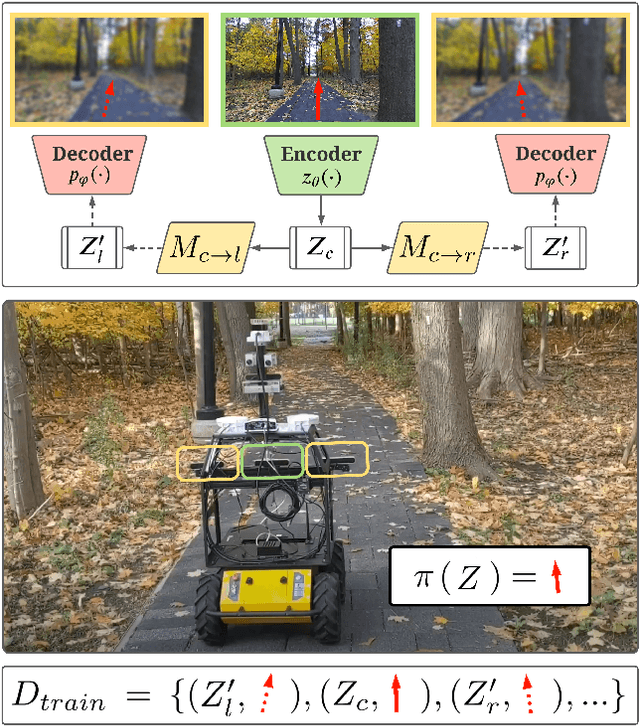
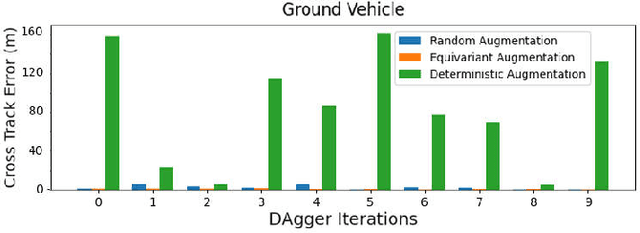
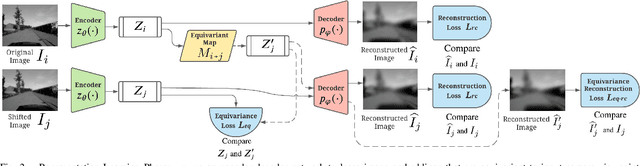

The robustness of visual navigation policies trained through imitation often hinges on the augmentation of the training image-action pairs. Traditionally, this has been done by collecting data from multiple cameras, by using standard data augmentations from computer vision, such as adding random noise to each image, or by synthesizing training images. In this paper we show that there is another practical alternative for data augmentation for visual navigation based on extrapolating viewpoint embeddings and actions nearby the ones observed in the training data. Our method makes use of the geometry of the visual navigation problem in 2D and 3D and relies on policies that are functions of equivariant embeddings, as opposed to images. Given an image-action pair from a training navigation dataset, our neural network model predicts the latent representations of images at nearby viewpoints, using the equivariance property, and augments the dataset. We then train a policy on the augmented dataset. Our simulation results indicate that policies trained in this way exhibit reduced cross-track error, and require fewer interventions compared to policies trained using standard augmentation methods. We also show similar results in autonomous visual navigation by a real ground robot along a path of over 500m.