 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Large Text-to-Image Models with Structured Prompts for Skin Disease Identification: A Case Study
Jan 17, 2023



This paper investigates the potential usage of large text-to-image (LTI) models for the automated diagnosis of a few skin conditions with rarity or a serious lack of annotated datasets. As the input to the LTI model, we provide the targeted instantiation of a generic but succinct prompt structure designed upon careful observations of the conditional narratives from the standard medical textbooks. In this regard, we pave the path to utilizing accessible textbook descriptions for automated diagnosis of conditions with data scarcity through the lens of LTI models. Experiments show the efficacy of the proposed framework, including much better localization of the infected regions. Moreover, it has the immense possibility for generalization across the medical sub-domains, not only to mitigate the data scarcity issue but also to debias automated diagnostics from the all-pervasive racial biases.
Bidirectional Attention Network for Monocular Depth Estimation
Sep 01, 2020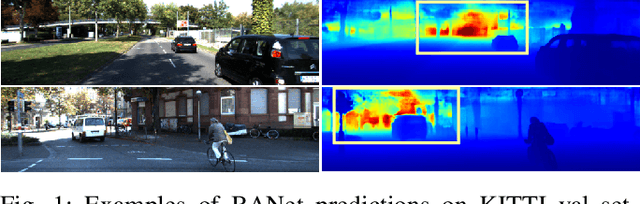
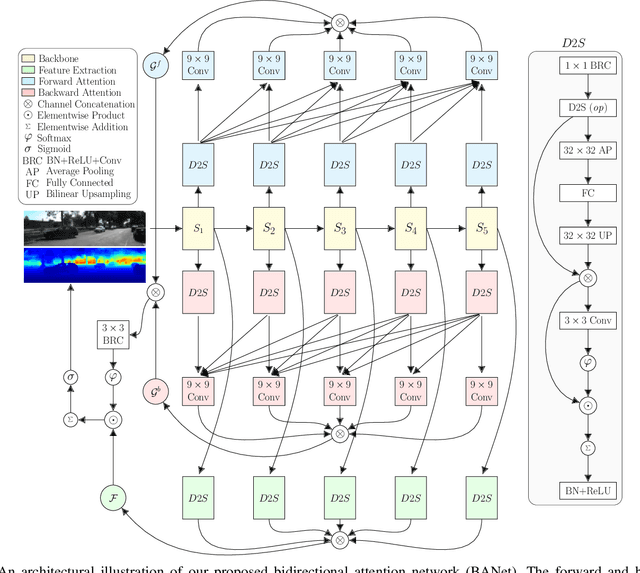

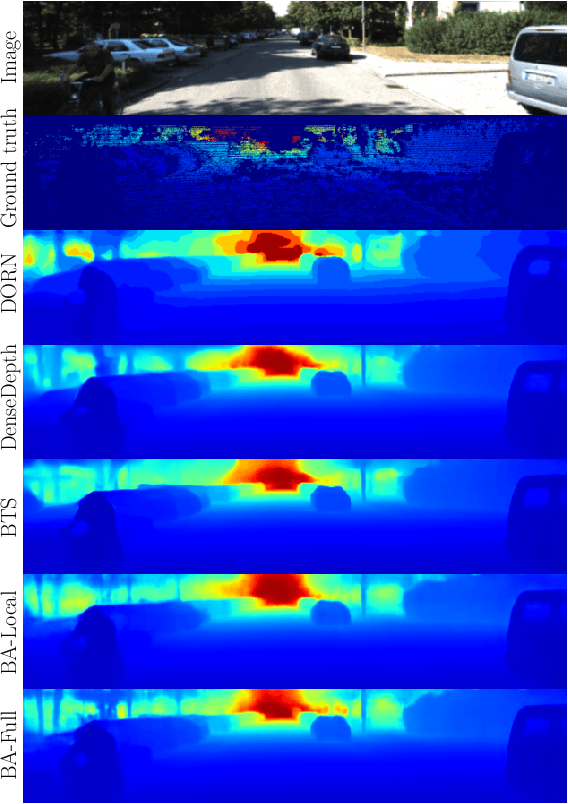
In this paper, we propose a Bidirectional Attention Network (BANet), an end-to-end framework for monocular depth estimation that addresses the limitation of effectively integrating local and global information in convolutional neural networks. The structure of this mechanism derives from a strong conceptual foundation of neural machine translation, and presents a light-weight mechanism for adaptive control of computation similar to the dynamic nature of recurrent neural networks. We introduce bidirectional attention modules that utilize the feed-forward feature maps and incorporate the global context to filter out ambiguity. Extensive experiments reveal the high degree of capability that this bidirectional attention model presents over feed-forward baselines and other state-of-the-art methods for monocular depth estimation on two challenging datasets, KITTI and DIODE. We show that our proposed approach either outperforms or performs at least on a par with the state-of-the-art monocular depth estimation methods with less memory and computational complexity.
RefinedMPL: Refined Monocular PseudoLiDAR for 3D Object Detection in Autonomous Driving
Nov 21, 2019
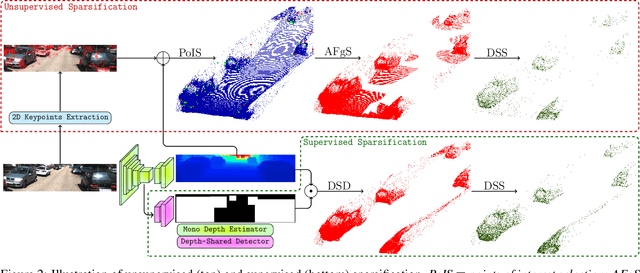
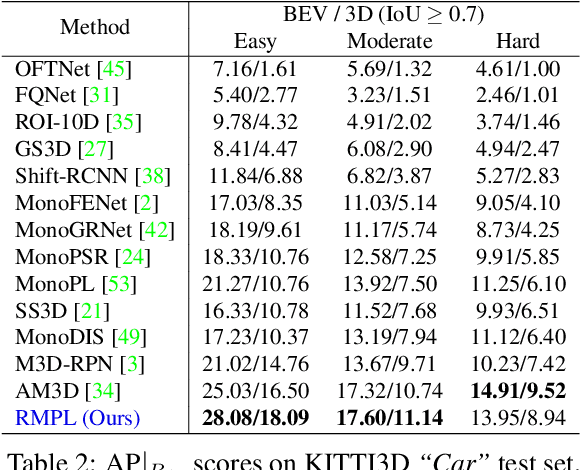
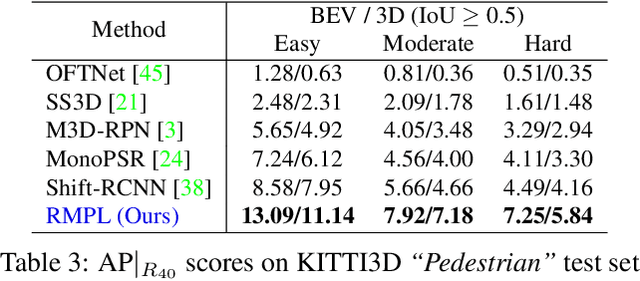
In this paper, we strive for solving the ambiguities arisen by the astoundingly high density of raw PseudoLiDAR for monocular 3D object detection for autonomous driving. Without much computational overhead, we propose a supervised and an unsupervised sparsification scheme of PseudoLiDAR prior to 3D detection. Both the strategies assist the standard 3D detector gain better performance over the raw PseudoLiDAR baseline using only ~5% of its points on the KITTI object detection benchmark, thus making our monocular framework and LiDAR-based counterparts computationally equivalent (Figure 1). Moreover, our architecture agnostic refinements provide state-of-the-art results on KITTI3D test set for "Car" and "Pedestrian" categories with 54% relative improvement for "Pedestrian". Finally, exploratory analysis is performed on the discrepancy between monocular and LiDAR-based 3D detection frameworks to guide future endeavours.