 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Manycore Processors with Distributed Memory for Accelerated Training of Sparse and Recurrent Models
Nov 07, 2023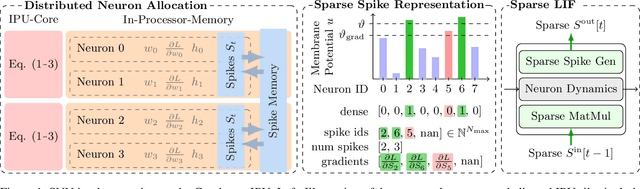

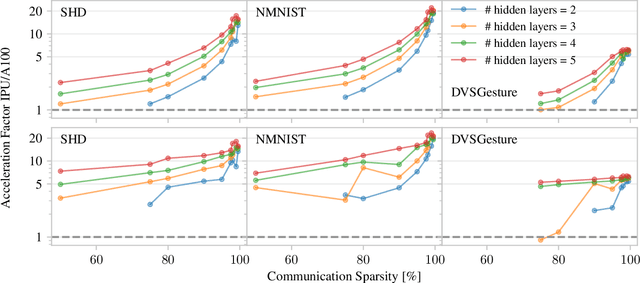
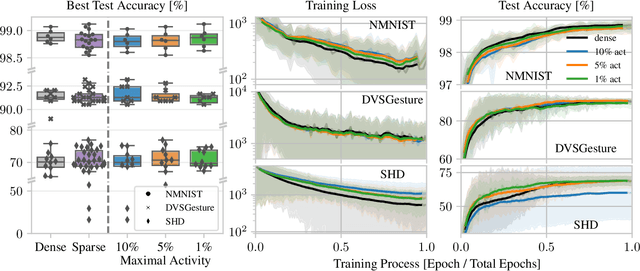
Current AI training infrastructure is dominated by single instruction multiple data (SIMD) and systolic array architectures, such as Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs), that excel at accelerating parallel workloads and dense vector matrix multiplications. Potentially more efficient neural network models utilizing sparsity and recurrence cannot leverage the full power of SIMD processor and are thus at a severe disadvantage compared to today's prominent parallel architectures like Transformers and CNNs, thereby hindering the path towards more sustainable AI. To overcome this limitation, we explore sparse and recurrent model training on a massively parallel multiple instruction multiple data (MIMD) architecture with distributed local memory. We implement a training routine based on backpropagation through time (BPTT) for the brain-inspired class of Spiking Neural Networks (SNNs) that feature binary sparse activations. We observe a massive advantage in using sparse activation tensors with a MIMD processor, the Intelligence Processing Unit (IPU) compared to GPUs. On training workloads, our results demonstrate 5-10x throughput gains compared to A100 GPUs and up to 38x gains for higher levels of activation sparsity, without a significant slowdown in training convergence or reduction in final model performance. Furthermore, our results show highly promising trends for both single and multi IPU configurations as we scale up to larger model sizes. Our work paves the way towards more efficient, non-standard models via AI training hardware beyond GPUs, and competitive large scale SNN models.
Intelligence Processing Units Accelerate Neuromorphic Learning
Nov 19, 2022



Spiking neural networks (SNNs) have achieved orders of magnitude improvement in terms of energy consumption and latency when performing inference with deep learning workloads. Error backpropagation is presently regarded as the most effective method for training SNNs, but in a twist of irony, when training on modern graphics processing units (GPUs) this becomes more expensive than non-spiking networks. The emergence of Graphcore's Intelligence Processing Units (IPUs) balances the parallelized nature of deep learning workloads with the sequential, reusable, and sparsified nature of operations prevalent when training SNNs. IPUs adopt multi-instruction multi-data (MIMD) parallelism by running individual processing threads on smaller data blocks, which is a natural fit for the sequential, non-vectorized steps required to solve spiking neuron dynamical state equations. We present an IPU-optimized release of our custom SNN Python package, snnTorch, which exploits fine-grained parallelism by utilizing low-level, pre-compiled custom operations to accelerate irregular and sparse data access patterns that are characteristic of training SNN workloads. We provide a rigorous performance assessment across a suite of commonly used spiking neuron models, and propose methods to further reduce training run-time via half-precision training. By amortizing the cost of sequential processing into vectorizable population codes, we ultimately demonstrate the potential for integrating domain-specific accelerators with the next generation of neural networks.