 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Manycore Processors with Distributed Memory for Accelerated Training of Sparse and Recurrent Models
Nov 07, 2023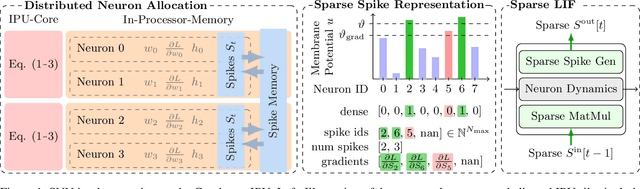

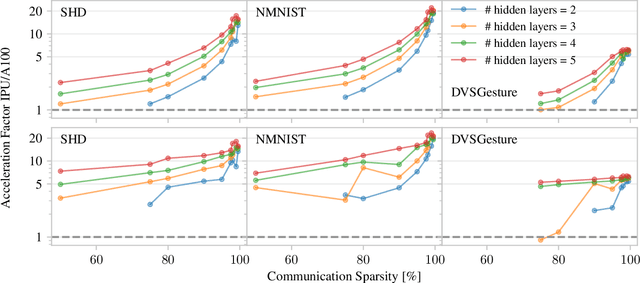
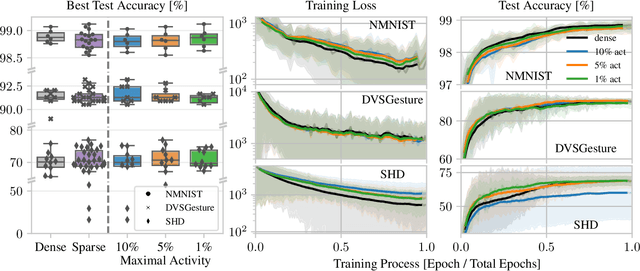
Current AI training infrastructure is dominated by single instruction multiple data (SIMD) and systolic array architectures, such as Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs), that excel at accelerating parallel workloads and dense vector matrix multiplications. Potentially more efficient neural network models utilizing sparsity and recurrence cannot leverage the full power of SIMD processor and are thus at a severe disadvantage compared to today's prominent parallel architectures like Transformers and CNNs, thereby hindering the path towards more sustainable AI. To overcome this limitation, we explore sparse and recurrent model training on a massively parallel multiple instruction multiple data (MIMD) architecture with distributed local memory. We implement a training routine based on backpropagation through time (BPTT) for the brain-inspired class of Spiking Neural Networks (SNNs) that feature binary sparse activations. We observe a massive advantage in using sparse activation tensors with a MIMD processor, the Intelligence Processing Unit (IPU) compared to GPUs. On training workloads, our results demonstrate 5-10x throughput gains compared to A100 GPUs and up to 38x gains for higher levels of activation sparsity, without a significant slowdown in training convergence or reduction in final model performance. Furthermore, our results show highly promising trends for both single and multi IPU configurations as we scale up to larger model sizes. Our work paves the way towards more efficient, non-standard models via AI training hardware beyond GPUs, and competitive large scale SNN models.
Bundle Adjustment on a Graph Processor
Mar 30, 2020

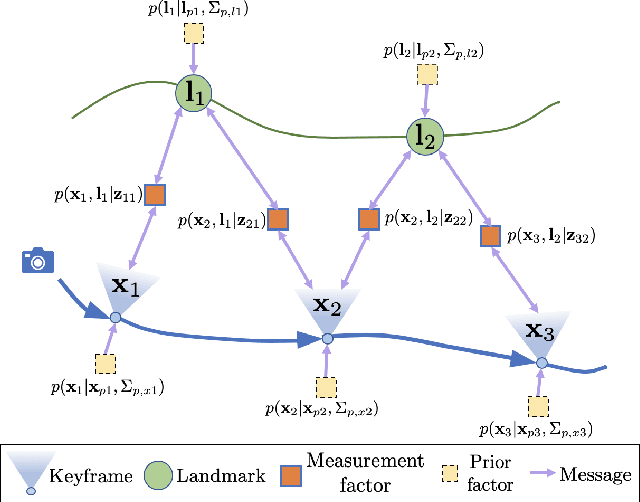

Graph processors such as Graphcore's Intelligence Processing Unit (IPU) are part of the major new wave of novel computer architecture for AI, and have a general design with massively parallel computation, distributed on-chip memory and very high inter-core communication bandwidth which allows breakthrough performance for message passing algorithms on arbitrary graphs. We show for the first time that the classical computer vision problem of bundle adjustment (BA) can be solved extremely fast on a graph processor using Gaussian Belief Propagation. Our simple but fully parallel implementation uses the 1216 cores on a single IPU chip to, for instance, solve a real BA problem with 125 keyframes and 1919 points in under 40ms, compared to 1450ms for the Ceres CPU library. Further code optimisation will surely increase this difference on static problems, but we argue that the real promise of graph processing is for flexible in-place optimisation of general, dynamically changing factor graphs representing Spatial AI problems. We give indications of this with experiments showing the ability of GBP to efficiently solve incremental SLAM problems, and deal with robust cost functions and different types of factors.