 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Convex Obstacle Avoidance Formulation
Dec 15, 2025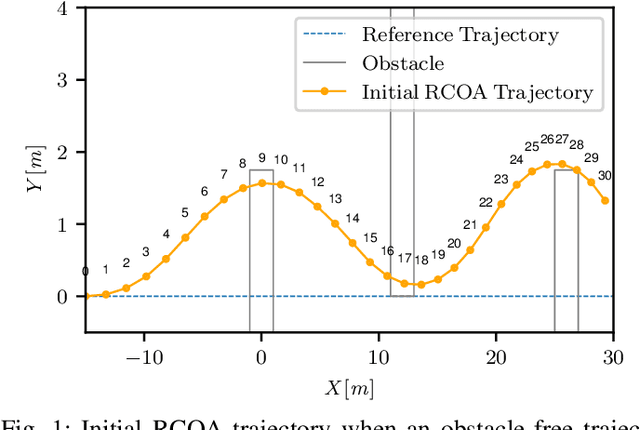

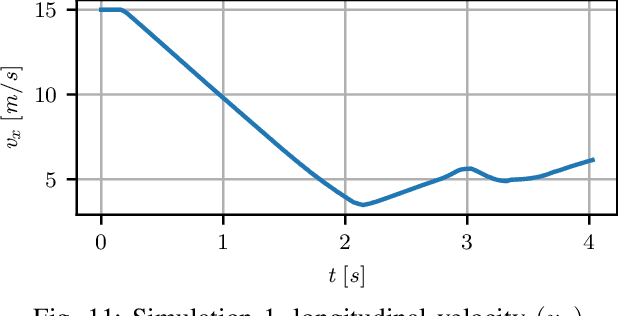

Autonomous driving requires reliable collision avoidance in dynamic environments. Nonlinear Model Predictive Controllers (NMPCs) are suitable for this task, but struggle in time-critical scenarios requiring high frequency. To meet this demand, optimization problems are often simplified via linearization, narrowing the horizon window, or reduced temporal nodes, each compromising accuracy or reliability. This work presents the first general convex obstacle avoidance formulation, enabled by a novel approach to integrating logic. This facilitates the incorporation of an obstacle avoidance formulation into convex MPC schemes, enabling a convex optimization framework with substantially improved computational efficiency relative to conventional nonconvex methods. A key property of the formulation is that obstacle avoidance remains effective even when obstacles lie outside the prediction horizon, allowing shorter horizons for real-time deployment. In scenarios where nonconvex formulations are unavoidable, the proposed method meets or exceeds the performance of representative nonconvex alternatives. The method is evaluated in autonomous vehicle applications, where system dynamics are highly nonlinear.
VITA: Vision-to-Action Flow Matching Policy
Jul 17, 2025We present VITA, a Vision-To-Action flow matching policy that evolves latent visual representations into latent actions for visuomotor control. Traditional flow matching and diffusion policies sample from standard source distributions (e.g., Gaussian noise) and require additional conditioning mechanisms like cross-attention to condition action generation on visual information, creating time and space overheads. VITA proposes a novel paradigm that treats latent images as the flow source, learning an inherent mapping from vision to action while eliminating separate conditioning modules and preserving generative modeling capabilities. Learning flows between fundamentally different modalities like vision and action is challenging due to sparse action data lacking semantic structures and dimensional mismatches between high-dimensional visual representations and raw actions. We address this by creating a structured action latent space via an autoencoder as the flow matching target, up-sampling raw actions to match visual representation shapes. Crucially, we supervise flow matching with both encoder targets and final action outputs through flow latent decoding, which backpropagates action reconstruction loss through sequential flow matching ODE solving steps for effective end-to-end learning. Implemented as simple MLP layers, VITA is evaluated on challenging bi-manual manipulation tasks on the ALOHA platform, including 5 simulation and 2 real-world tasks. Despite its simplicity, MLP-only VITA outperforms or matches state-of-the-art generative policies while reducing inference latency by 50-130% compared to conventional flow matching policies requiring different conditioning mechanisms or complex architectures. To our knowledge, VITA is the first MLP-only flow matching policy capable of solving complex bi-manual manipulation tasks like those in ALOHA benchmarks.
IN-RIL: Interleaved Reinforcement and Imitation Learning for Policy Fine-Tuning
May 15, 2025Imitation learning (IL) and reinforcement learning (RL) each offer distinct advantages for robotics policy learning: IL provides stable learning from demonstrations, and RL promotes generalization through exploration. While existing robot learning approaches using IL-based pre-training followed by RL-based fine-tuning are promising, this two-step learning paradigm often suffers from instability and poor sample efficiency during the RL fine-tuning phase. In this work, we introduce IN-RIL, INterleaved Reinforcement learning and Imitation Learning, for policy fine-tuning, which periodically injects IL updates after multiple RL updates and hence can benefit from the stability of IL and the guidance of expert data for more efficient exploration throughout the entire fine-tuning process. Since IL and RL involve different optimization objectives, we develop gradient separation mechanisms to prevent destructive interference during \ABBR fine-tuning, by separating possibly conflicting gradient updates in orthogonal subspaces. Furthermore, we conduct rigorous analysis, and our findings shed light on why interleaving IL with RL stabilizes learning and improves sample-efficiency. Extensive experiments on 14 robot manipulation and locomotion tasks across 3 benchmarks, including FurnitureBench, OpenAI Gym, and Robomimic, demonstrate that \ABBR can significantly improve sample efficiency and mitigate performance collapse during online finetuning in both long- and short-horizon tasks with either sparse or dense rewards. IN-RIL, as a general plug-in compatible with various state-of-the-art RL algorithms, can significantly improve RL fine-tuning, e.g., from 12\% to 88\% with 6.3x improvement in the success rate on Robomimic Transport. Project page: https://github.com/ucd-dare/IN-RIL.
Automating Infrastructure Surveying: A Framework for Geometric Measurements and Compliance Assessment Using Point Cloud Data
May 09, 2025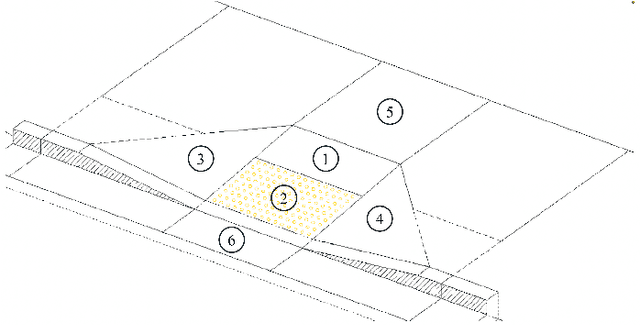
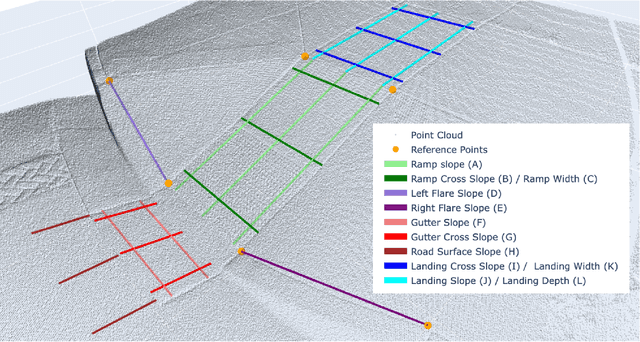
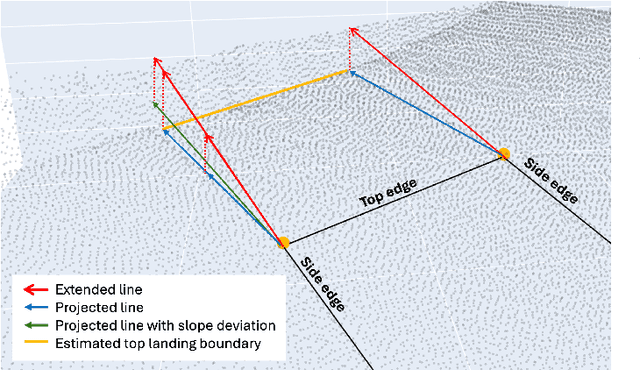
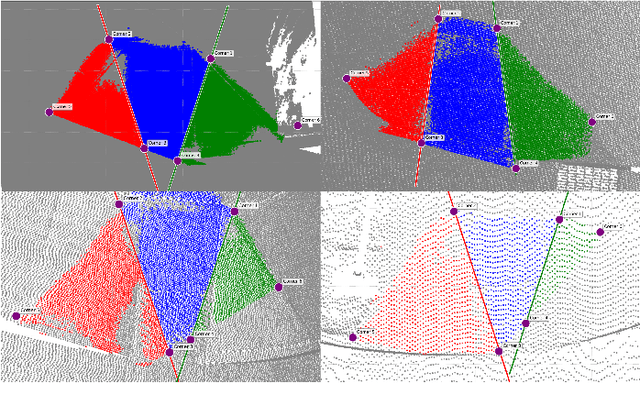
Automation can play a prominent role in improving efficiency, accuracy, and scalability in infrastructure surveying and assessing construction and compliance standards. This paper presents a framework for automation of geometric measurements and compliance assessment using point cloud data. The proposed approach integrates deep learning-based detection and segmentation, in conjunction with geometric and signal processing techniques, to automate surveying tasks. As a proof of concept, we apply this framework to automatically evaluate the compliance of curb ramps with the Americans with Disabilities Act (ADA), demonstrating the utility of point cloud data in survey automation. The method leverages a newly collected, large annotated dataset of curb ramps, made publicly available as part of this work, to facilitate robust model training and evaluation. Experimental results, including comparison with manual field measurements of several ramps, validate the accuracy and reliability of the proposed method, highlighting its potential to significantly reduce manual effort and improve consistency in infrastructure assessment. Beyond ADA compliance, the proposed framework lays the groundwork for broader applications in infrastructure surveying and automated construction evaluation, promoting wider adoption of point cloud data in these domains. The annotated database, manual ramp survey data, and developed algorithms are publicly available on the project's GitHub page: https://github.com/Soltanilara/SurveyAutomation.
Infrared Vision Systems for Emergency Vehicle Driver Assistance in Low-Visibility Conditions
Apr 18, 2025This study investigates the potential of infrared (IR) camera technology to enhance driver safety for emergency vehicles operating in low-visibility conditions, particularly at night and in dense fog. Such environments significantly increase the risk of collisions, especially for tow trucks and snowplows that must remain operational in challenging conditions. Conventional driver assistance systems often struggle under these conditions due to limited visibility. In contrast, IR cameras, which detect the thermal signatures of obstacles, offer a promising alternative. The evaluation combines controlled laboratory experiments, real-world field tests, and surveys of emergency vehicle operators. In addition to assessing detection performance, the study examines the feasibility of retrofitting existing Department of Transportation (DoT) fleets with cost-effective IR-based driver assistance systems. Results underscore the utility of IR technology in enhancing driver awareness and provide data-driven recommendations for scalable deployment across legacy emergency vehicle fleets.
Krysalis Hand: A Lightweight, High-Payload, 18-DoF Anthropomorphic End-Effector for Robotic Learning and Dexterous Manipulation
Apr 17, 2025



This paper presents the Krysalis Hand, a five-finger robotic end-effector that combines a lightweight design, high payload capacity, and a high number of degrees of freedom (DoF) to enable dexterous manipulation in both industrial and research settings. This design integrates the actuators within the hand while maintaining an anthropomorphic form. Each finger joint features a self-locking mechanism that allows the hand to sustain large external forces without active motor engagement. This approach shifts the payload limitation from the motor strength to the mechanical strength of the hand, allowing the use of smaller, more cost-effective motors. With 18 DoF and weighing only 790 grams, the Krysalis Hand delivers an active squeezing force of 10 N per finger and supports a passive payload capacity exceeding 10 lbs. These characteristics make Krysalis Hand one of the lightest, strongest, and most dexterous robotic end-effectors of its kind. Experimental evaluations validate its ability to perform intricate manipulation tasks and handle heavy payloads, underscoring its potential for industrial applications as well as academic research. All code related to the Krysalis Hand, including control and teleoperation, is available on the project GitHub repository: https://github.com/Soltanilara/Krysalis_Hand
Design and Implementation of a Dual Uncrewed Surface Vessel Platform for Bathymetry Research under High-flow Conditions
Feb 18, 2025



Bathymetry, the study of underwater topography, relies on sonar mapping of submerged structures. These measurements, critical for infrastructure health monitoring, often require expensive instrumentation. The high financial risk associated with sensor damage or vessel loss creates a reluctance to deploy uncrewed surface vessels (USVs) for bathymetry. However, the crewed-boat bathymetry operations, are costly, pose hazards to personnel, and frequently fail to achieve the stable conditions necessary for bathymetry data collection, especially under high currents. Further research is essential to advance autonomous control, navigation, and data processing technologies, with a particular focus on bathymetry. There is a notable lack of accessible hardware platforms that allow for integrated research in both bathymetry-focused autonomous control and navigation, as well as data evaluation and processing. This paper addresses this gap through the design and implementation of two complementary USV systems tailored for uncrewed bathymetry research. This includes a low-cost USV for Navigation And Control research (NAC-USV) and a second, high-end USV equipped with a high-resolution multi-beam sonar and the associated hardware for Bathymetry data quality Evaluation and Post-processing research (BEP-USV). The NAC-USV facilitates the investigation of autonomous, fail-safe navigation and control, emphasizing the stability requirements for high-quality bathymetry data collection while minimizing the risk to equipment. The BEP-USV, which mirrors the NAC-USV hardware, is then used for additional control validation and in-depth exploration of bathymetry data evaluation and post-processing methodologies. We detail the design and implementation of both systems, and open source the design. Furthermore, we demonstrate the system's effectiveness in a range of operational scenarios.
MarineFormer: A Transformer-based Navigation Policy Model for Collision Avoidance in Marine Environment
Oct 17, 2024



In this work, we investigate the problem of Unmanned Surface Vehicle (USV) navigation in a dense marine environment with a high-intensity current flow. The complexities arising from static and dynamic obstacles and the disturbance forces caused by current flow render existing navigation protocols inadequate for ensuring safety and avoiding collisions at sea. To learn a safe and efficient robot policy, we propose a novel methodology that leverages attention mechanisms to capture heterogeneous interactions of the agents with the static and moving obstacles and the flow disturbances from the environment in space and time. In particular, we refine a temporal function with MarineFormer, a Transformer navigation policy for spatially variable Marine environment, trained end-to-end with reinforcement learning (RL). MarineFormer uses foundational spatio-temporal graph attention with transformer architecture to process spatial attention and temporal sequences in an environment that simulates a 2D turbulent marine condition. We propose architectural modifications that improve the stability and learning speed of the recurrent models. The flow velocity estimation, which can be derived from flow simulations or sensors, is incorporated into a model-free RL framework to prevent the robot from entering into high-intensity current flow regions including intense vortices, while potentially leveraging the flow to assist in transportation. The investigated 2D marine environment encompasses flow singularities, including vortices, sinks, and sources, representing fundamental planar flow patterns associated with flood or maritime thunderstorms. Our proposed method is trained with a new reward model to deal with static and dynamic obstacles and disturbances from the current flow.
Active Vision Might Be All You Need: Exploring Active Vision in Bimanual Robotic Manipulation
Sep 26, 2024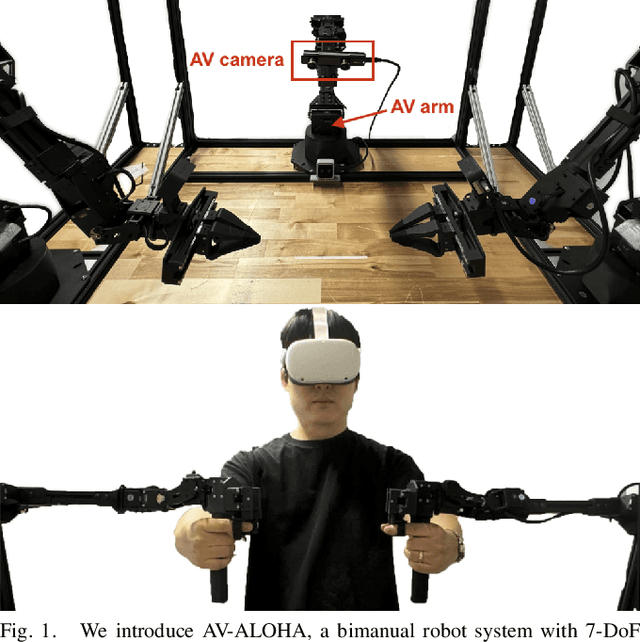


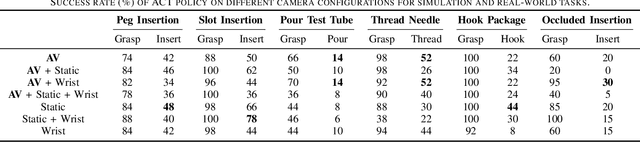
Imitation learning has demonstrated significant potential in performing high-precision manipulation tasks using visual feedback from cameras. However, it is common practice in imitation learning for cameras to be fixed in place, resulting in issues like occlusion and limited field of view. Furthermore, cameras are often placed in broad, general locations, without an effective viewpoint specific to the robot's task. In this work, we investigate the utility of active vision (AV) for imitation learning and manipulation, in which, in addition to the manipulation policy, the robot learns an AV policy from human demonstrations to dynamically change the robot's camera viewpoint to obtain better information about its environment and the given task. We introduce AV-ALOHA, a new bimanual teleoperation robot system with AV, an extension of the ALOHA 2 robot system, incorporating an additional 7-DoF robot arm that only carries a stereo camera and is solely tasked with finding the best viewpoint. This camera streams stereo video to an operator wearing a virtual reality (VR) headset, allowing the operator to control the camera pose using head and body movements. The system provides an immersive teleoperation experience, with bimanual first-person control, enabling the operator to dynamically explore and search the scene and simultaneously interact with the environment. We conduct imitation learning experiments of our system both in real-world and in simulation, across a variety of tasks that emphasize viewpoint planning. Our results demonstrate the effectiveness of human-guided AV for imitation learning, showing significant improvements over fixed cameras in tasks with limited visibility. Project website: https://soltanilara.github.io/av-aloha/
Hierarchical end-to-end autonomous navigation through few-shot waypoint detection
Sep 23, 2024



Human navigation is facilitated through the association of actions with landmarks, tapping into our ability to recognize salient features in our environment. Consequently, navigational instructions for humans can be extremely concise, such as short verbal descriptions, indicating a small memory requirement and no reliance on complex and overly accurate navigation tools. Conversely, current autonomous navigation schemes rely on accurate positioning devices and algorithms as well as extensive streams of sensory data collected from the environment. Inspired by this human capability and motivated by the associated technological gap, in this work we propose a hierarchical end-to-end meta-learning scheme that enables a mobile robot to navigate in a previously unknown environment upon presentation of only a few sample images of a set of landmarks along with their corresponding high-level navigation actions. This dramatically simplifies the wayfinding process and enables easy adoption to new environments. For few-shot waypoint detection, we implement a metric-based few-shot learning technique through distribution embedding. Waypoint detection triggers the multi-task low-level maneuver controller module to execute the corresponding high-level navigation action. We demonstrate the effectiveness of the scheme using a small-scale autonomous vehicle on novel indoor navigation tasks in several previously unseen environments.
* Appeared at the 40th Anniversary of the IEEE International Conference on Robotics and Automation (ICRA@40), 23-26 September, 2024, Rotterdam, The Netherlands. 9 pages, 5 figures