 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroMorse: A Temporally Structured Dataset For Neuromorphic Computing
Feb 28, 2025Neuromorphic engineering aims to advance computing by mimicking the brain's efficient processing, where data is encoded as asynchronous temporal events. This eliminates the need for a synchronisation clock and minimises power consumption when no data is present. However, many benchmarks for neuromorphic algorithms primarily focus on spatial features, neglecting the temporal dynamics that are inherent to most sequence-based tasks. This gap may lead to evaluations that fail to fully capture the unique strengths and characteristics of neuromorphic systems. In this paper, we present NeuroMorse, a temporally structured dataset designed for benchmarking neuromorphic learning systems. NeuroMorse converts the top 50 words in the English language into temporal Morse code spike sequences. Despite using only two input spike channels for Morse dots and dashes, complex information is encoded through temporal patterns in the data. The proposed benchmark contains feature hierarchy at multiple temporal scales that test the capacity of neuromorphic algorithms to decompose input patterns into spatial and temporal hierarchies. We demonstrate that our training set is challenging to categorise using a linear classifier and that identifying keywords in the test set is difficult using conventional methods. The NeuroMorse dataset is available at Zenodo, with our accompanying code on GitHub at https://github.com/Ben-E-Walters/NeuroMorse.
Seizure Detection and Prediction by Parallel Memristive Convolutional Neural Networks
Jun 20, 2022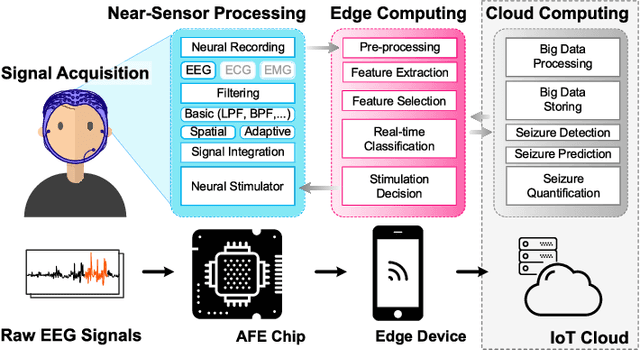
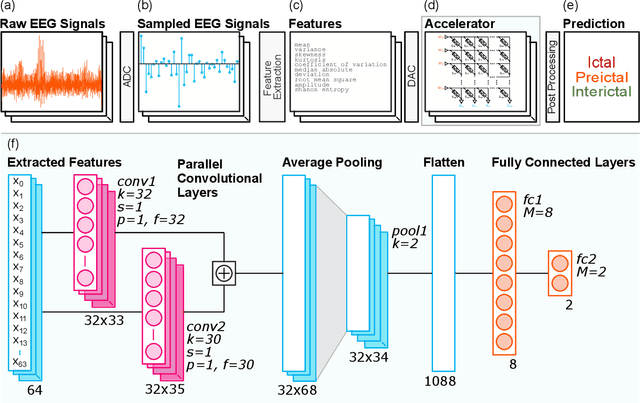
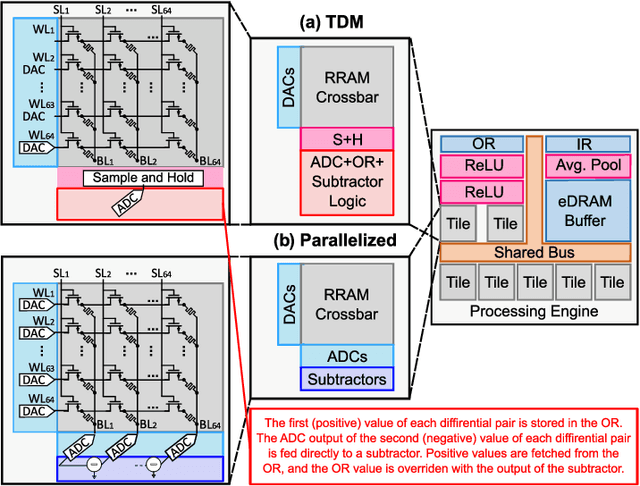
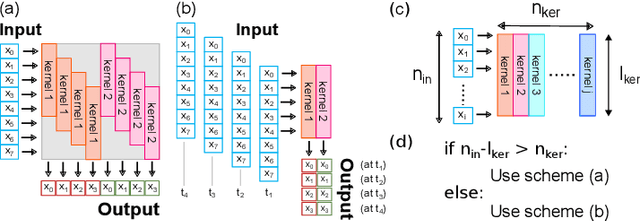
During the past two decades, epileptic seizure detection and prediction algorithms have evolved rapidly. However, despite significant performance improvements, their hardware implementation using conventional technologies, such as Complementary Metal-Oxide-Semiconductor (CMOS), in power and area-constrained settings remains a challenging task; especially when many recording channels are used. In this paper, we propose a novel low-latency parallel Convolutional Neural Network (CNN) architecture that has between 2-2,800x fewer network parameters compared to SOTA CNN architectures and achieves 5-fold cross validation accuracy of 99.84% for epileptic seizure detection, and 99.01% and 97.54% for epileptic seizure prediction, when evaluated using the University of Bonn Electroencephalogram (EEG), CHB-MIT and SWEC-ETHZ seizure datasets, respectively. We subsequently implement our network onto analog crossbar arrays comprising Resistive Random-Access Memory (RRAM) devices, and provide a comprehensive benchmark by simulating, laying out, and determining hardware requirements of the CNN component of our system. To the best of our knowledge, we are the first to parallelize the execution of convolution layer kernels on separate analog crossbars to enable 2 orders of magnitude reduction in latency compared to SOTA hybrid Memristive-CMOS DL accelerators. Furthermore, we investigate the effects of non-idealities on our system and investigate Quantization Aware Training (QAT) to mitigate the performance degradation due to low ADC/DAC resolution. Finally, we propose a stuck weight offsetting methodology to mitigate performance degradation due to stuck RON/ROFF memristor weights, recovering up to 32% accuracy, without requiring retraining. The CNN component of our platform is estimated to consume approximately 2.791W of power while occupying an area of 31.255mm$^2$ in a 22nm FDSOI CMOS process.
* Accepted by IEEE Transactions on Biomedical Circuits and Systems
Toward A Formalized Approach for Spike Sorting Algorithms and Hardware Evaluation
May 13, 2022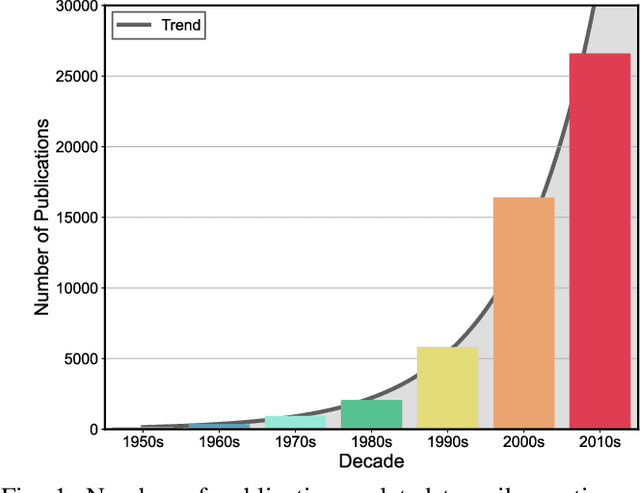
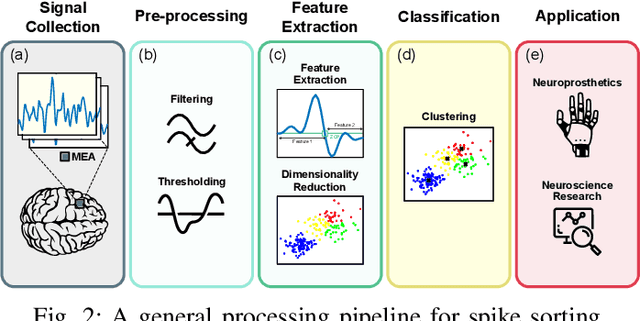
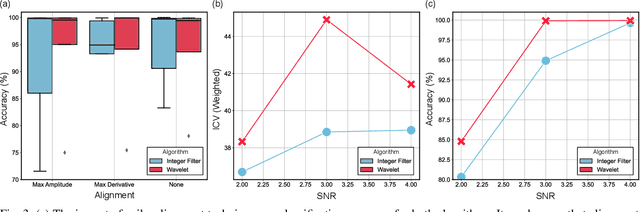
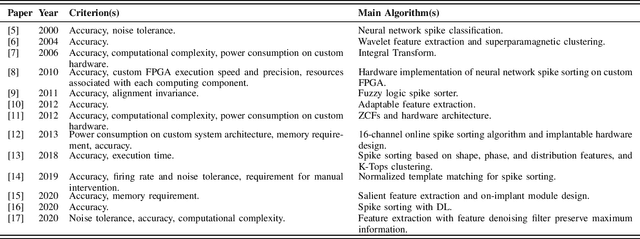
Spike sorting algorithms are used to separate extracellular recordings of neuronal populations into single-unit spike activities. The development of customized hardware implementing spike sorting algorithms is burgeoning. However, there is a lack of a systematic approach and a set of standardized evaluation criteria to facilitate direct comparison of both software and hardware implementations. In this paper, we formalize a set of standardized criteria and a publicly available synthetic dataset entitled Synthetic Simulations Of Extracellular Recordings (SSOER), which was constructed by aggregating existing synthetic datasets with varying Signal-To-Noise Ratios (SNRs). Furthermore, we present a benchmark for future comparison, and use our criteria to evaluate a simulated Resistive Random-Access Memory (RRAM) In-Memory Computing (IMC) system using the Discrete Wavelet Transform (DWT) for feature extraction. Our system consumes approximately (per channel) 10.72mW and occupies an area of 0.66mm$^2$ in a 22nm FDSOI Complementary Metal-Oxide-Semiconductor (CMOS) process.
PRUNIX: Non-Ideality Aware Convolutional Neural Network Pruning for Memristive Accelerators
Feb 03, 2022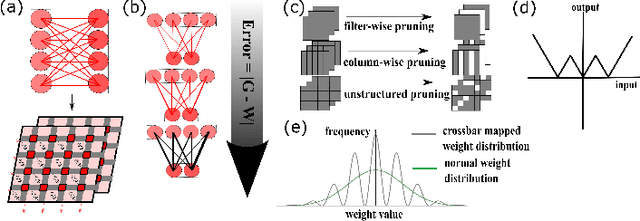
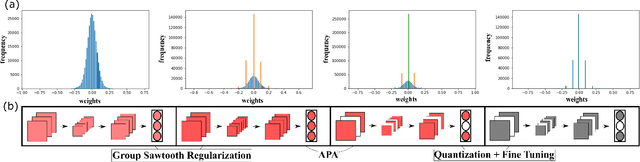
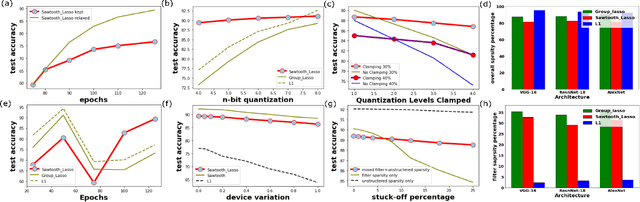
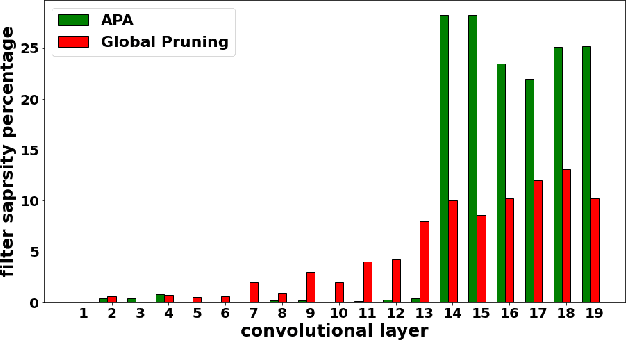
In this work, PRUNIX, a framework for training and pruning convolutional neural networks is proposed for deployment on memristor crossbar based accelerators. PRUNIX takes into account the numerous non-ideal effects of memristor crossbars including weight quantization, state-drift, aging and stuck-at-faults. PRUNIX utilises a novel Group Sawtooth Regularization intended to improve non-ideality tolerance as well as sparsity, and a novel Adaptive Pruning Algorithm (APA) intended to minimise accuracy loss by considering the sensitivity of different layers of a CNN to pruning. We compare our regularization and pruning methods with other standards on multiple CNN architectures, and observe an improvement of 13% test accuracy when quantization and other non-ideal effects are accounted for with an overall sparsity of 85%, which is similar to other methods
HYPERLOCK: In-Memory Hyperdimensional Encryption in Memristor Crossbar Array
Jan 27, 2022



We present a novel cryptography architecture based on memristor crossbar array, binary hypervectors, and neural network. Utilizing the stochastic and unclonable nature of memristor crossbar and error tolerance of binary hypervectors and neural network, implementation of the algorithm on memristor crossbar simulation is made possible. We demonstrate that with an increasing dimension of the binary hypervectors, the non-idealities in the memristor circuit can be effectively controlled. At the fine level of controlled crossbar non-ideality, noise from memristor circuit can be used to encrypt data while being sufficiently interpretable by neural network for decryption. We applied our algorithm on image cryptography for proof of concept, and to text en/decryption with 100% decryption accuracy despite crossbar noises. Our work shows the potential and feasibility of using memristor crossbars as an unclonable stochastic encoder unit of cryptography on top of their existing functionality as a vector-matrix multiplication acceleration device.
Design Space Exploration of Dense and Sparse Mapping Schemes for RRAM Architectures
Jan 25, 2022The impact of device and circuit-level effects in mixed-signal Resistive Random Access Memory (RRAM) accelerators typically manifest as performance degradation of Deep Learning (DL) algorithms, but the degree of impact varies based on algorithmic features. These include network architecture, capacity, weight distribution, and the type of inter-layer connections. Techniques are continuously emerging to efficiently train sparse neural networks, which may have activation sparsity, quantization, and memristive noise. In this paper, we present an extended Design Space Exploration (DSE) methodology to quantify the benefits and limitations of dense and sparse mapping schemes for a variety of network architectures. While sparsity of connectivity promotes less power consumption and is often optimized for extracting localized features, its performance on tiled RRAM arrays may be more susceptible to noise due to under-parameterization, when compared to dense mapping schemes. Moreover, we present a case study quantifying and formalizing the trade-offs of typical non-idealities introduced into 1-Transistor-1-Resistor (1T1R) tiled memristive architectures and the size of modular crossbar tiles using the CIFAR-10 dataset.