 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign and Implementation of a Dual Uncrewed Surface Vessel Platform for Bathymetry Research under High-flow Conditions
Feb 18, 2025



Bathymetry, the study of underwater topography, relies on sonar mapping of submerged structures. These measurements, critical for infrastructure health monitoring, often require expensive instrumentation. The high financial risk associated with sensor damage or vessel loss creates a reluctance to deploy uncrewed surface vessels (USVs) for bathymetry. However, the crewed-boat bathymetry operations, are costly, pose hazards to personnel, and frequently fail to achieve the stable conditions necessary for bathymetry data collection, especially under high currents. Further research is essential to advance autonomous control, navigation, and data processing technologies, with a particular focus on bathymetry. There is a notable lack of accessible hardware platforms that allow for integrated research in both bathymetry-focused autonomous control and navigation, as well as data evaluation and processing. This paper addresses this gap through the design and implementation of two complementary USV systems tailored for uncrewed bathymetry research. This includes a low-cost USV for Navigation And Control research (NAC-USV) and a second, high-end USV equipped with a high-resolution multi-beam sonar and the associated hardware for Bathymetry data quality Evaluation and Post-processing research (BEP-USV). The NAC-USV facilitates the investigation of autonomous, fail-safe navigation and control, emphasizing the stability requirements for high-quality bathymetry data collection while minimizing the risk to equipment. The BEP-USV, which mirrors the NAC-USV hardware, is then used for additional control validation and in-depth exploration of bathymetry data evaluation and post-processing methodologies. We detail the design and implementation of both systems, and open source the design. Furthermore, we demonstrate the system's effectiveness in a range of operational scenarios.
UnMA-CapSumT: Unified and Multi-Head Attention-driven Caption Summarization Transformer
Dec 16, 2024



Image captioning is the generation of natural language descriptions of images which have increased immense popularity in the recent past. With this different deep-learning techniques are devised for the development of factual and stylized image captioning models. Previous models focused more on the generation of factual and stylized captions separately providing more than one caption for a single image. The descriptions generated from these suffer from out-of-vocabulary and repetition issues. To the best of our knowledge, no such work exists that provided a description that integrates different captioning methods to describe the contents of an image with factual and stylized (romantic and humorous) elements. To overcome these limitations, this paper presents a novel Unified Attention and Multi-Head Attention-driven Caption Summarization Transformer (UnMA-CapSumT) based Captioning Framework. It utilizes both factual captions and stylized captions generated by the Modified Adaptive Attention-based factual image captioning model (MAA-FIC) and Style Factored Bi-LSTM with attention (SF-Bi-ALSTM) driven stylized image captioning model respectively. SF-Bi-ALSTM-based stylized IC model generates two prominent styles of expression- {romance, and humor}. The proposed summarizer UnMHA-ST combines both factual and stylized descriptions of an input image to generate styled rich coherent summarized captions. The proposed UnMHA-ST transformer learns and summarizes different linguistic styles efficiently by incorporating proposed word embedding fastText with Attention Word Embedding (fTA-WE) and pointer-generator network with coverage mechanism concept to solve the out-of-vocabulary issues and repetition problem. Extensive experiments are conducted on Flickr8K and a subset of FlickrStyle10K with supporting ablation studies to prove the efficiency and efficacy of the proposed framework.
Evaluating Sugarcane Yield Variability with UAV-Derived Cane Height under Different Water and Nitrogen Conditions
Oct 28, 2024This study investigates the relationship between sugarcane yield and cane height derived under different water and nitrogen conditions from pre-harvest Digital Surface Model (DSM) obtained via Unmanned Aerial Vehicle (UAV) flights over a sugarcane test farm. The farm was divided into 62 blocks based on three water levels (low, medium, and high) and three nitrogen levels (low, medium, and high), with repeated treatments. In pixel distribution of DSM for each block, it provided bimodal distribution representing two peaks, ground level (gaps within canopies) and top of the canopies respectively. Using bimodal distribution, mean cane height was extracted for each block by applying a trimmed mean to the pixel distribution, focusing on the top canopy points. Similarly, the extracted mean elevation of the base was derived from the bottom points, representing ground level. The Derived Cane Height Model (DCHM) was generated by taking the difference between the mean canopy height and mean base elevation for each block. Yield measurements (tons/acre) were recorded post-harvest for each block. By aggregating the data into nine treatment zones (e.g., high water-low nitrogen, low water-high nitrogen), the DCHM and median yield were calculated for each zone. The regression analysis between the DCHM and corresponding yields for the different treatment zones yielded an R 2 of 0.95. This study demonstrates the significant impact of water and nitrogen treatments on sugarcane height and yield, utilizing one-time UAV-derived DSM data.
Physics-Informed Multi-Stage Deep Learning Framework Development for Digital Twin-Centred State-Based Reactor Power Prediction
Nov 24, 2022



Computationally efficient and trustworthy machine learning algorithms are necessary for Digital Twin (DT) framework development. Generally speaking, DT-enabling technologies consist of five major components: (i) Machine learning (ML)-driven prediction algorithm, (ii) Temporal synchronization between physics and digital assets utilizing advanced sensors/instrumentation, (iii) uncertainty propagation, and (iv) DT operational framework. Unfortunately, there is still a significant gap in developing those components for nuclear plant operation. In order to address this gap, this study specifically focuses on the "ML-driven prediction algorithms" as a viable component for the nuclear reactor operation while assessing the reliability and efficacy of the proposed model. Therefore, as a DT prediction component, this study develops a multi-stage predictive model consisting of two feedforward Deep Learning using Neural Networks (DNNs) to determine the final steady-state power of a reactor transient for a nuclear reactor/plant. The goal of the multi-stage model architecture is to convert probabilistic classification to continuous output variables to improve reliability and ease of analysis. Four regression models are developed and tested with input from the first stage model to predict a single value representing the reactor power output. The combined model yields 96% classification accuracy for the first stage and 92% absolute prediction accuracy for the second stage. The development procedure is discussed so that the method can be applied generally to similar systems. An analysis of the role similar models would fill in DTs is performed.
Uncertainty Quantification and Sensitivity analysis for Digital Twin Enabling Technology: Application for BISON Fuel Performance Code
Oct 14, 2022
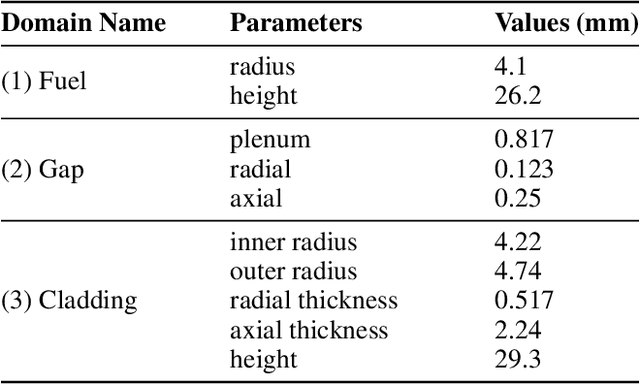

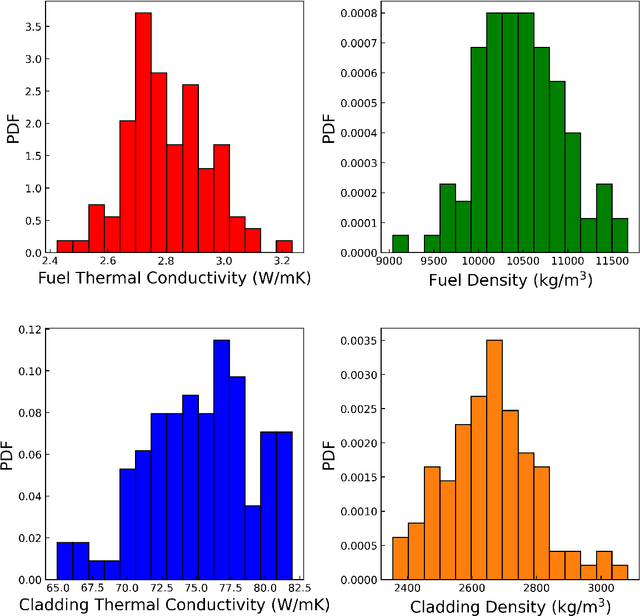
To understand the potential of intelligent confirmatory tools, the U.S. Nuclear Regulatory Committee (NRC) initiated a future-focused research project to assess the regulatory viability of machine learning (ML) and artificial intelligence (AI)-driven Digital Twins (DTs) for nuclear power applications. Advanced accident tolerant fuel (ATF) is one of the priority focus areas of the U.S. Department of Energy (DOE). A DT framework can offer game-changing yet practical and informed solutions to the complex problem of qualifying advanced ATFs. Considering the regulatory standpoint of the modeling and simulation (M&S) aspect of DT, uncertainty quantification and sensitivity analysis are paramount to the DT framework's success in terms of multi-criteria and risk-informed decision-making. This chapter introduces the ML-based uncertainty quantification and sensitivity analysis methods while exhibiting actual applications to the finite element-based nuclear fuel performance code BISON.
Leveraging Industry 4.0 -- Deep Learning, Surrogate Model and Transfer Learning with Uncertainty Quantification Incorporated into Digital Twin for Nuclear System
Sep 30, 2022Industry 4.0 targets the conversion of the traditional industries into intelligent ones through technological revolution. This revolution is only possible through innovation, optimization, interconnection, and rapid decision-making capability. Numerical models are believed to be the key components of Industry 4.0, facilitating quick decision-making through simulations instead of costly experiments. However, numerical investigation of precise, high-fidelity models for optimization or decision-making is usually time-consuming and computationally expensive. In such instances, data-driven surrogate models are excellent substitutes for fast computational analysis and the probabilistic prediction of the output parameter for new input parameters. The emergence of Internet of Things (IoT) and Machine Learning (ML) has made the concept of surrogate modeling even more viable. However, these surrogate models contain intrinsic uncertainties, originate from modeling defects, or both. These uncertainties, if not quantified and minimized, can produce a skewed result. Therefore, proper implementation of uncertainty quantification techniques is crucial during optimization, cost reduction, or safety enhancement processes analysis. This chapter begins with a brief overview of the concept of surrogate modeling, transfer learning, IoT and digital twins. After that, a detailed overview of uncertainties, uncertainty quantification frameworks, and specifics of uncertainty quantification methodologies for a surrogate model linked to a digital twin is presented. Finally, the use of uncertainty quantification approaches in the nuclear industry has been addressed.
Digital Twin and Artificial Intelligence Incorporated With Surrogate Modeling for Hybrid and Sustainable Energy Systems
Sep 30, 2022
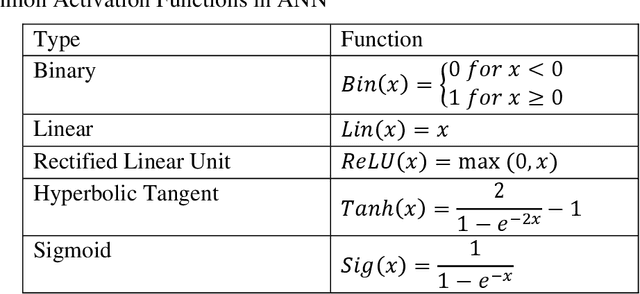
Surrogate modeling has brought about a revolution in computation in the branches of science and engineering. Backed by Artificial Intelligence, a surrogate model can present highly accurate results with a significant reduction in computation time than computer simulation of actual models. Surrogate modeling techniques have found their use in numerous branches of science and engineering, energy system modeling being one of them. Since the idea of hybrid and sustainable energy systems is spreading rapidly in the modern world for the paradigm of the smart energy shift, researchers are exploring the future application of artificial intelligence-based surrogate modeling in analyzing and optimizing hybrid energy systems. One of the promising technologies for assessing applicability for the energy system is the digital twin, which can leverage surrogate modeling. This work presents a comprehensive framework/review on Artificial Intelligence-driven surrogate modeling and its applications with a focus on the digital twin framework and energy systems. The role of machine learning and artificial intelligence in constructing an effective surrogate model is explained. After that, different surrogate models developed for different sustainable energy sources are presented. Finally, digital twin surrogate models and associated uncertainties are described.
Machine Learning and Artificial Intelligence-Driven Multi-Scale Modeling for High Burnup Accident-Tolerant Fuels for Light Water-Based SMR Applications
Sep 25, 2022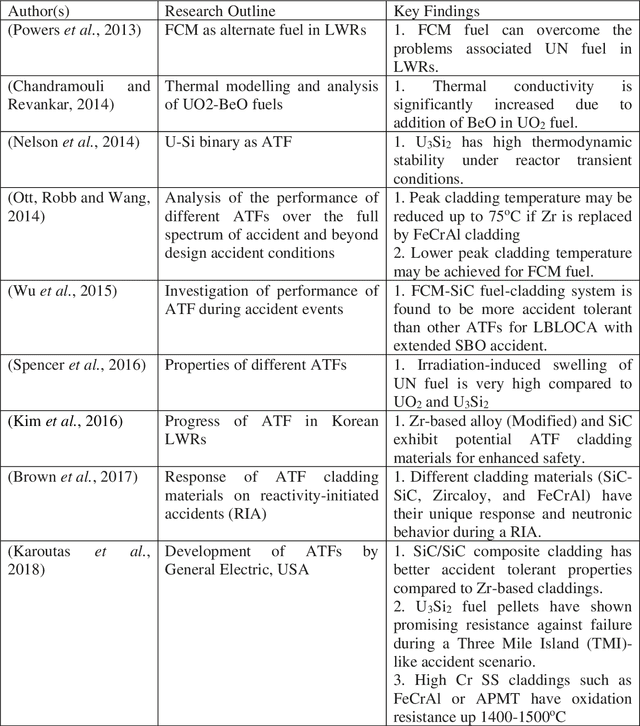

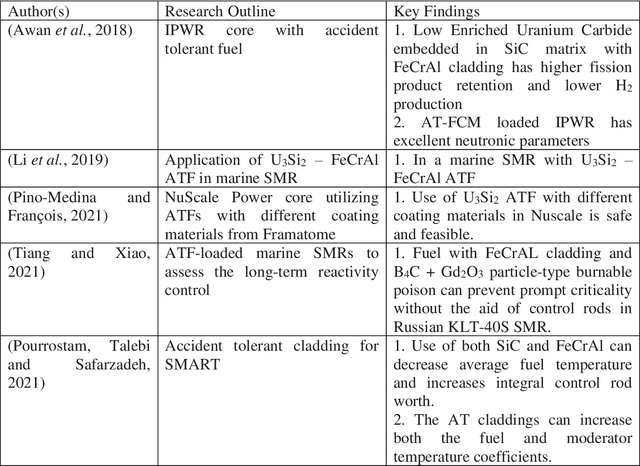
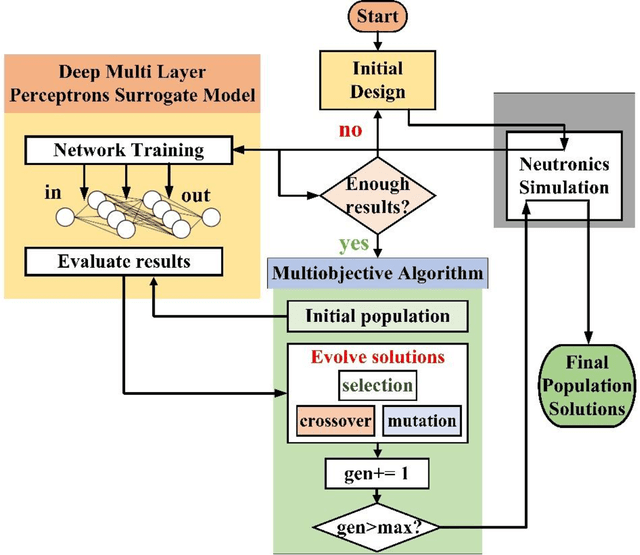
The concept of small modular reactor has changed the outlook for tackling future energy crises. This new reactor technology is very promising considering its lower investment requirements, modularity, design simplicity, and enhanced safety features. The application of artificial intelligence-driven multi-scale modeling (neutronics, thermal hydraulics, fuel performance, etc.) incorporating Digital Twin and associated uncertainties in the research of small modular reactors is a recent concept. In this work, a comprehensive study is conducted on the multiscale modeling of accident-tolerant fuels. The application of these fuels in the light water-based small modular reactors is explored. This chapter also focuses on the application of machine learning and artificial intelligence in the design optimization, control, and monitoring of small modular reactors. Finally, a brief assessment of the research gap on the application of artificial intelligence to the development of high burnup composite accident-tolerant fuels is provided. Necessary actions to fulfill these gaps are also discussed.
Which Generative Adversarial Network Yields High-Quality Synthetic Medical Images: Investigation Using AMD Image Datasets
Mar 25, 2022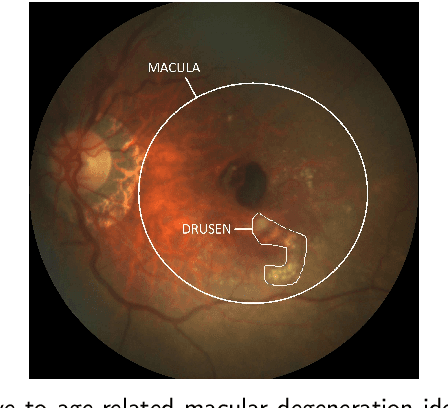
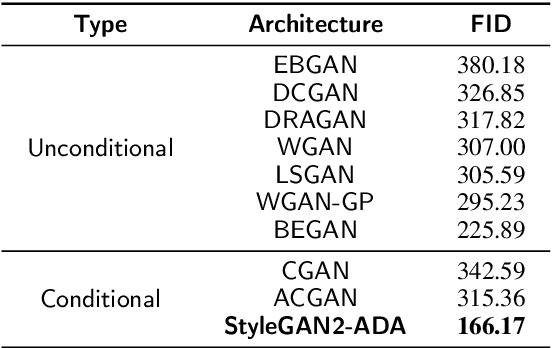

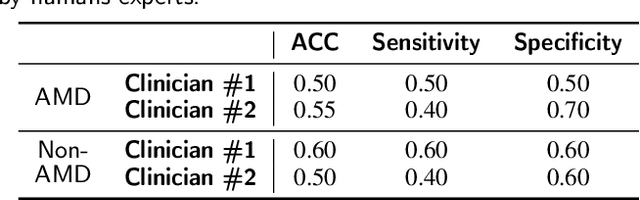
Deep learning has been proposed for the assessment and classification of medical images. However, many medical image databases with appropriately labeled and annotated images are small and imbalanced, and thus unsuitable to train and validate such models. The option is to generate synthetic images and one successful technique has been patented which limits its use for others. We have developed a free-access, alternate method for generating synthetic high-resolution images using Generative Adversarial Networks (GAN) for data augmentation and showed their effectiveness using eye-fundus images for Age-Related Macular Degeneration (AMD) identification. Ten different GAN architectures were compared to generate synthetic eye-fundus images with and without AMD. Data from three public databases were evaluated using the Fr\'echet Inception Distance (FID), two clinical experts and deep-learning classification. The results show that StyleGAN2 reached the lowest FID (166.17), and clinicians could not accurately differentiate between real and synthetic images. ResNet-18 architecture obtained the best performance with 85% accuracy and outperformed the two experts in detecting AMD fundus images, whose average accuracy was 77.5%. These results are similar to a recently patented method, and will provide an alternative to generating high-quality synthetic medical images. Free access has been provided to the entire method to facilitate the further development of this field.
Non-image Data Classification with Convolutional Neural Networks
Jul 07, 2020

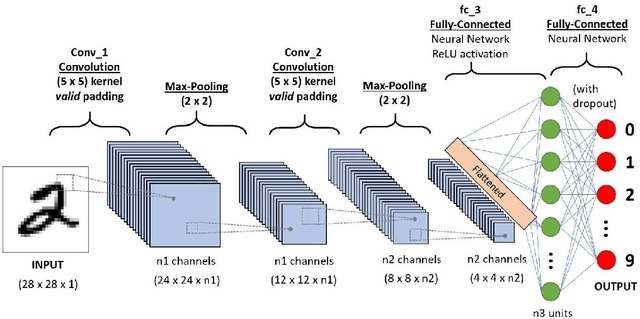
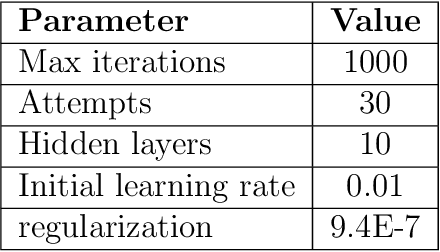
Convolutional Neural Networks (CNNs) is one of the most popular algorithms for deep learning which is mostly used for image classification, natural language processing, and time series forecasting. Its ability to extract and recognize the fine features has led to the state-of-the-art performance. CNN has been designed to work on a set of 2-D matrices whose elements show some correlation with neighboring elements such as in image data. Conversely, the data examples represented as a set of 1-D vectors -- apart from time series data -- cannot be used with CNN, but with other Artificial Neural Networks (ANNs). We have proposed some novel preprocessing methods of data wrangling that transform a 1-D data vector to a 2-D graphical image with appropriate correlations among the fields to be processed on CNN. To our knowledge this work is novel on non-image to image data transformation for non-time series data. The transformed data processed with CNN using VGGnet-16 shows a competitive result in classification accuracy compared to canonical ANN approach with high potential for further improvements.