 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVITA: Vision-to-Action Flow Matching Policy
Jul 17, 2025We present VITA, a Vision-To-Action flow matching policy that evolves latent visual representations into latent actions for visuomotor control. Traditional flow matching and diffusion policies sample from standard source distributions (e.g., Gaussian noise) and require additional conditioning mechanisms like cross-attention to condition action generation on visual information, creating time and space overheads. VITA proposes a novel paradigm that treats latent images as the flow source, learning an inherent mapping from vision to action while eliminating separate conditioning modules and preserving generative modeling capabilities. Learning flows between fundamentally different modalities like vision and action is challenging due to sparse action data lacking semantic structures and dimensional mismatches between high-dimensional visual representations and raw actions. We address this by creating a structured action latent space via an autoencoder as the flow matching target, up-sampling raw actions to match visual representation shapes. Crucially, we supervise flow matching with both encoder targets and final action outputs through flow latent decoding, which backpropagates action reconstruction loss through sequential flow matching ODE solving steps for effective end-to-end learning. Implemented as simple MLP layers, VITA is evaluated on challenging bi-manual manipulation tasks on the ALOHA platform, including 5 simulation and 2 real-world tasks. Despite its simplicity, MLP-only VITA outperforms or matches state-of-the-art generative policies while reducing inference latency by 50-130% compared to conventional flow matching policies requiring different conditioning mechanisms or complex architectures. To our knowledge, VITA is the first MLP-only flow matching policy capable of solving complex bi-manual manipulation tasks like those in ALOHA benchmarks.
Active Vision Might Be All You Need: Exploring Active Vision in Bimanual Robotic Manipulation
Sep 26, 2024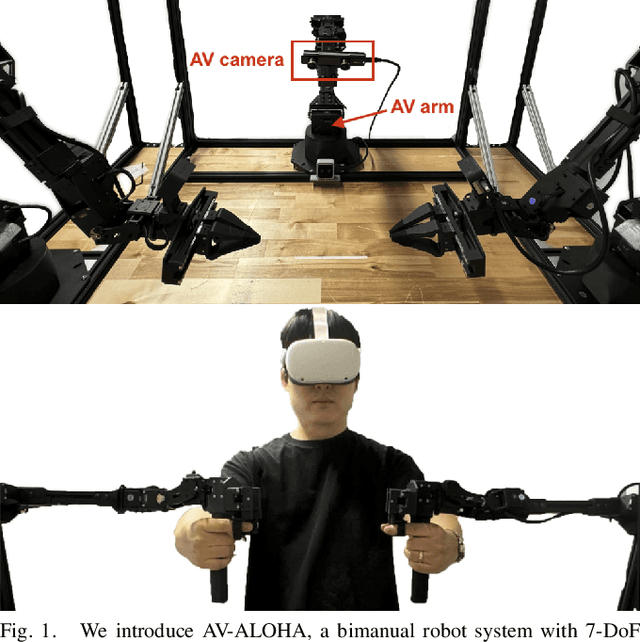


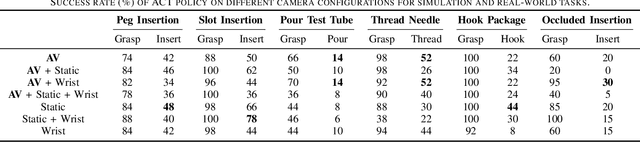
Imitation learning has demonstrated significant potential in performing high-precision manipulation tasks using visual feedback from cameras. However, it is common practice in imitation learning for cameras to be fixed in place, resulting in issues like occlusion and limited field of view. Furthermore, cameras are often placed in broad, general locations, without an effective viewpoint specific to the robot's task. In this work, we investigate the utility of active vision (AV) for imitation learning and manipulation, in which, in addition to the manipulation policy, the robot learns an AV policy from human demonstrations to dynamically change the robot's camera viewpoint to obtain better information about its environment and the given task. We introduce AV-ALOHA, a new bimanual teleoperation robot system with AV, an extension of the ALOHA 2 robot system, incorporating an additional 7-DoF robot arm that only carries a stereo camera and is solely tasked with finding the best viewpoint. This camera streams stereo video to an operator wearing a virtual reality (VR) headset, allowing the operator to control the camera pose using head and body movements. The system provides an immersive teleoperation experience, with bimanual first-person control, enabling the operator to dynamically explore and search the scene and simultaneously interact with the environment. We conduct imitation learning experiments of our system both in real-world and in simulation, across a variety of tasks that emphasize viewpoint planning. Our results demonstrate the effectiveness of human-guided AV for imitation learning, showing significant improvements over fixed cameras in tasks with limited visibility. Project website: https://soltanilara.github.io/av-aloha/
Hierarchical end-to-end autonomous navigation through few-shot waypoint detection
Sep 23, 2024



Human navigation is facilitated through the association of actions with landmarks, tapping into our ability to recognize salient features in our environment. Consequently, navigational instructions for humans can be extremely concise, such as short verbal descriptions, indicating a small memory requirement and no reliance on complex and overly accurate navigation tools. Conversely, current autonomous navigation schemes rely on accurate positioning devices and algorithms as well as extensive streams of sensory data collected from the environment. Inspired by this human capability and motivated by the associated technological gap, in this work we propose a hierarchical end-to-end meta-learning scheme that enables a mobile robot to navigate in a previously unknown environment upon presentation of only a few sample images of a set of landmarks along with their corresponding high-level navigation actions. This dramatically simplifies the wayfinding process and enables easy adoption to new environments. For few-shot waypoint detection, we implement a metric-based few-shot learning technique through distribution embedding. Waypoint detection triggers the multi-task low-level maneuver controller module to execute the corresponding high-level navigation action. We demonstrate the effectiveness of the scheme using a small-scale autonomous vehicle on novel indoor navigation tasks in several previously unseen environments.
* Appeared at the 40th Anniversary of the IEEE International Conference on Robotics and Automation (ICRA@40), 23-26 September, 2024, Rotterdam, The Netherlands. 9 pages, 5 figures
InterACT: Inter-dependency Aware Action Chunking with Hierarchical Attention Transformers for Bimanual Manipulation
Sep 12, 2024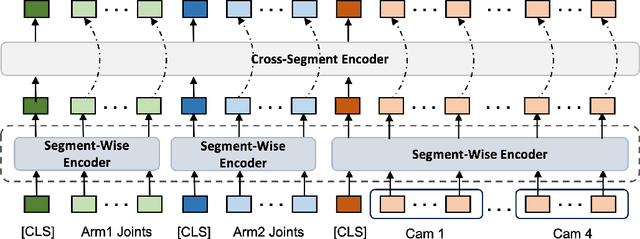

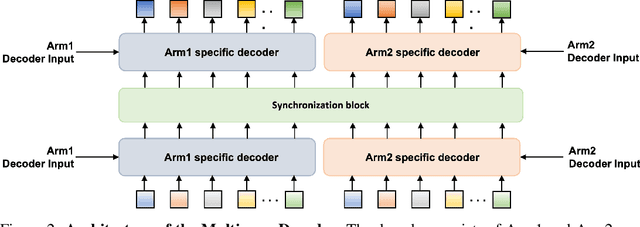

We present InterACT: Inter-dependency aware Action Chunking with Hierarchical Attention Transformers, a novel imitation learning framework for bimanual manipulation that integrates hierarchical attention to capture inter-dependencies between dual-arm joint states and visual inputs. InterACT consists of a Hierarchical Attention Encoder and a Multi-arm Decoder, both designed to enhance information aggregation and coordination. The encoder processes multi-modal inputs through segment-wise and cross-segment attention mechanisms, while the decoder leverages synchronization blocks to refine individual action predictions, providing the counterpart's prediction as context. Our experiments on a variety of simulated and real-world bimanual manipulation tasks demonstrate that InterACT significantly outperforms existing methods. Detailed ablation studies validate the contributions of key components of our work, including the impact of CLS tokens, cross-segment encoders, and synchronization blocks.