 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALON: Self-supervised Adaptive Learning for Off-road Navigation
Dec 10, 2024



Autonomous robot navigation in off-road environments presents a number of challenges due to its lack of structure, making it difficult to handcraft robust heuristics for diverse scenarios. While learned methods using hand labels or self-supervised data improve generalizability, they often require a tremendous amount of data and can be vulnerable to domain shifts. To improve generalization in novel environments, recent works have incorporated adaptation and self-supervision to develop autonomous systems that can learn from their own experiences online. However, current works often rely on significant prior data, for example minutes of human teleoperation data for each terrain type, which is difficult to scale with more environments and robots. To address these limitations, we propose SALON, a perception-action framework for fast adaptation of traversability estimates with minimal human input. SALON rapidly learns online from experience while avoiding out of distribution terrains to produce adaptive and risk-aware cost and speed maps. Within seconds of collected experience, our results demonstrate comparable navigation performance over kilometer-scale courses in diverse off-road terrain as methods trained on 100-1000x more data. We additionally show promising results on significantly different robots in different environments. Our code is available at https://theairlab.org/SALON.
FAMOUS: High-Fidelity Monocular 3D Human Digitization Using View Synthesis
Oct 13, 2024The advancement in deep implicit modeling and articulated models has significantly enhanced the process of digitizing human figures in 3D from just a single image. While state-of-the-art methods have greatly improved geometric precision, the challenge of accurately inferring texture remains, particularly in obscured areas such as the back of a person in frontal-view images. This limitation in texture prediction largely stems from the scarcity of large-scale and diverse 3D datasets, whereas their 2D counterparts are abundant and easily accessible. To address this issue, our paper proposes leveraging extensive 2D fashion datasets to enhance both texture and shape prediction in 3D human digitization. We incorporate 2D priors from the fashion dataset to learn the occluded back view, refined with our proposed domain alignment strategy. We then fuse this information with the input image to obtain a fully textured mesh of the given person. Through extensive experimentation on standard 3D human benchmarks, we demonstrate the superior performance of our approach in terms of both texture and geometry. Code and dataset is available at https://github.com/humansensinglab/FAMOUS.
Deep Bayesian Future Fusion for Self-Supervised, High-Resolution, Off-Road Mapping
Mar 18, 2024



The limited sensing resolution of resource-constrained off-road vehicles poses significant challenges towards reliable off-road autonomy. To overcome this limitation, we propose a general framework based on fusing the future information (i.e. future fusion) for self-supervision. Recent approaches exploit this future information alongside the hand-crafted heuristics to directly supervise the targeted downstream tasks (e.g. traversability estimation). However, in this paper, we opt for a more general line of development - time-efficient completion of the highest resolution (i.e. 2cm per pixel) BEV map in a self-supervised manner via future fusion, which can be used for any downstream tasks for better longer range prediction. To this end, first, we create a high-resolution future-fusion dataset containing pairs of (RGB / height) raw sparse and noisy inputs and map-based dense labels. Next, to accommodate the noise and sparsity of the sensory information, especially in the distal regions, we design an efficient realization of the Bayes filter onto the vanilla convolutional network via the recurrent mechanism. Equipped with the ideas from SOTA generative models, our Bayesian structure effectively predicts high-quality BEV maps in the distal regions. Extensive evaluation on both the quality of completion and downstream task on our future-fusion dataset demonstrates the potential of our approach.
PIAug -- Physics Informed Augmentation for Learning Vehicle Dynamics for Off-Road Navigation
Nov 01, 2023



Modeling the precise dynamics of off-road vehicles is a complex yet essential task due to the challenging terrain they encounter and the need for optimal performance and safety. Recently, there has been a focus on integrating nominal physics-based models alongside data-driven neural networks using Physics Informed Neural Networks. These approaches often assume the availability of a well-distributed dataset; however, this assumption may not hold due to regions in the physical distribution that are hard to collect, such as high-speed motions and rare terrains. Therefore, we introduce a physics-informed data augmentation methodology called PIAug. We show an example use case of the same by modeling high-speed and aggressive motion predictions, given a dataset with only low-speed data. During the training phase, we leverage the nominal model for generating target domain (medium and high velocity) data using the available source data (low velocity). Subsequently, we employ a physics-inspired loss function with this augmented dataset to incorporate prior knowledge of physics into the neural network. Our methodology results in up to 67% less mean error in trajectory prediction in comparison to a standalone nominal model, especially during aggressive maneuvers at speeds outside the training domain. In real-life navigation experiments, our model succeeds in 4x tighter waypoint tracking constraints than the Kinematic Bicycle Model (KBM) at out-of-domain velocities.
Using Large Text-to-Image Models with Structured Prompts for Skin Disease Identification: A Case Study
Jan 17, 2023



This paper investigates the potential usage of large text-to-image (LTI) models for the automated diagnosis of a few skin conditions with rarity or a serious lack of annotated datasets. As the input to the LTI model, we provide the targeted instantiation of a generic but succinct prompt structure designed upon careful observations of the conditional narratives from the standard medical textbooks. In this regard, we pave the path to utilizing accessible textbook descriptions for automated diagnosis of conditions with data scarcity through the lens of LTI models. Experiments show the efficacy of the proposed framework, including much better localization of the infected regions. Moreover, it has the immense possibility for generalization across the medical sub-domains, not only to mitigate the data scarcity issue but also to debias automated diagnostics from the all-pervasive racial biases.
HYLDA: End-to-end Hybrid Learning Domain Adaptation for LiDAR Semantic Segmentation
Jan 14, 2022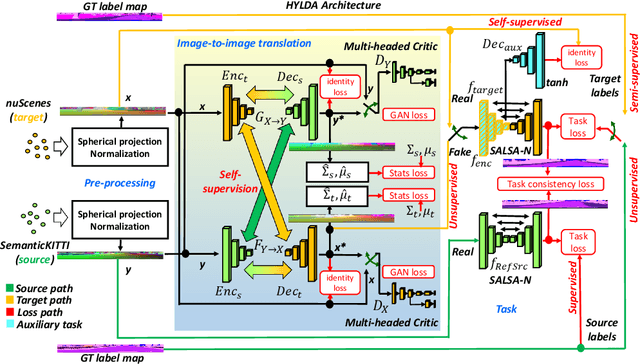
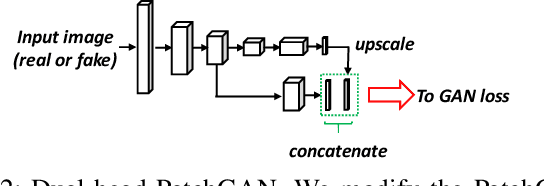

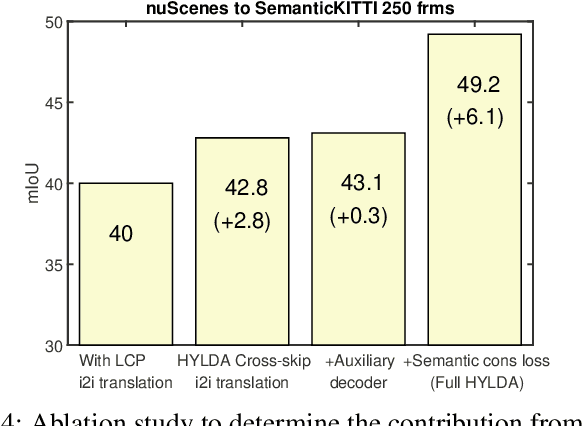
In this paper we address the problem of training a LiDAR semantic segmentation network using a fully-labeled source dataset and a target dataset that only has a small number of labels. To this end, we develop a novel image-to-image translation engine, and couple it with a LiDAR semantic segmentation network, resulting in an integrated domain adaptation architecture we call HYLDA. To train the system end-to-end, we adopt a diverse set of learning paradigms, including 1) self-supervision on a simple auxiliary reconstruction task, 2) semi-supervised training using a few available labeled target domain frames, and 3) unsupervised training on the fake translated images generated by the image-to-image translation stage, together with the labeled frames from the source domain. In the latter case, the semantic segmentation network participates in the updating of the image-to-image translation engine. We demonstrate experimentally that HYLDA effectively addresses the challenging problem of improving generalization on validation data from the target domain when only a few target labeled frames are available for training. We perform an extensive evaluation where we compare HYLDA against strong baseline methods using two publicly available LiDAR semantic segmentation datasets.
Unsupervised Domain Adaptation in LiDAR Semantic Segmentation with Self-Supervision and Gated Adapters
Jul 20, 2021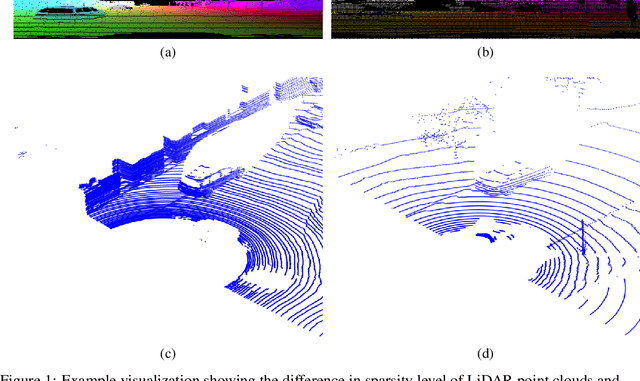
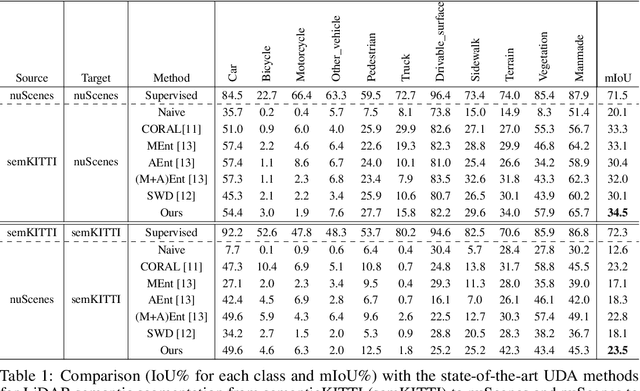
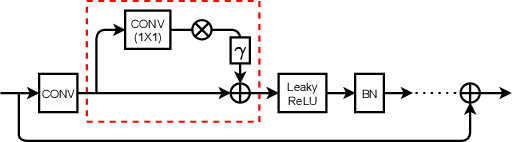
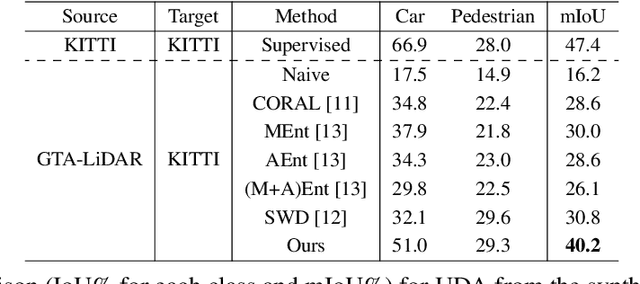
In this paper, we focus on a less explored, but more realistic and complex problem of domain adaptation in LiDAR semantic segmentation. There is a significant drop in performance of an existing segmentation model when training (source domain) and testing (target domain) data originate from different LiDAR sensors. To overcome this shortcoming, we propose an unsupervised domain adaptation framework that leverages unlabeled target domain data for self-supervision, coupled with an unpaired mask transfer strategy to mitigate the impact of domain shifts. Furthermore, we introduce gated adapter modules with a small number of parameters into the network to account for target domain-specific information. Experiments adapting from both real-to-real and synthetic-to-real LiDAR semantic segmentation benchmarks demonstrate the significant improvement over prior arts.
Bidirectional Attention Network for Monocular Depth Estimation
Sep 01, 2020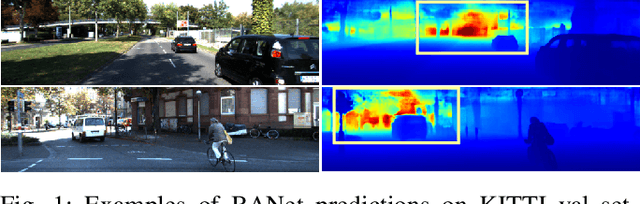
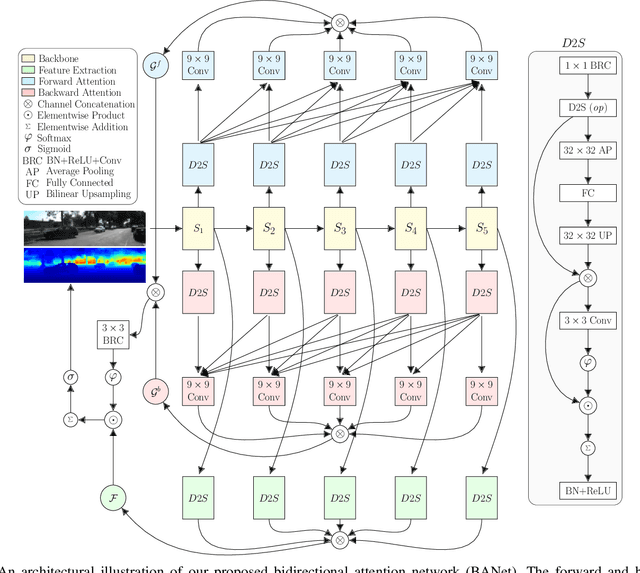

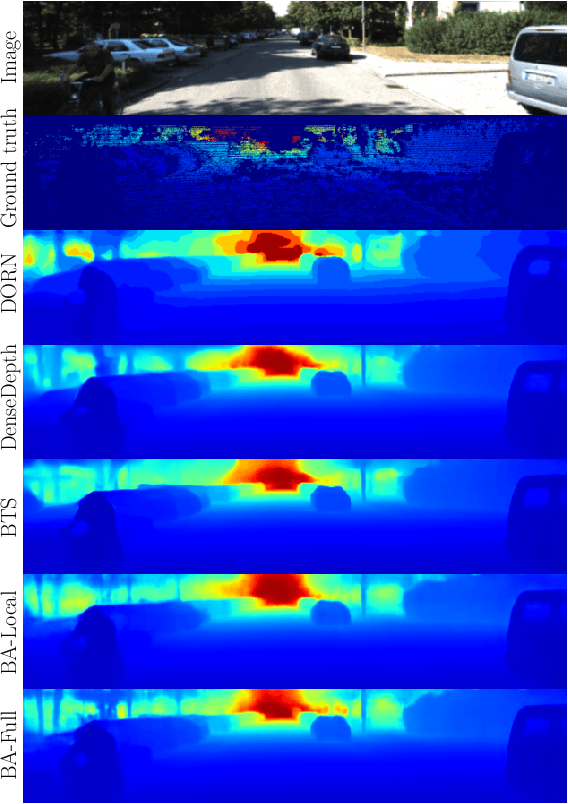
In this paper, we propose a Bidirectional Attention Network (BANet), an end-to-end framework for monocular depth estimation that addresses the limitation of effectively integrating local and global information in convolutional neural networks. The structure of this mechanism derives from a strong conceptual foundation of neural machine translation, and presents a light-weight mechanism for adaptive control of computation similar to the dynamic nature of recurrent neural networks. We introduce bidirectional attention modules that utilize the feed-forward feature maps and incorporate the global context to filter out ambiguity. Extensive experiments reveal the high degree of capability that this bidirectional attention model presents over feed-forward baselines and other state-of-the-art methods for monocular depth estimation on two challenging datasets, KITTI and DIODE. We show that our proposed approach either outperforms or performs at least on a par with the state-of-the-art monocular depth estimation methods with less memory and computational complexity.
Multi-Scale Weight Sharing Network for Image Recognition
Jan 09, 2020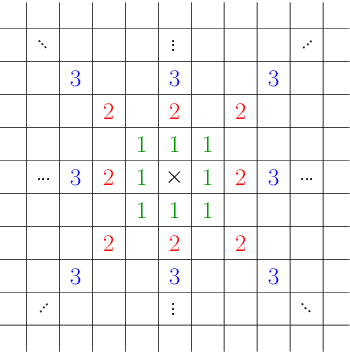



In this paper, we explore the idea of weight sharing over multiple scales in convolutional networks. Inspired by traditional computer vision approaches, we share the weights of convolution kernels over different scales in the same layers of the network. Although multi-scale feature aggregation and sharing inside convolutional networks are common in practice, none of the previous works address the issue of convolutional weight sharing. We evaluate our weight sharing scheme on two heterogeneous image recognition datasets - ImageNet (object recognition) and Places365-Standard (scene classification). With approximately 25% fewer parameters, our shared-weight ResNet model provides similar performance compared to baseline ResNets. Shared-weight models are further validated via transfer learning experiments on four additional image recognition datasets - Caltech256 and Stanford 40 Actions (object-centric) and SUN397 and MIT Inddor67 (scene-centric). Experimental results demonstrate significant redundancy in the vanilla implementations of the deeper networks, and also indicate that a shift towards increasing the receptive field per parameter may improve future convolutional network architectures.
RefinedMPL: Refined Monocular PseudoLiDAR for 3D Object Detection in Autonomous Driving
Nov 21, 2019
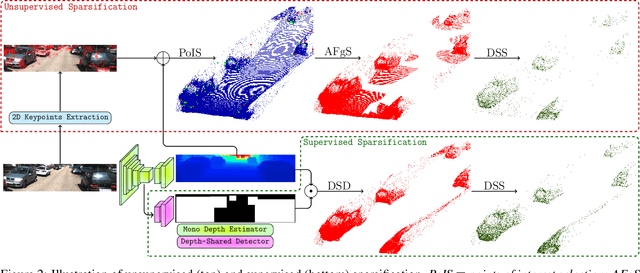
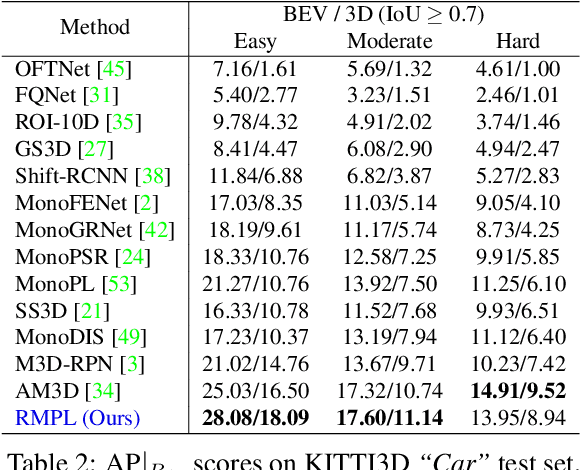
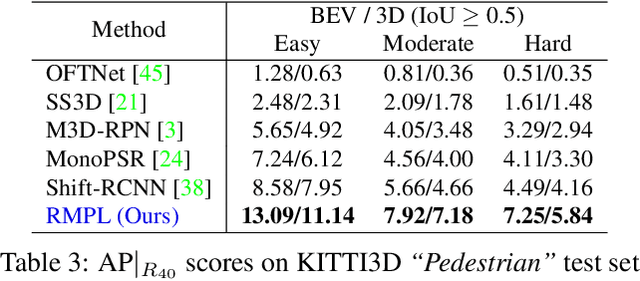
In this paper, we strive for solving the ambiguities arisen by the astoundingly high density of raw PseudoLiDAR for monocular 3D object detection for autonomous driving. Without much computational overhead, we propose a supervised and an unsupervised sparsification scheme of PseudoLiDAR prior to 3D detection. Both the strategies assist the standard 3D detector gain better performance over the raw PseudoLiDAR baseline using only ~5% of its points on the KITTI object detection benchmark, thus making our monocular framework and LiDAR-based counterparts computationally equivalent (Figure 1). Moreover, our architecture agnostic refinements provide state-of-the-art results on KITTI3D test set for "Car" and "Pedestrian" categories with 54% relative improvement for "Pedestrian". Finally, exploratory analysis is performed on the discrepancy between monocular and LiDAR-based 3D detection frameworks to guide future endeavours.