 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVITA: Vision-to-Action Flow Matching Policy
Jul 17, 2025We present VITA, a Vision-To-Action flow matching policy that evolves latent visual representations into latent actions for visuomotor control. Traditional flow matching and diffusion policies sample from standard source distributions (e.g., Gaussian noise) and require additional conditioning mechanisms like cross-attention to condition action generation on visual information, creating time and space overheads. VITA proposes a novel paradigm that treats latent images as the flow source, learning an inherent mapping from vision to action while eliminating separate conditioning modules and preserving generative modeling capabilities. Learning flows between fundamentally different modalities like vision and action is challenging due to sparse action data lacking semantic structures and dimensional mismatches between high-dimensional visual representations and raw actions. We address this by creating a structured action latent space via an autoencoder as the flow matching target, up-sampling raw actions to match visual representation shapes. Crucially, we supervise flow matching with both encoder targets and final action outputs through flow latent decoding, which backpropagates action reconstruction loss through sequential flow matching ODE solving steps for effective end-to-end learning. Implemented as simple MLP layers, VITA is evaluated on challenging bi-manual manipulation tasks on the ALOHA platform, including 5 simulation and 2 real-world tasks. Despite its simplicity, MLP-only VITA outperforms or matches state-of-the-art generative policies while reducing inference latency by 50-130% compared to conventional flow matching policies requiring different conditioning mechanisms or complex architectures. To our knowledge, VITA is the first MLP-only flow matching policy capable of solving complex bi-manual manipulation tasks like those in ALOHA benchmarks.
Ego-centric Learning of Communicative World Models for Autonomous Driving
Jun 09, 2025



We study multi-agent reinforcement learning (MARL) for tasks in complex high-dimensional environments, such as autonomous driving. MARL is known to suffer from the \textit{partial observability} and \textit{non-stationarity} issues. To tackle these challenges, information sharing is often employed, which however faces major hurdles in practice, including overwhelming communication overhead and scalability concerns. By making use of generative AI embodied in world model together with its latent representation, we develop {\it CALL}, \underline{C}ommunic\underline{a}tive Wor\underline{l}d Mode\underline{l}, for MARL, where 1) each agent first learns its world model that encodes its state and intention into low-dimensional latent representation with smaller memory footprint, which can be shared with other agents of interest via lightweight communication; and 2) each agent carries out ego-centric learning while exploiting lightweight information sharing to enrich her world model, and then exploits its generalization capacity to improve prediction for better planning. We characterize the gain on the prediction accuracy from the information sharing and its impact on performance gap. Extensive experiments are carried out on the challenging local trajectory planning tasks in the CARLA platform to demonstrate the performance gains of using \textit{CALL}.
IN-RIL: Interleaved Reinforcement and Imitation Learning for Policy Fine-Tuning
May 15, 2025Imitation learning (IL) and reinforcement learning (RL) each offer distinct advantages for robotics policy learning: IL provides stable learning from demonstrations, and RL promotes generalization through exploration. While existing robot learning approaches using IL-based pre-training followed by RL-based fine-tuning are promising, this two-step learning paradigm often suffers from instability and poor sample efficiency during the RL fine-tuning phase. In this work, we introduce IN-RIL, INterleaved Reinforcement learning and Imitation Learning, for policy fine-tuning, which periodically injects IL updates after multiple RL updates and hence can benefit from the stability of IL and the guidance of expert data for more efficient exploration throughout the entire fine-tuning process. Since IL and RL involve different optimization objectives, we develop gradient separation mechanisms to prevent destructive interference during \ABBR fine-tuning, by separating possibly conflicting gradient updates in orthogonal subspaces. Furthermore, we conduct rigorous analysis, and our findings shed light on why interleaving IL with RL stabilizes learning and improves sample-efficiency. Extensive experiments on 14 robot manipulation and locomotion tasks across 3 benchmarks, including FurnitureBench, OpenAI Gym, and Robomimic, demonstrate that \ABBR can significantly improve sample efficiency and mitigate performance collapse during online finetuning in both long- and short-horizon tasks with either sparse or dense rewards. IN-RIL, as a general plug-in compatible with various state-of-the-art RL algorithms, can significantly improve RL fine-tuning, e.g., from 12\% to 88\% with 6.3x improvement in the success rate on Robomimic Transport. Project page: https://github.com/ucd-dare/IN-RIL.
Automating Infrastructure Surveying: A Framework for Geometric Measurements and Compliance Assessment Using Point Cloud Data
May 09, 2025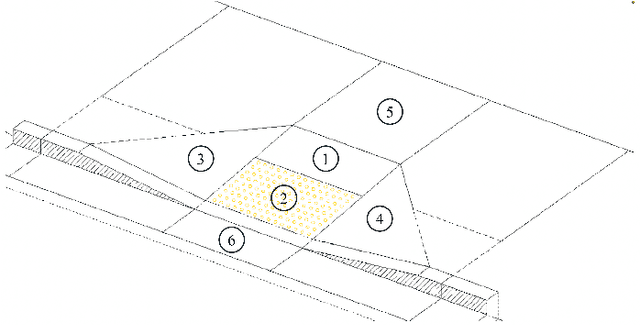
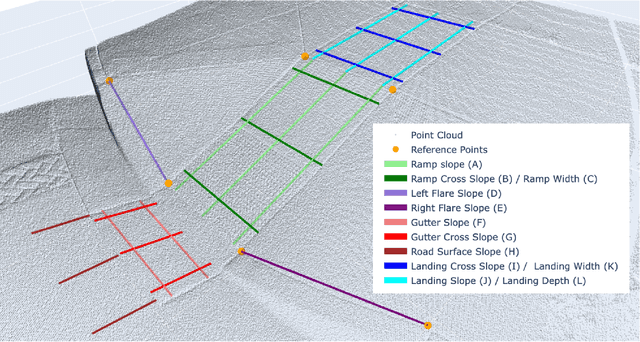
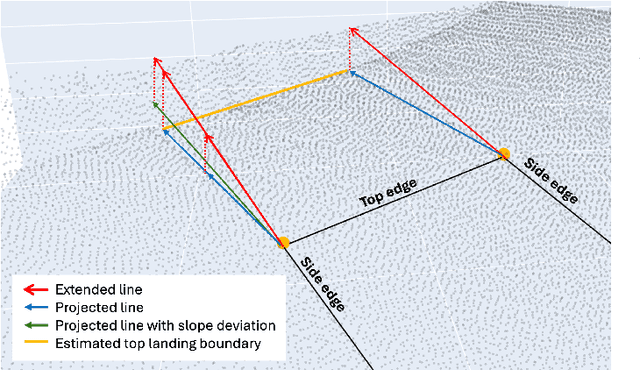
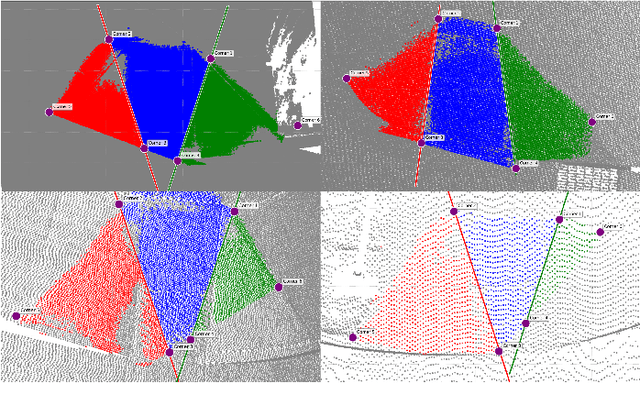
Automation can play a prominent role in improving efficiency, accuracy, and scalability in infrastructure surveying and assessing construction and compliance standards. This paper presents a framework for automation of geometric measurements and compliance assessment using point cloud data. The proposed approach integrates deep learning-based detection and segmentation, in conjunction with geometric and signal processing techniques, to automate surveying tasks. As a proof of concept, we apply this framework to automatically evaluate the compliance of curb ramps with the Americans with Disabilities Act (ADA), demonstrating the utility of point cloud data in survey automation. The method leverages a newly collected, large annotated dataset of curb ramps, made publicly available as part of this work, to facilitate robust model training and evaluation. Experimental results, including comparison with manual field measurements of several ramps, validate the accuracy and reliability of the proposed method, highlighting its potential to significantly reduce manual effort and improve consistency in infrastructure assessment. Beyond ADA compliance, the proposed framework lays the groundwork for broader applications in infrastructure surveying and automated construction evaluation, promoting wider adoption of point cloud data in these domains. The annotated database, manual ramp survey data, and developed algorithms are publicly available on the project's GitHub page: https://github.com/Soltanilara/SurveyAutomation.
EI-Drive: A Platform for Cooperative Perception with Realistic Communication Models
Dec 13, 2024



The growing interest in autonomous driving calls for realistic simulation platforms capable of accurately simulating cooperative perception process in realistic traffic scenarios. Existing studies for cooperative perception often have not accounted for transmission latency and errors in real-world environments. To address this gap, we introduce EI-Drive, an edge-AI based autonomous driving simulation platform that integrates advanced cooperative perception with more realistic communication models. Built on the CARLA framework, EI-Drive features new modules for cooperative perception while taking into account transmission latency and errors, providing a more realistic platform for evaluating cooperative perception algorithms. In particular, the platform enables vehicles to fuse data from multiple sources, improving situational awareness and safety in complex environments. With its modular design, EI-Drive allows for detailed exploration of sensing, perception, planning, and control in various cooperative driving scenarios. Experiments using EI-Drive demonstrate significant improvements in vehicle safety and performance, particularly in scenarios with complex traffic flow and network conditions. All code and documents are accessible on our GitHub page: \url{https://ucd-dare.github.io/eidrive.github.io/}.
Active Vision Might Be All You Need: Exploring Active Vision in Bimanual Robotic Manipulation
Sep 26, 2024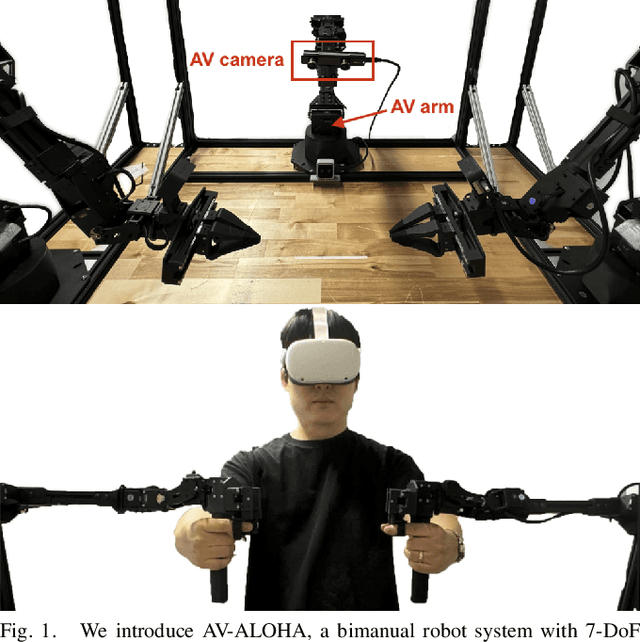


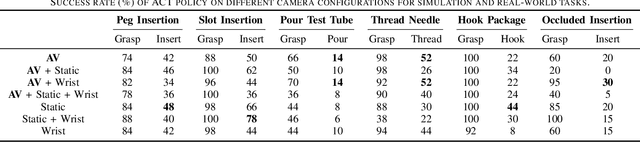
Imitation learning has demonstrated significant potential in performing high-precision manipulation tasks using visual feedback from cameras. However, it is common practice in imitation learning for cameras to be fixed in place, resulting in issues like occlusion and limited field of view. Furthermore, cameras are often placed in broad, general locations, without an effective viewpoint specific to the robot's task. In this work, we investigate the utility of active vision (AV) for imitation learning and manipulation, in which, in addition to the manipulation policy, the robot learns an AV policy from human demonstrations to dynamically change the robot's camera viewpoint to obtain better information about its environment and the given task. We introduce AV-ALOHA, a new bimanual teleoperation robot system with AV, an extension of the ALOHA 2 robot system, incorporating an additional 7-DoF robot arm that only carries a stereo camera and is solely tasked with finding the best viewpoint. This camera streams stereo video to an operator wearing a virtual reality (VR) headset, allowing the operator to control the camera pose using head and body movements. The system provides an immersive teleoperation experience, with bimanual first-person control, enabling the operator to dynamically explore and search the scene and simultaneously interact with the environment. We conduct imitation learning experiments of our system both in real-world and in simulation, across a variety of tasks that emphasize viewpoint planning. Our results demonstrate the effectiveness of human-guided AV for imitation learning, showing significant improvements over fixed cameras in tasks with limited visibility. Project website: https://soltanilara.github.io/av-aloha/
CarDreamer: Open-Source Learning Platform for World Model based Autonomous Driving
May 15, 2024To safely navigate intricate real-world scenarios, autonomous vehicles must be able to adapt to diverse road conditions and anticipate future events. World model (WM) based reinforcement learning (RL) has emerged as a promising approach by learning and predicting the complex dynamics of various environments. Nevertheless, to the best of our knowledge, there does not exist an accessible platform for training and testing such algorithms in sophisticated driving environments. To fill this void, we introduce CarDreamer, the first open-source learning platform designed specifically for developing WM based autonomous driving algorithms. It comprises three key components: 1) World model backbone: CarDreamer has integrated some state-of-the-art WMs, which simplifies the reproduction of RL algorithms. The backbone is decoupled from the rest and communicates using the standard Gym interface, so that users can easily integrate and test their own algorithms. 2) Built-in tasks: CarDreamer offers a comprehensive set of highly configurable driving tasks which are compatible with Gym interfaces and are equipped with empirically optimized reward functions. 3) Task development suite: This suite streamlines the creation of driving tasks, enabling easy definition of traffic flows and vehicle routes, along with automatic collection of multi-modal observation data. A visualization server allows users to trace real-time agent driving videos and performance metrics through a browser. Furthermore, we conduct extensive experiments using built-in tasks to evaluate the performance and potential of WMs in autonomous driving. Thanks to the richness and flexibility of CarDreamer, we also systematically study the impact of observation modality, observability, and sharing of vehicle intentions on AV safety and efficiency. All code and documents are accessible on https://github.com/ucd-dare/CarDreamer.