 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterACT: Inter-dependency Aware Action Chunking with Hierarchical Attention Transformers for Bimanual Manipulation
Sep 12, 2024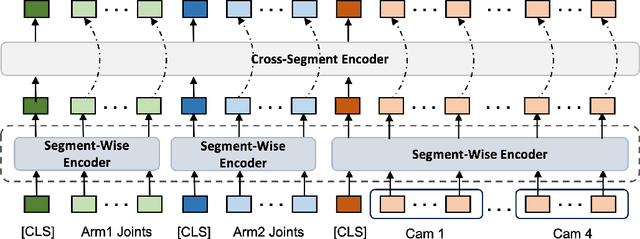

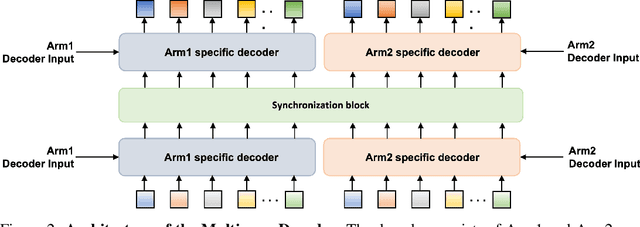

We present InterACT: Inter-dependency aware Action Chunking with Hierarchical Attention Transformers, a novel imitation learning framework for bimanual manipulation that integrates hierarchical attention to capture inter-dependencies between dual-arm joint states and visual inputs. InterACT consists of a Hierarchical Attention Encoder and a Multi-arm Decoder, both designed to enhance information aggregation and coordination. The encoder processes multi-modal inputs through segment-wise and cross-segment attention mechanisms, while the decoder leverages synchronization blocks to refine individual action predictions, providing the counterpart's prediction as context. Our experiments on a variety of simulated and real-world bimanual manipulation tasks demonstrate that InterACT significantly outperforms existing methods. Detailed ablation studies validate the contributions of key components of our work, including the impact of CLS tokens, cross-segment encoders, and synchronization blocks.