 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-TIME: An in-memory engine for accelerating machine learning on tabular data with CAMs
Apr 05, 2023



Structured, or tabular, data is the most common format in data science. While deep learning models have proven formidable in learning from unstructured data such as images or speech, they are less accurate than simpler approaches when learning from tabular data. In contrast, modern tree-based Machine Learning (ML) models shine in extracting relevant information from structured data. An essential requirement in data science is to reduce model inference latency in cases where, for example, models are used in a closed loop with simulation to accelerate scientific discovery. However, the hardware acceleration community has mostly focused on deep neural networks and largely ignored other forms of machine learning. Previous work has described the use of an analog content addressable memory (CAM) component for efficiently mapping random forests. In this work, we focus on an overall analog-digital architecture implementing a novel increased precision analog CAM and a programmable network on chip allowing the inference of state-of-the-art tree-based ML models, such as XGBoost and CatBoost. Results evaluated in a single chip at 16nm technology show 119x lower latency at 9740x higher throughput compared with a state-of-the-art GPU, with a 19W peak power consumption.
Hierarchical Architectures in Reservoir Computing Systems
May 14, 2021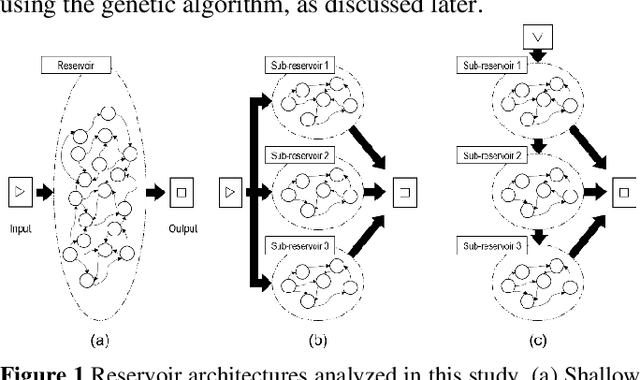
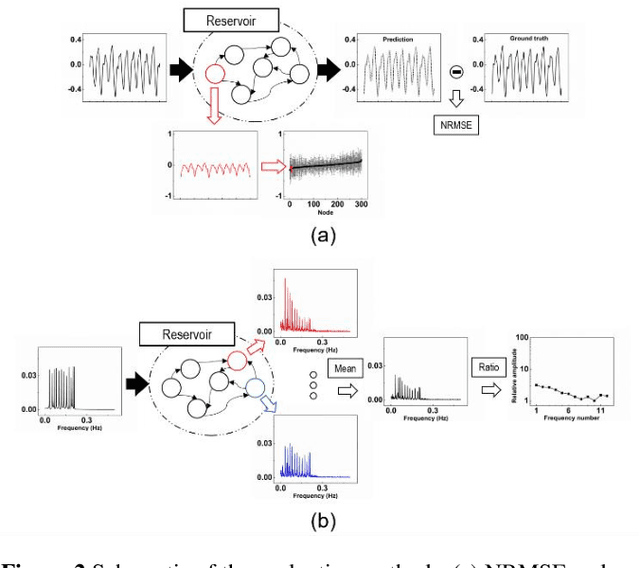


Reservoir computing (RC) offers efficient temporal data processing with a low training cost by separating recurrent neural networks into a fixed network with recurrent connections and a trainable linear network. The quality of the fixed network, called reservoir, is the most important factor that determines the performance of the RC system. In this paper, we investigate the influence of the hierarchical reservoir structure on the properties of the reservoir and the performance of the RC system. Analogous to deep neural networks, stacking sub-reservoirs in series is an efficient way to enhance the nonlinearity of data transformation to high-dimensional space and expand the diversity of temporal information captured by the reservoir. These deep reservoir systems offer better performance when compared to simply increasing the size of the reservoir or the number of sub-reservoirs. Low frequency components are mainly captured by the sub-reservoirs in later stage of the deep reservoir structure, similar to observations that more abstract information can be extracted by layers in the late stage of deep neural networks. When the total size of the reservoir is fixed, tradeoff between the number of sub-reservoirs and the size of each sub-reservoir needs to be carefully considered, due to the degraded ability of individual sub-reservoirs at small sizes. Improved performance of the deep reservoir structure alleviates the difficulty of implementing the RC system on hardware systems.