 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeADEPT: Adaptive Dynamic Early-Exit Process for Transformers
Jan 07, 2026The inference of large language models imposes significant computational workloads, often requiring the processing of billions of parameters. Although early-exit strategies have proven effective in reducing computational demands by halting inference earlier, they apply either to only the first token in the generation phase or at the prompt level in the prefill phase. Thus, the Key-Value (KV) cache for skipped layers remains a bottleneck for subsequent token generation, limiting the benefits of early exit. We introduce ADEPT (Adaptive Dynamic Early-exit Process for Transformers), a novel approach designed to overcome this issue and enable dynamic early exit in both the prefill and generation phases. The proposed adaptive token-level early-exit mechanism adjusts computation dynamically based on token complexity, optimizing efficiency without compromising performance. ADEPT further enhances KV generation procedure by decoupling sequential dependencies in skipped layers, making token-level early exit more practical. Experimental results demonstrate that ADEPT improves efficiency by up to 25% in language generation tasks and achieves a 4x speed-up in downstream classification tasks, with up to a 45% improvement in performance.
Compute-in-Memory Implementation of State Space Models for Event Sequence Processing
Nov 17, 2025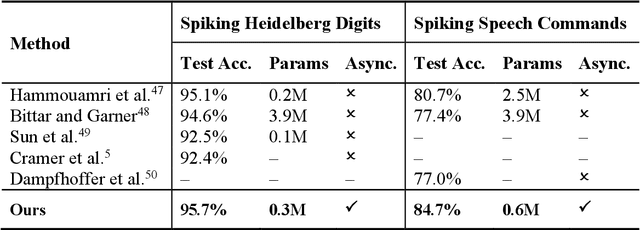
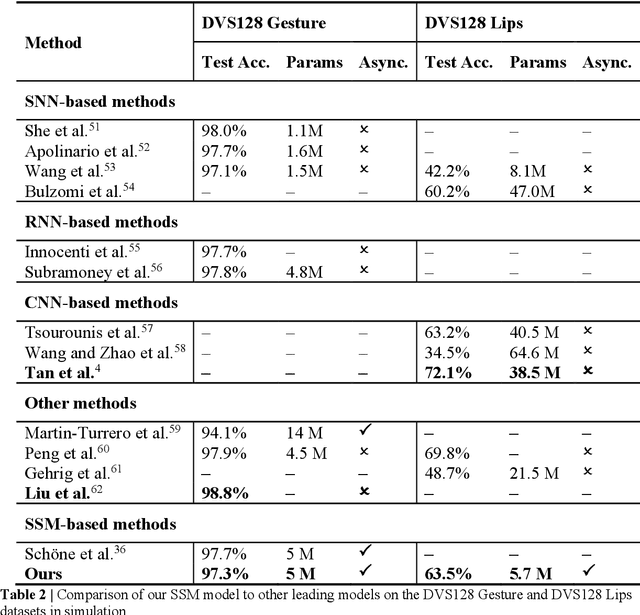
State space models (SSMs) have recently emerged as a powerful framework for long sequence processing, outperforming traditional methods on diverse benchmarks. Fundamentally, SSMs can generalize both recurrent and convolutional networks and have been shown to even capture key functions of biological systems. Here we report an approach to implement SSMs in energy-efficient compute-in-memory (CIM) hardware to achieve real-time, event-driven processing. Our work re-parameterizes the model to function with real-valued coefficients and shared decay constants, reducing the complexity of model mapping onto practical hardware systems. By leveraging device dynamics and diagonalized state transition parameters, the state evolution can be natively implemented in crossbar-based CIM systems combined with memristors exhibiting short-term memory effects. Through this algorithm and hardware co-design, we show the proposed system offers both high accuracy and high energy efficiency while supporting fully asynchronous processing for event-based vision and audio tasks.
Bulk-Switching Memristor-based Compute-In-Memory Module for Deep Neural Network Training
May 23, 2023The need for deep neural network (DNN) models with higher performance and better functionality leads to the proliferation of very large models. Model training, however, requires intensive computation time and energy. Memristor-based compute-in-memory (CIM) modules can perform vector-matrix multiplication (VMM) in situ and in parallel, and have shown great promises in DNN inference applications. However, CIM-based model training faces challenges due to non-linear weight updates, device variations, and low-precision in analog computing circuits. In this work, we experimentally implement a mixed-precision training scheme to mitigate these effects using a bulk-switching memristor CIM module. Lowprecision CIM modules are used to accelerate the expensive VMM operations, with high precision weight updates accumulated in digital units. Memristor devices are only changed when the accumulated weight update value exceeds a pre-defined threshold. The proposed scheme is implemented with a system-on-chip (SoC) of fully integrated analog CIM modules and digital sub-systems, showing fast convergence of LeNet training to 97.73%. The efficacy of training larger models is evaluated using realistic hardware parameters and shows that that analog CIM modules can enable efficient mix-precision DNN training with accuracy comparable to full-precision software trained models. Additionally, models trained on chip are inherently robust to hardware variations, allowing direct mapping to CIM inference chips without additional re-training.
PowerGAN: A Machine Learning Approach for Power Side-Channel Attack on Compute-in-Memory Accelerators
Apr 13, 2023Analog compute-in-memory (CIM) accelerators are becoming increasingly popular for deep neural network (DNN) inference due to their energy efficiency and in-situ vector-matrix multiplication (VMM) capabilities. However, as the use of DNNs expands, protecting user input privacy has become increasingly important. In this paper, we identify a security vulnerability wherein an adversary can reconstruct the user's private input data from a power side-channel attack, under proper data acquisition and pre-processing, even without knowledge of the DNN model. We further demonstrate a machine learning-based attack approach using a generative adversarial network (GAN) to enhance the reconstruction. Our results show that the attack methodology is effective in reconstructing user inputs from analog CIM accelerator power leakage, even when at large noise levels and countermeasures are applied. Specifically, we demonstrate the efficacy of our approach on the U-Net for brain tumor detection in magnetic resonance imaging (MRI) medical images, with a noise-level of 20% standard deviation of the maximum power signal value. Our study highlights a significant security vulnerability in analog CIM accelerators and proposes an effective attack methodology using a GAN to breach user privacy.
RN-Net: Reservoir Nodes-Enabled Neuromorphic Vision Sensing Network
Mar 21, 2023Event-based cameras are inspired by the sparse and asynchronous spike representation of the biological visual system. However, processing the even data requires either using expensive feature descriptors to transform spikes into frames, or using spiking neural networks that are difficult to train. In this work, we propose a neural network architecture based on simple convolution layers integrated with dynamic temporal encoding reservoirs with low hardware and training costs. The Reservoir Nodes-enabled neuromorphic vision sensing Network (RN-Net) allows the network to efficiently process asynchronous temporal features, and achieves the highest accuracy of 99.2% for DVS128 Gesture reported to date, and one of the highest accuracy of 67.5% for DVS Lip dataset at a much smaller network size. By leveraging the internal dynamics of memristors, asynchronous temporal feature encoding can be implemented at very low hardware cost without preprocessing or dedicated memory and arithmetic units. The use of simple DNN blocks and backpropagation based training rules further reduces its implementation cost. Code will be publicly available.
Intelligence Processing Units Accelerate Neuromorphic Learning
Nov 19, 2022



Spiking neural networks (SNNs) have achieved orders of magnitude improvement in terms of energy consumption and latency when performing inference with deep learning workloads. Error backpropagation is presently regarded as the most effective method for training SNNs, but in a twist of irony, when training on modern graphics processing units (GPUs) this becomes more expensive than non-spiking networks. The emergence of Graphcore's Intelligence Processing Units (IPUs) balances the parallelized nature of deep learning workloads with the sequential, reusable, and sparsified nature of operations prevalent when training SNNs. IPUs adopt multi-instruction multi-data (MIMD) parallelism by running individual processing threads on smaller data blocks, which is a natural fit for the sequential, non-vectorized steps required to solve spiking neuron dynamical state equations. We present an IPU-optimized release of our custom SNN Python package, snnTorch, which exploits fine-grained parallelism by utilizing low-level, pre-compiled custom operations to accelerate irregular and sparse data access patterns that are characteristic of training SNN workloads. We provide a rigorous performance assessment across a suite of commonly used spiking neuron models, and propose methods to further reduce training run-time via half-precision training. By amortizing the cost of sequential processing into vectorizable population codes, we ultimately demonstrate the potential for integrating domain-specific accelerators with the next generation of neural networks.
Gradient-based Neuromorphic Learning on Dynamical RRAM Arrays
Jun 26, 2022

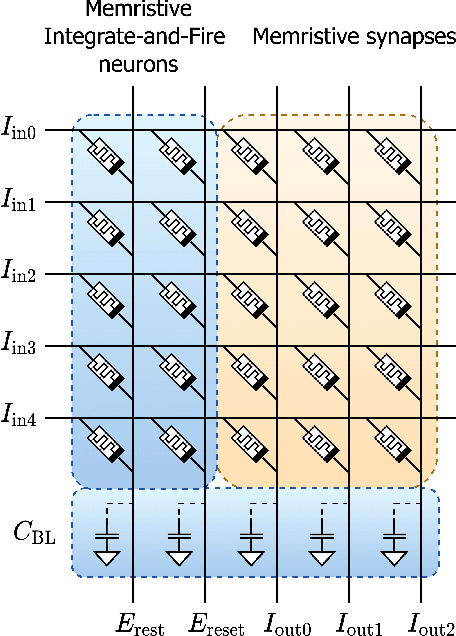
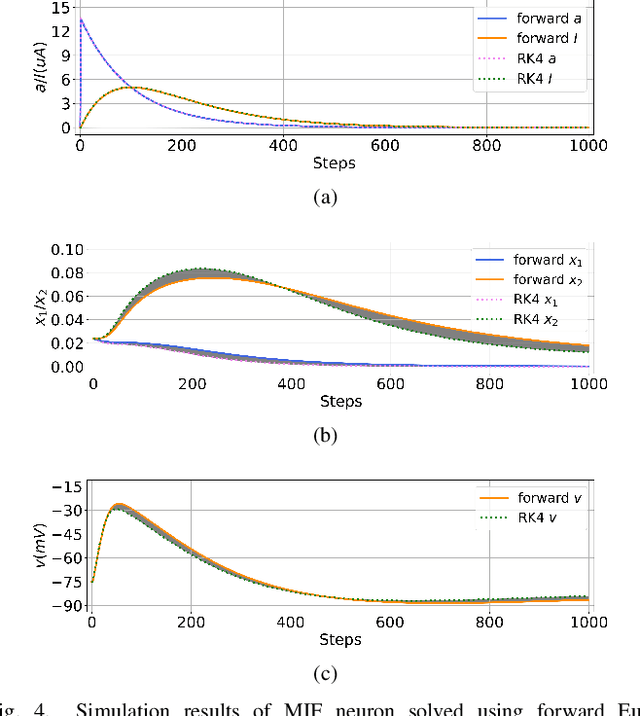
We present MEMprop, the adoption of gradient-based learning to train fully memristive spiking neural networks (MSNNs). Our approach harnesses intrinsic device dynamics to trigger naturally arising voltage spikes. These spikes emitted by memristive dynamics are analog in nature, and thus fully differentiable, which eliminates the need for surrogate gradient methods that are prevalent in the spiking neural network (SNN) literature. Memristive neural networks typically either integrate memristors as synapses that map offline-trained networks, or otherwise rely on associative learning mechanisms to train networks of memristive neurons. We instead apply the backpropagation through time (BPTT) training algorithm directly on analog SPICE models of memristive neurons and synapses. Our implementation is fully memristive, in that synaptic weights and spiking neurons are both integrated on resistive RAM (RRAM) arrays without the need for additional circuits to implement spiking dynamics, e.g., analog-to-digital converters (ADCs) or thresholded comparators. As a result, higher-order electrophysical effects are fully exploited to use the state-driven dynamics of memristive neurons at run time. By moving towards non-approximate gradient-based learning, we obtain highly competitive accuracy amongst previously reported lightweight dense fully MSNNs on several benchmarks.
Navigating Local Minima in Quantized Spiking Neural Networks
Feb 15, 2022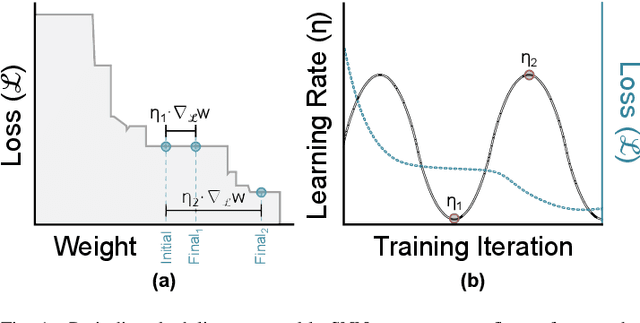
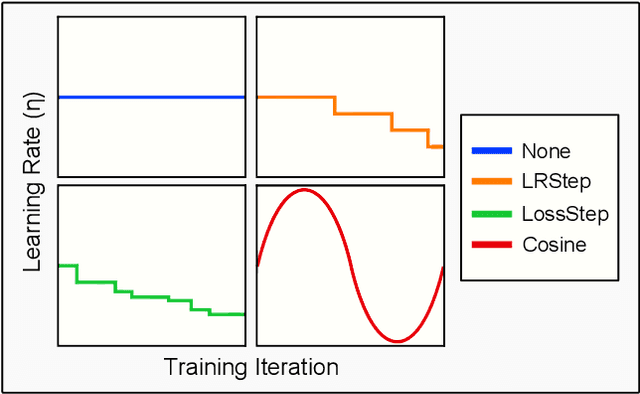
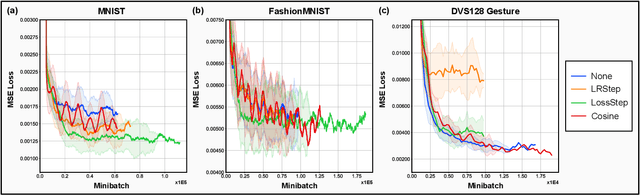
Spiking and Quantized Neural Networks (NNs) are becoming exceedingly important for hyper-efficient implementations of Deep Learning (DL) algorithms. However, these networks face challenges when trained using error backpropagation, due to the absence of gradient signals when applying hard thresholds. The broadly accepted trick to overcoming this is through the use of biased gradient estimators: surrogate gradients which approximate thresholding in Spiking Neural Networks (SNNs), and Straight-Through Estimators (STEs), which completely bypass thresholding in Quantized Neural Networks (QNNs). While noisy gradient feedback has enabled reasonable performance on simple supervised learning tasks, it is thought that such noise increases the difficulty of finding optima in loss landscapes, especially during the later stages of optimization. By periodically boosting the Learning Rate (LR) during training, we expect the network can navigate unexplored solution spaces that would otherwise be difficult to reach due to local minima, barriers, or flat surfaces. This paper presents a systematic evaluation of a cosine-annealed LR schedule coupled with weight-independent adaptive moment estimation as applied to Quantized SNNs (QSNNs). We provide a rigorous empirical evaluation of this technique on high precision and 4-bit quantized SNNs across three datasets, demonstrating (close to) state-of-the-art performance on the more complex datasets. Our source code is available at this link: https://github.com/jeshraghian/QSNNs.
The fine line between dead neurons and sparsity in binarized spiking neural networks
Jan 28, 2022

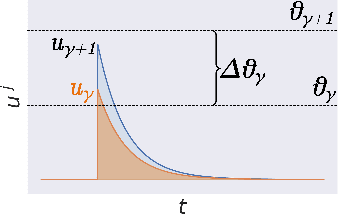

Spiking neural networks can compensate for quantization error by encoding information either in the temporal domain, or by processing discretized quantities in hidden states of higher precision. In theory, a wide dynamic range state-space enables multiple binarized inputs to be accumulated together, thus improving the representational capacity of individual neurons. This may be achieved by increasing the firing threshold, but make it too high and sparse spike activity turns into no spike emission. In this paper, we propose the use of `threshold annealing' as a warm-up method for firing thresholds. We show it enables the propagation of spikes across multiple layers where neurons would otherwise cease to fire, and in doing so, achieve highly competitive results on four diverse datasets, despite using binarized weights. Source code is available at https://github.com/jeshraghian/snn-tha/
Design Space Exploration of Dense and Sparse Mapping Schemes for RRAM Architectures
Jan 25, 2022The impact of device and circuit-level effects in mixed-signal Resistive Random Access Memory (RRAM) accelerators typically manifest as performance degradation of Deep Learning (DL) algorithms, but the degree of impact varies based on algorithmic features. These include network architecture, capacity, weight distribution, and the type of inter-layer connections. Techniques are continuously emerging to efficiently train sparse neural networks, which may have activation sparsity, quantization, and memristive noise. In this paper, we present an extended Design Space Exploration (DSE) methodology to quantify the benefits and limitations of dense and sparse mapping schemes for a variety of network architectures. While sparsity of connectivity promotes less power consumption and is often optimized for extracting localized features, its performance on tiled RRAM arrays may be more susceptible to noise due to under-parameterization, when compared to dense mapping schemes. Moreover, we present a case study quantifying and formalizing the trade-offs of typical non-idealities introduced into 1-Transistor-1-Resistor (1T1R) tiled memristive architectures and the size of modular crossbar tiles using the CIFAR-10 dataset.