 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Distribution-based Curriculum Learning
Feb 12, 2024The order of training samples can have a significant impact on the performance of a classifier. Curriculum learning is a method of ordering training samples from easy to hard. This paper proposes the novel idea of a curriculum learning approach called Data Distribution-based Curriculum Learning (DDCL). DDCL uses the data distribution of a dataset to build a curriculum based on the order of samples. Two types of scoring methods known as DDCL (Density) and DDCL (Point) are used to score training samples thus determining their training order. DDCL (Density) uses the sample density to assign scores while DDCL (Point) utilises the Euclidean distance for scoring. We evaluate the proposed DDCL approach by conducting experiments on multiple datasets using a neural network, support vector machine and random forest classifier. Evaluation results show that the application of DDCL improves the average classification accuracy for all datasets compared to standard evaluation without any curriculum. Moreover, analysis of the error losses for a single training epoch reveals that convergence is faster when using DDCL over the no curriculum method.
SMOTified-GAN for class imbalanced pattern classification problems
Aug 06, 2021
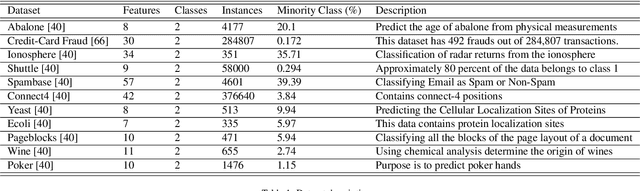


Class imbalance in a dataset is a major problem for classifiers that results in poor prediction with a high true positive rate (TPR) but a low true negative rate (TNR) for a majority positive training dataset. Generally, the pre-processing technique of oversampling of minority class(es) are used to overcome this deficiency. Our focus is on using the hybridization of Generative Adversarial Network (GAN) and Synthetic Minority Over-Sampling Technique (SMOTE) to address class imbalanced problems. We propose a novel two-phase oversampling approach that has the synergy of SMOTE and GAN. The initial data of minority class(es) generated by SMOTE is further enhanced by GAN that produces better quality samples. We named it SMOTified-GAN as GAN works on pre-sampled minority data produced by SMOTE rather than randomly generating the samples itself. The experimental results prove the sample quality of minority class(es) has been improved in a variety of tested benchmark datasets. Its performance is improved by up to 9\% from the next best algorithm tested on F1-score measurements. Its time complexity is also reasonable which is around $O(N^2d^2T)$ for a sequential algorithm.
Guided parallelized stochastic gradient descent for delay compensation
Jan 17, 2021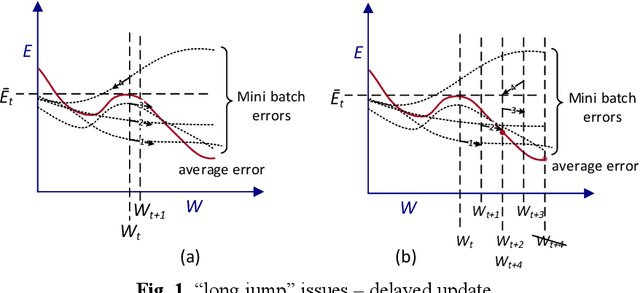



Stochastic gradient descent (SGD) algorithm and its variations have been effectively used to optimize neural network models. However, with the rapid growth of big data and deep learning, SGD is no longer the most suitable choice due to its natural behavior of sequential optimization of the error function. This has led to the development of parallel SGD algorithms, such as asynchronous SGD (ASGD) and synchronous SGD (SSGD) to train deep neural networks. However, it introduces a high variance due to the delay in parameter (weight) update. We address this delay in our proposed algorithm and try to minimize its impact. We employed guided SGD (gSGD) that encourages consistent examples to steer the convergence by compensating the unpredictable deviation caused by the delay. Its convergence rate is also similar to A/SSGD, however, some additional (parallel) processing is required to compensate for the delay. The experimental results demonstrate that our proposed approach has been able to mitigate the impact of delay for the quality of classification accuracy. The guided approach with SSGD clearly outperforms sequential SGD and even achieves the accuracy close to sequential SGD for some benchmark datasets.
* This is a preprint version
Optimistic variants of single-objective bilevel optimization for evolutionary algorithms
Aug 22, 2020



Single-objective bilevel optimization is a specialized form of constraint optimization problems where one of the constraints is an optimization problem itself. These problems are typically non-convex and strongly NP-Hard. Recently, there has been an increased interest from the evolutionary computation community to model bilevel problems due to its applicability in the real-world applications for decision-making problems. In this work, a partial nested evolutionary approach with a local heuristic search has been proposed to solve the benchmark problems and have outstanding results. This approach relies on the concept of intermarriage-crossover in search of feasible regions by exploiting information from the constraints. A new variant has also been proposed to the commonly used convergence approaches, i.e., optimistic and pessimistic. It is called extreme optimistic approach. The experimental results demonstrate the algorithm converges differently to known optimum solutions with the optimistic variants. Optimistic approach also outperforms pessimistic approach. Comparative statistical analysis of our approach with other recently published partial to complete evolutionary approaches demonstrates very competitive results.
* preprint: 15 pages, published: 20 pages
Non-image Data Classification with Convolutional Neural Networks
Jul 07, 2020

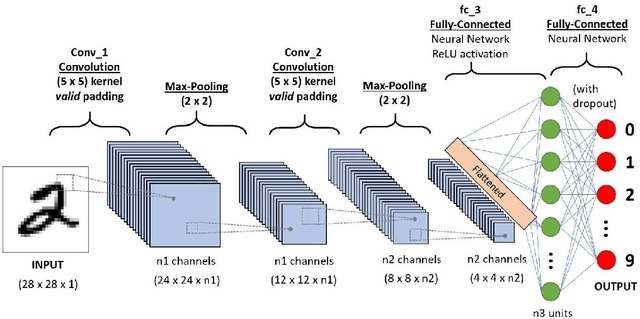
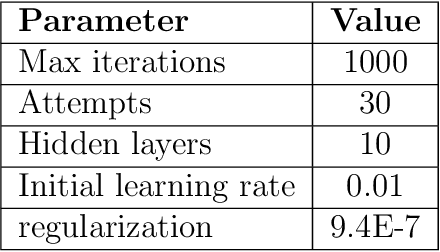
Convolutional Neural Networks (CNNs) is one of the most popular algorithms for deep learning which is mostly used for image classification, natural language processing, and time series forecasting. Its ability to extract and recognize the fine features has led to the state-of-the-art performance. CNN has been designed to work on a set of 2-D matrices whose elements show some correlation with neighboring elements such as in image data. Conversely, the data examples represented as a set of 1-D vectors -- apart from time series data -- cannot be used with CNN, but with other Artificial Neural Networks (ANNs). We have proposed some novel preprocessing methods of data wrangling that transform a 1-D data vector to a 2-D graphical image with appropriate correlations among the fields to be processed on CNN. To our knowledge this work is novel on non-image to image data transformation for non-time series data. The transformed data processed with CNN using VGGnet-16 shows a competitive result in classification accuracy compared to canonical ANN approach with high potential for further improvements.
A Constraint Driven Solution Model for Discrete Domains with a Case Study of Exam Timetabling Problems
Feb 08, 2020


Many science and engineering applications require finding solutions to planning and optimization problems by satisfying a set of constraints. These constraint problems (CPs) are typically NP-complete and can be formalized as constraint satisfaction problems (CSPs) or constraint optimization problems (COPs). Evolutionary algorithms (EAs) are good solvers for optimization problems ubiquitous in various problem domains, however traditional operators for EAs are 'blind' to constraints or generally use problem dependent objective functions; as they do not exploit information from the constraints in search for solutions. A variation of EA, Intelligent constraint handling evolutionary algorithm (ICHEA), has been demonstrated to be a versatile constraints-guided EA for continuous constrained problems in our earlier works in (Sharma and Sharma, 2012) where it extracts information from constraints and exploits it in the evolutionary search to make the search more efficient. In this paper ICHEA has been demonstrated to solve benchmark exam timetabling problems, a classic COP. The presented approach demonstrates competitive results with other state-of-the-art approaches in EAs in terms of quality of solutions. ICHEA first uses its inter-marriage crossover operator to satisfy all the given constraints incrementally and then uses combination of traditional and enhanced operators to optimize the solution. Generally CPs solved by EAs are problem dependent penalty based fitness functions. We also proposed a generic preference based solution model that does not require a problem dependent fitness function, however currently it only works for mutually exclusive constraints.
Stacked transfer learning for tropical cyclone intensity prediction
Aug 22, 2017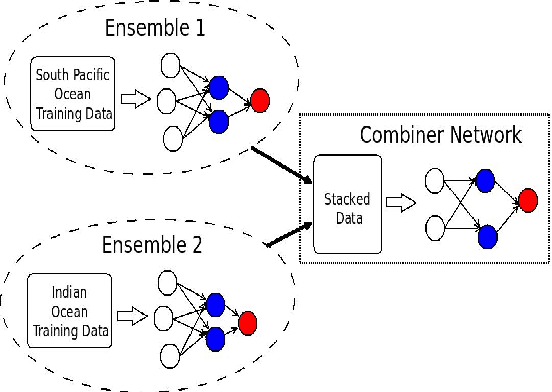

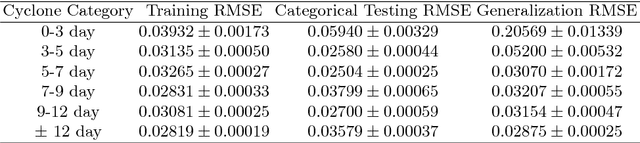

Tropical cyclone wind-intensity prediction is a challenging task considering drastic changes climate patterns over the last few decades. In order to develop robust prediction models, one needs to consider different characteristics of cyclones in terms of spatial and temporal characteristics. Transfer learning incorporates knowledge from a related source dataset to compliment a target datasets especially in cases where there is lack or data. Stacking is a form of ensemble learning focused for improving generalization that has been recently used for transfer learning problems which is referred to as transfer stacking. In this paper, we employ transfer stacking as a means of studying the effects of cyclones whereby we evaluate if cyclones in different geographic locations can be helpful for improving generalization performs. Moreover, we use conventional neural networks for evaluating the effects of duration on cyclones in prediction performance. Therefore, we develop an effective strategy that evaluates the relationships between different types of cyclones through transfer learning and conventional learning methods via neural networks.