 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioX-Bridge: Model Bridging for Unsupervised Cross-Modal Knowledge Transfer across Biosignals
Oct 02, 2025Biosignals offer valuable insights into the physiological states of the human body. Although biosignal modalities differ in functionality, signal fidelity, sensor comfort, and cost, they are often intercorrelated, reflecting the holistic and interconnected nature of human physiology. This opens up the possibility of performing the same tasks using alternative biosignal modalities, thereby improving the accessibility, usability, and adaptability of health monitoring systems. However, the limited availability of large labeled datasets presents challenges for training models tailored to specific tasks and modalities of interest. Unsupervised cross-modal knowledge transfer offers a promising solution by leveraging knowledge from an existing modality to support model training for a new modality. Existing methods are typically based on knowledge distillation, which requires running a teacher model alongside student model training, resulting in high computational and memory overhead. This challenge is further exacerbated by the recent development of foundation models that demonstrate superior performance and generalization across tasks at the cost of large model sizes. To this end, we explore a new framework for unsupervised cross-modal knowledge transfer of biosignals by training a lightweight bridge network to align the intermediate representations and enable information flow between foundation models and across modalities. Specifically, we introduce an efficient strategy for selecting alignment positions where the bridge should be constructed, along with a flexible prototype network as the bridge architecture. Extensive experiments across multiple biosignal modalities, tasks, and datasets show that BioX-Bridge reduces the number of trainable parameters by 88--99\% while maintaining or even improving transfer performance compared to state-of-the-art methods.
AnchorInv: Few-Shot Class-Incremental Learning of Physiological Signals via Representation Space Guided Inversion
Dec 18, 2024



Deep learning models have demonstrated exceptional performance in a variety of real-world applications. These successes are often attributed to strong base models that can generalize to novel tasks with limited supporting data while keeping prior knowledge intact. However, these impressive results are based on the availability of a large amount of high-quality data, which is often lacking in specialized biomedical applications. In such fields, models are usually developed with limited data that arrive incrementally with novel categories. This requires the model to adapt to new information while preserving existing knowledge. Few-Shot Class-Incremental Learning (FSCIL) methods offer a promising approach to addressing these challenges, but they also depend on strong base models that face the same aforementioned limitations. To overcome these constraints, we propose AnchorInv following the straightforward and efficient buffer-replay strategy. Instead of selecting and storing raw data, AnchorInv generates synthetic samples guided by anchor points in the feature space. This approach protects privacy and regularizes the model for adaptation. When evaluated on three public physiological time series datasets, AnchorInv exhibits efficient knowledge forgetting prevention and improved adaptation to novel classes, surpassing state-of-the-art baselines.
A Survey of Few-Shot Learning for Biomedical Time Series
May 03, 2024



Advancements in wearable sensor technologies and the digitization of medical records have contributed to the unprecedented ubiquity of biomedical time series data. Data-driven models have tremendous potential to assist clinical diagnosis and improve patient care by improving long-term monitoring capabilities, facilitating early disease detection and intervention, as well as promoting personalized healthcare delivery. However, accessing extensively labeled datasets to train data-hungry deep learning models encounters many barriers, such as long-tail distribution of rare diseases, cost of annotation, privacy and security concerns, data-sharing regulations, and ethical considerations. An emerging approach to overcome the scarcity of labeled data is to augment AI methods with human-like capabilities to leverage past experiences to learn new tasks with limited examples, called few-shot learning. This survey provides a comprehensive review and comparison of few-shot learning methods for biomedical time series applications. The clinical benefits and limitations of such methods are discussed in relation to traditional data-driven approaches. This paper aims to provide insights into the current landscape of few-shot learning for biomedical time series and its implications for future research and applications.
PCGen: Point Cloud Generator for LiDAR Simulation
Oct 17, 2022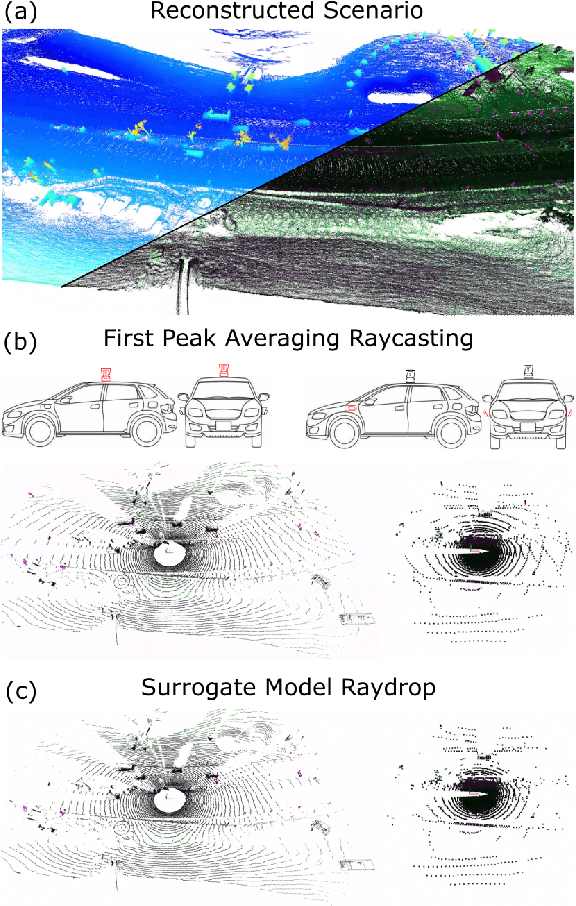
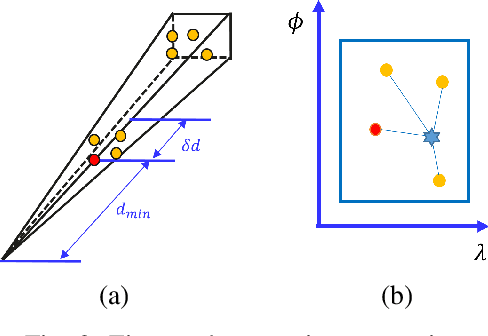
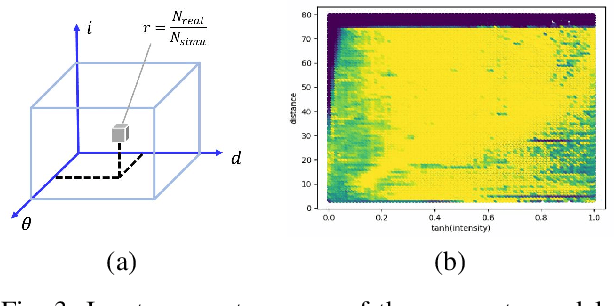
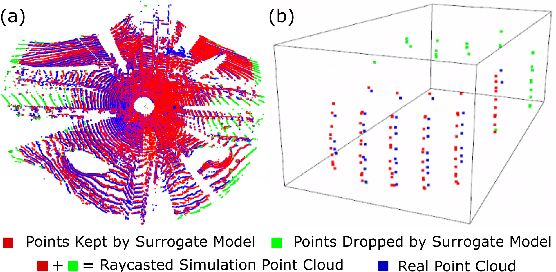
Data is a fundamental building block for LiDAR perception systems. Unfortunately, real-world data collection and annotation is extremely costly & laborious. Recently, real data based LiDAR simulators have shown tremendous potential to complement real data, due to their scalability and high-fidelity compared to graphics engine based methods. Before simulation can be deployed in the real-world, two shortcomings need to be addressed. First, existing methods usually generate data which are more noisy and complete than the real point clouds, due to 3D reconstruction error and pure geometry-based raycasting method. Second, prior works on simulation for object detection focus solely on rigid objects, like cars, but VRUs, like pedestrians, are important road participants. To tackle the first challenge, we propose FPA raycasting and surrogate model raydrop. FPA enables the simulation of both point cloud coordinates and sensor features, while taking into account reconstruction noise. The ray-wise surrogate raydrop model mimics the physical properties of LiDAR's laser receiver to determine whether a simulated point would be recorded by a real LiDAR. With minimal training data, the surrogate model can generalize to different geographies and scenes, closing the domain gap between raycasted and real point clouds. To tackle the simulation of deformable VRU simulation, we employ SMPL dataset to provide a pedestrian simulation baseline and compare the domain gap between CAD and reconstructed objects. Applying our pipeline to perform novel sensor synthesis, results show that object detection models trained by simulation data can achieve similar result as the real data trained model.
Seizure Detection and Prediction by Parallel Memristive Convolutional Neural Networks
Jun 20, 2022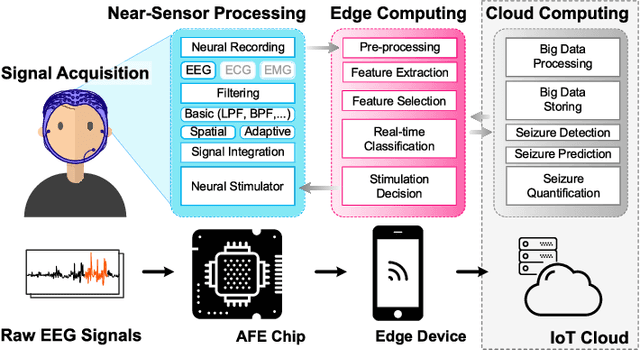
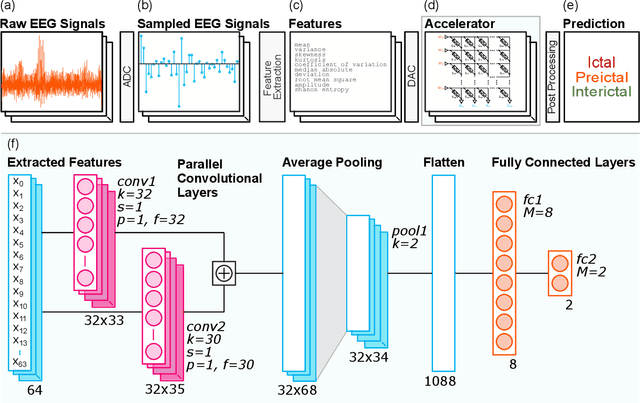
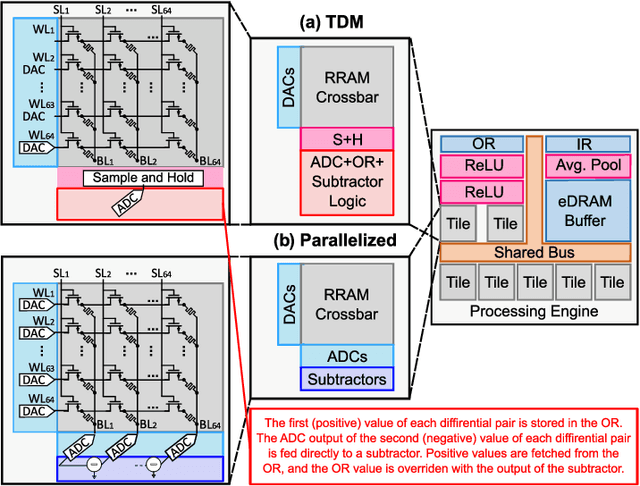
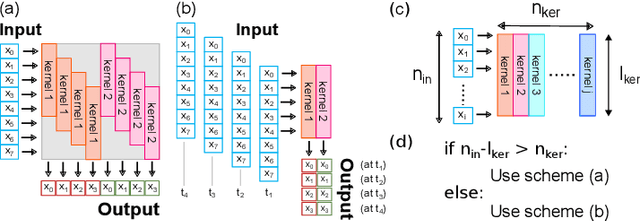
During the past two decades, epileptic seizure detection and prediction algorithms have evolved rapidly. However, despite significant performance improvements, their hardware implementation using conventional technologies, such as Complementary Metal-Oxide-Semiconductor (CMOS), in power and area-constrained settings remains a challenging task; especially when many recording channels are used. In this paper, we propose a novel low-latency parallel Convolutional Neural Network (CNN) architecture that has between 2-2,800x fewer network parameters compared to SOTA CNN architectures and achieves 5-fold cross validation accuracy of 99.84% for epileptic seizure detection, and 99.01% and 97.54% for epileptic seizure prediction, when evaluated using the University of Bonn Electroencephalogram (EEG), CHB-MIT and SWEC-ETHZ seizure datasets, respectively. We subsequently implement our network onto analog crossbar arrays comprising Resistive Random-Access Memory (RRAM) devices, and provide a comprehensive benchmark by simulating, laying out, and determining hardware requirements of the CNN component of our system. To the best of our knowledge, we are the first to parallelize the execution of convolution layer kernels on separate analog crossbars to enable 2 orders of magnitude reduction in latency compared to SOTA hybrid Memristive-CMOS DL accelerators. Furthermore, we investigate the effects of non-idealities on our system and investigate Quantization Aware Training (QAT) to mitigate the performance degradation due to low ADC/DAC resolution. Finally, we propose a stuck weight offsetting methodology to mitigate performance degradation due to stuck RON/ROFF memristor weights, recovering up to 32% accuracy, without requiring retraining. The CNN component of our platform is estimated to consume approximately 2.791W of power while occupying an area of 31.255mm$^2$ in a 22nm FDSOI CMOS process.
* Accepted by IEEE Transactions on Biomedical Circuits and Systems
Design Space Exploration of Dense and Sparse Mapping Schemes for RRAM Architectures
Jan 25, 2022The impact of device and circuit-level effects in mixed-signal Resistive Random Access Memory (RRAM) accelerators typically manifest as performance degradation of Deep Learning (DL) algorithms, but the degree of impact varies based on algorithmic features. These include network architecture, capacity, weight distribution, and the type of inter-layer connections. Techniques are continuously emerging to efficiently train sparse neural networks, which may have activation sparsity, quantization, and memristive noise. In this paper, we present an extended Design Space Exploration (DSE) methodology to quantify the benefits and limitations of dense and sparse mapping schemes for a variety of network architectures. While sparsity of connectivity promotes less power consumption and is often optimized for extracting localized features, its performance on tiled RRAM arrays may be more susceptible to noise due to under-parameterization, when compared to dense mapping schemes. Moreover, we present a case study quantifying and formalizing the trade-offs of typical non-idealities introduced into 1-Transistor-1-Resistor (1T1R) tiled memristive architectures and the size of modular crossbar tiles using the CIFAR-10 dataset.