 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOMO-3D: Using Vision Foundation Models for Long-Tailed 3D Object Detection
Mar 09, 2026In order to navigate complex traffic environments, self-driving vehicles must recognize many semantic classes pertaining to vulnerable road users or traffic control devices. However, many safety-critical objects (e.g., construction worker) appear infrequently in nominal traffic conditions, leading to a severe shortage of training examples from driving data alone. Recent vision foundation models, which are trained on a large corpus of data, can serve as a good source of external prior knowledge to improve generalization. We propose FOMO-3D, the first multi-modal 3D detector to leverage vision foundation models for long-tailed 3D detection. Specifically, FOMO-3D exploits rich semantic and depth priors from OWLv2 and Metric3Dv2 within a two-stage detection paradigm that first generates proposals with a LiDAR-based branch and a novel camera-based branch, and refines them with attention especially to image features from OWL. Evaluations on real-world driving data show that using rich priors from vision foundation models with careful multi-modal fusion designs leads to large gains for long-tailed 3D detection. Project website is at https://waabi.ai/fomo3d/.
4D-Former: Multimodal 4D Panoptic Segmentation
Nov 17, 2023



4D panoptic segmentation is a challenging but practically useful task that requires every point in a LiDAR point-cloud sequence to be assigned a semantic class label, and individual objects to be segmented and tracked over time. Existing approaches utilize only LiDAR inputs which convey limited information in regions with point sparsity. This problem can, however, be mitigated by utilizing RGB camera images which offer appearance-based information that can reinforce the geometry-based LiDAR features. Motivated by this, we propose 4D-Former: a novel method for 4D panoptic segmentation which leverages both LiDAR and image modalities, and predicts semantic masks as well as temporally consistent object masks for the input point-cloud sequence. We encode semantic classes and objects using a set of concise queries which absorb feature information from both data modalities. Additionally, we propose a learned mechanism to associate object tracks over time which reasons over both appearance and spatial location. We apply 4D-Former to the nuScenes and SemanticKITTI datasets where it achieves state-of-the-art results.
MemorySeg: Online LiDAR Semantic Segmentation with a Latent Memory
Nov 02, 2023



Semantic segmentation of LiDAR point clouds has been widely studied in recent years, with most existing methods focusing on tackling this task using a single scan of the environment. However, leveraging the temporal stream of observations can provide very rich contextual information on regions of the scene with poor visibility (e.g., occlusions) or sparse observations (e.g., at long range), and can help reduce redundant computation frame after frame. In this paper, we tackle the challenge of exploiting the information from the past frames to improve the predictions of the current frame in an online fashion. To address this challenge, we propose a novel framework for semantic segmentation of a temporal sequence of LiDAR point clouds that utilizes a memory network to store, update and retrieve past information. Our framework also includes a regularizer that penalizes prediction variations in the neighborhood of the point cloud. Prior works have attempted to incorporate memory in range view representations for semantic segmentation, but these methods fail to handle occlusions and the range view representation of the scene changes drastically as agents nearby move. Our proposed framework overcomes these limitations by building a sparse 3D latent representation of the surroundings. We evaluate our method on SemanticKITTI, nuScenes, and PandaSet. Our experiments demonstrate the effectiveness of the proposed framework compared to the state-of-the-art.
MoSS: Monocular Shape Sensing for Continuum Robots
Mar 02, 2023



Continuum robots are promising candidates for interactive tasks in various applications due to their unique shape, compliance, and miniaturization capability. Accurate and real-time shape sensing is essential for such tasks yet remains a challenge. Embedded shape sensing has high hardware complexity and cost, while vision-based methods require stereo setup and struggle to achieve real-time performance. This paper proposes the first eye-to-hand monocular approach to continuum robot shape sensing. Utilizing a deep encoder-decoder network, our method, MoSSNet, eliminates the computation cost of stereo matching and reduces requirements on sensing hardware. In particular, MoSSNet comprises an encoder and three parallel decoders to uncover spatial, length, and contour information from a single RGB image, and then obtains the 3D shape through curve fitting. A two-segment tendon-driven continuum robot is used for data collection and testing, demonstrating accurate (mean shape error of 0.91 mm, or 0.36% of robot length) and real-time (70 fps) shape sensing on real-world data. Additionally, the method is optimized end-to-end and does not require fiducial markers, manual segmentation, or camera calibration. Code and datasets will be made available at https://github.com/ContinuumRoboticsLab/MoSSNet.
CPSeg: Cluster-free Panoptic Segmentation of 3D LiDAR Point Clouds
Nov 02, 2021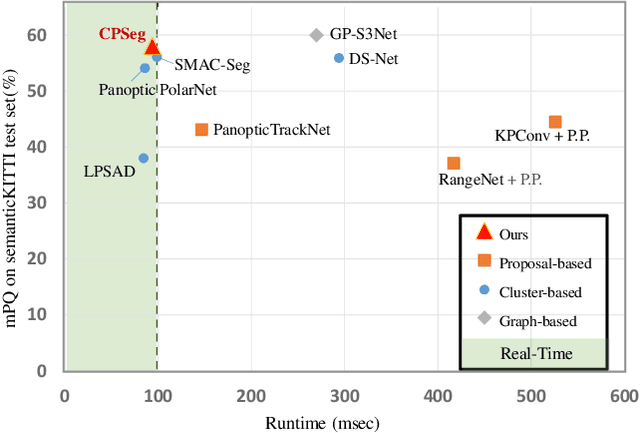
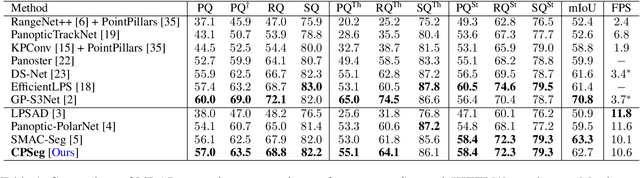
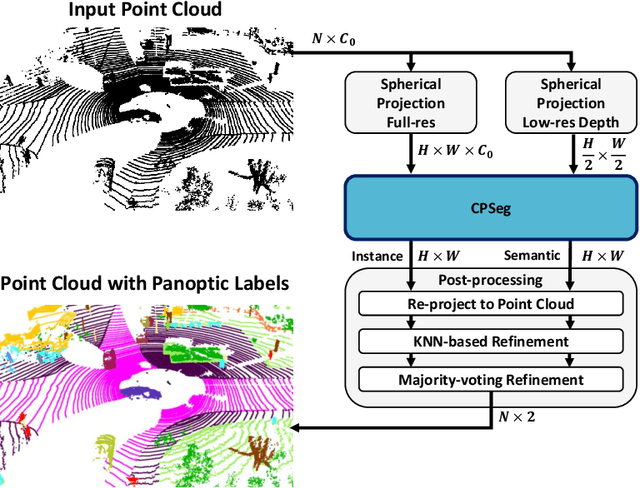
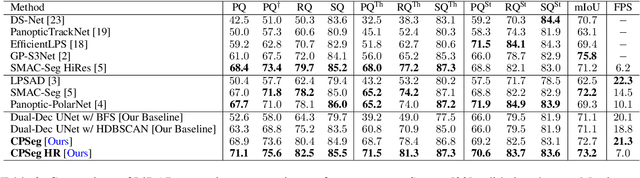
A fast and accurate panoptic segmentation system for LiDAR point clouds is crucial for autonomous driving vehicles to understand the surrounding objects and scenes. Existing approaches usually rely on proposals or clustering to segment foreground instances. As a result, they struggle to achieve real-time performance. In this paper, we propose a novel real-time end-to-end panoptic segmentation network for LiDAR point clouds, called CPSeg. In particular, CPSeg comprises a shared encoder, a dual decoder, a task-aware attention module (TAM) and a cluster-free instance segmentation head. TAM is designed to enforce these two decoders to learn rich task-aware features for semantic and instance embedding. Moreover, CPSeg incorporates a new cluster-free instance segmentation head to dynamically pillarize foreground points according to the learned embedding. Then, it acquires instance labels by finding connected pillars with a pairwise embedding comparison. Thus, the conventional proposal-based or clustering-based instance segmentation is transformed into a binary segmentation problem on the pairwise embedding comparison matrix. To help the network regress instance embedding, a fast and deterministic depth completion algorithm is proposed to calculate surface normal of each point cloud in real-time. The proposed method is benchmarked on two large-scale autonomous driving datasets, namely, SemanticKITTI and nuScenes. Notably, extensive experimental results show that CPSeg achieves the state-of-the-art results among real-time approaches on both datasets.
SMAC-Seg: LiDAR Panoptic Segmentation via Sparse Multi-directional Attention Clustering
Aug 31, 2021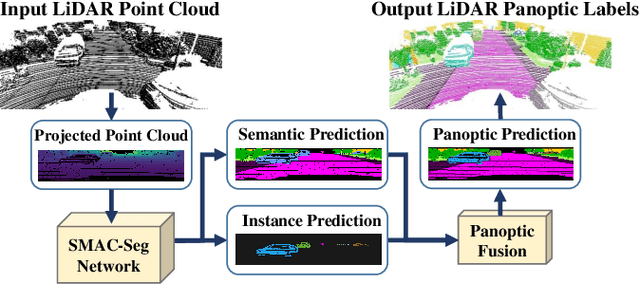
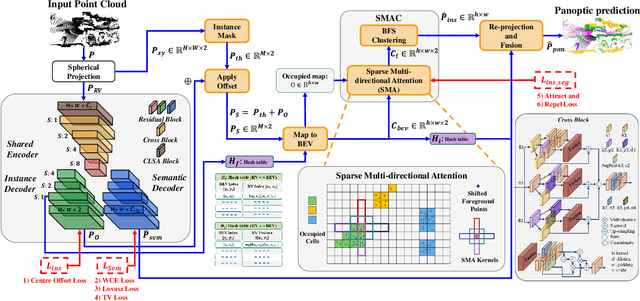
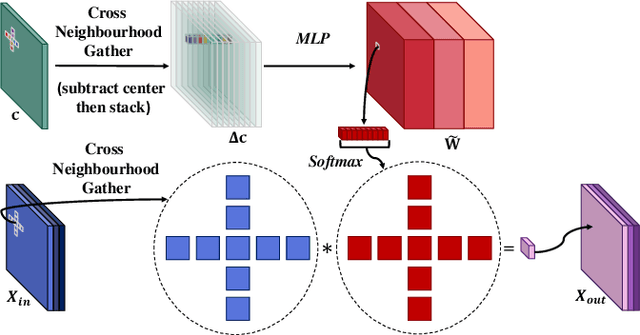
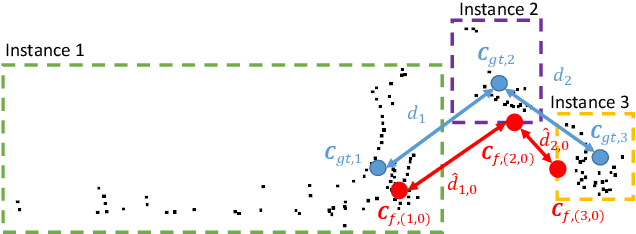
Panoptic segmentation aims to address semantic and instance segmentation simultaneously in a unified framework. However, an efficient solution of panoptic segmentation in applications like autonomous driving is still an open research problem. In this work, we propose a novel LiDAR-based panoptic system, called SMAC-Seg. We present a learnable sparse multi-directional attention clustering to segment multi-scale foreground instances. SMAC-Seg is a real-time clustering-based approach, which removes the complex proposal network to segment instances. Most existing clustering-based methods use the difference of the predicted and ground truth center offset as the only loss to supervise the instance centroid regression. However, this loss function only considers the centroid of the current object, but its relative position with respect to the neighbouring objects is not considered when learning to cluster. Thus, we propose to use a novel centroid-aware repel loss as an additional term to effectively supervise the network to differentiate each object cluster with its neighbours. Our experimental results show that SMAC-Seg achieves state-of-the-art performance among all real-time deployable networks on both large-scale public SemanticKITTI and nuScenes panoptic segmentation datasets.
GP-S3Net: Graph-based Panoptic Sparse Semantic Segmentation Network
Aug 18, 2021



Panoptic segmentation as an integrated task of both static environmental understanding and dynamic object identification, has recently begun to receive broad research interest. In this paper, we propose a new computationally efficient LiDAR based panoptic segmentation framework, called GP-S3Net. GP-S3Net is a proposal-free approach in which no object proposals are needed to identify the objects in contrast to conventional two-stage panoptic systems, where a detection network is incorporated for capturing instance information. Our new design consists of a novel instance-level network to process the semantic results by constructing a graph convolutional network to identify objects (foreground), which later on are fused with the background classes. Through the fine-grained clusters of the foreground objects from the semantic segmentation backbone, over-segmentation priors are generated and subsequently processed by 3D sparse convolution to embed each cluster. Each cluster is treated as a node in the graph and its corresponding embedding is used as its node feature. Then a GCNN predicts whether edges exist between each cluster pair. We utilize the instance label to generate ground truth edge labels for each constructed graph in order to supervise the learning. Extensive experiments demonstrate that GP-S3Net outperforms the current state-of-the-art approaches, by a significant margin across available datasets such as, nuScenes and SemanticPOSS, ranking first on the competitive public SemanticKITTI leaderboard upon publication.
(AF)2-S3Net: Attentive Feature Fusion with Adaptive Feature Selection for Sparse Semantic Segmentation Network
Feb 08, 2021



Autonomous robotic systems and self driving cars rely on accurate perception of their surroundings as the safety of the passengers and pedestrians is the top priority. Semantic segmentation is one the essential components of environmental perception that provides semantic information of the scene. Recently, several methods have been introduced for 3D LiDAR semantic segmentation. While, they can lead to improved performance, they are either afflicted by high computational complexity, therefore are inefficient, or lack fine details of smaller instances. To alleviate this problem, we propose AF2-S3Net, an end-to-end encoder-decoder CNN network for 3D LiDAR semantic segmentation. We present a novel multi-branch attentive feature fusion module in the encoder and a unique adaptive feature selection module with feature map re-weighting in the decoder. Our AF2-S3Net fuses the voxel based learning and point-based learning into a single framework to effectively process the large 3D scene. Our experimental results show that the proposed method outperforms the state-of-the-art approaches on the large-scale SemanticKITTI benchmark, ranking 1st on the competitive public leaderboard competition upon publication.