 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 32-Channel 3.53-μW Per Channel Brain-Machine Interface SoC Featuring Dual-Threshold Delta-modulation, In-Memory Spike Detection and Bi-SNN Based Motor Decoding
Jun 01, 2026With the scaling of sensor channel counts, systems confront challenges in frontend data sensing and on-implant data processing. This work presents a 32-channel fully event-based iBMI SoC in 65nm CMOS for an efficient neuromorphic signal processing pipeline. The SoC integrates a 32-channel dual-threshold delta modulation (DTDM) frontend array that provides up to 26x data compression at the frontend, an in-memory computing (IMC) spike detector (SPD) for efficient in-pixel spike detection, and a bipolar LIF-based spiking neural network (Bi-SNN) decoder for on-chip motor intention decoding (MID). Consuming only 3.53 μW per channel and achieving ~0.62 decoding R2 with a compact 0.034 mm2 per-channel area, the chip enables high-efficiency signal recording, processing, and decoding for implantable devices.
SPACE: SPike-Aware Consistency Enhancement for Test-Time Adaptation in Spiking Neural Networks
Apr 03, 2025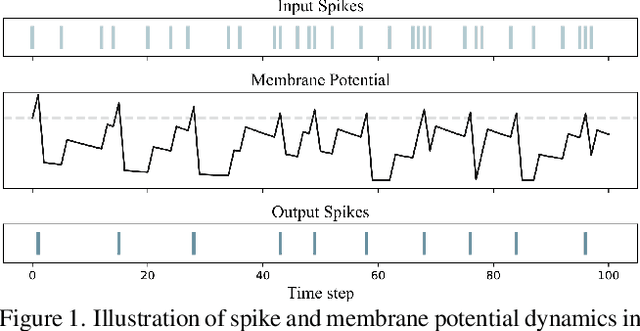

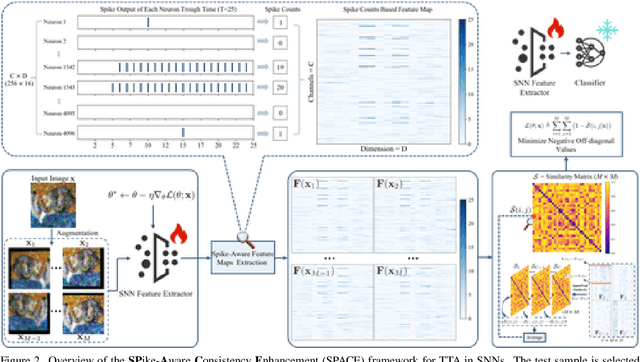

Spiking Neural Networks (SNNs), as a biologically plausible alternative to Artificial Neural Networks (ANNs), have demonstrated advantages in terms of energy efficiency, temporal processing, and biological plausibility. However, SNNs are highly sensitive to distribution shifts, which can significantly degrade their performance in real-world scenarios. Traditional test-time adaptation (TTA) methods designed for ANNs often fail to address the unique computational dynamics of SNNs, such as sparsity and temporal spiking behavior. To address these challenges, we propose $\textbf{SP}$ike-$\textbf{A}$ware $\textbf{C}$onsistency $\textbf{E}$nhancement (SPACE), the first source-free and single-instance TTA method specifically designed for SNNs. SPACE leverages the inherent spike dynamics of SNNs to maximize the consistency of spike-behavior-based local feature maps across augmented versions of a single test sample, enabling robust adaptation without requiring source data. We evaluate SPACE on multiple datasets, including CIFAR-10-C, CIFAR-100-C, Tiny-ImageNet-C and DVS Gesture-C. Furthermore, SPACE demonstrates strong generalization across different model architectures, achieving consistent performance improvements on both VGG9 and ResNet11. Experimental results show that SPACE outperforms state-of-the-art methods, highlighting its effectiveness and robustness in real-world settings.
Memory Efficient Corner Detection for Event-driven Dynamic Vision Sensors
Jan 18, 2024

Event cameras offer low-latency and data compression for visual applications, through event-driven operation, that can be exploited for edge processing in tiny autonomous agents. Robust, accurate and low latency extraction of highly informative features such as corners is key for most visual processing. While several corner detection algorithms have been proposed, state-of-the-art performance is achieved by luvHarris. However, this algorithm requires a high number of memory accesses per event, making it less-than ideal for low-latency, low-energy implementation in tiny edge processors. In this paper, we propose a new event-driven corner detection implementation tailored for edge computing devices, which requires much lower memory access than luvHarris while also improving accuracy. Our method trades computation for memory access, which is more expensive for large memories. For a DAVIS346 camera, our method requires ~3.8X less memory, ~36.6X less memory accesses with only ~2.3X more computes.
ANN vs SNN: A case study for Neural Decoding in Implantable Brain-Machine Interfaces
Dec 26, 2023While it is important to make implantable brain-machine interfaces (iBMI) wireless to increase patient comfort and safety, the trend of increased channel count in recent neural probes poses a challenge due to the concomitant increase in the data rate. Extracting information from raw data at the source by using edge computing is a promising solution to this problem, with integrated intention decoders providing the best compression ratio. In this work, we compare different neural networks (NN) for motor decoding in terms of accuracy and implementation cost. We further show that combining traditional signal processing techniques with machine learning ones deliver surprisingly good performance even with simple NNs. Adding a block Bidirectional Bessel filter provided maximum gains of $\approx 0.05$, $0.04$ and $0.03$ in $R^2$ for ANN\_3d, SNN\_3D and ANN models, while the gains were lower ($\approx 0.02$ or less) for LSTM and SNN\_streaming models. Increasing training data helped improve the $R^2$ of all models by $0.03-0.04$ indicating they have more capacity for future improvement. In general, LSTM and SNN\_streaming models occupy the high and low ends of the pareto curves (for accuracy vs. memory/operations) respectively while SNN\_3D and ANN\_3D occupy intermediate positions. Our work presents state of the art results for this dataset and paves the way for decoder-integrated-implants of the future.
Intelligence Processing Units Accelerate Neuromorphic Learning
Nov 19, 2022



Spiking neural networks (SNNs) have achieved orders of magnitude improvement in terms of energy consumption and latency when performing inference with deep learning workloads. Error backpropagation is presently regarded as the most effective method for training SNNs, but in a twist of irony, when training on modern graphics processing units (GPUs) this becomes more expensive than non-spiking networks. The emergence of Graphcore's Intelligence Processing Units (IPUs) balances the parallelized nature of deep learning workloads with the sequential, reusable, and sparsified nature of operations prevalent when training SNNs. IPUs adopt multi-instruction multi-data (MIMD) parallelism by running individual processing threads on smaller data blocks, which is a natural fit for the sequential, non-vectorized steps required to solve spiking neuron dynamical state equations. We present an IPU-optimized release of our custom SNN Python package, snnTorch, which exploits fine-grained parallelism by utilizing low-level, pre-compiled custom operations to accelerate irregular and sparse data access patterns that are characteristic of training SNN workloads. We provide a rigorous performance assessment across a suite of commonly used spiking neuron models, and propose methods to further reduce training run-time via half-precision training. By amortizing the cost of sequential processing into vectorizable population codes, we ultimately demonstrate the potential for integrating domain-specific accelerators with the next generation of neural networks.