 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeech Lattice Vector Quantization for Efficient LLM Compression
Mar 11, 2026Scalar quantization of large language models (LLMs) is fundamentally limited by information-theoretic bounds. While vector quantization (VQ) overcomes these limits by encoding blocks of parameters jointly, practical implementations must avoid the need for expensive lookup mechanisms or other explicit codebook storage. Lattice approaches address this through highly structured and dense packing. This paper explores the Leech lattice, which, with its optimal sphere packing and kissing configurations at 24 dimensions, is the highest dimensional lattice known with such optimal properties. To make the Leech lattice usable for LLM quantization, we extend an existing search algorithm based on the extended Golay code construction, to i) support indexing, enabling conversion to and from bitstrings without materializing the codebook, ii) allow angular search over union of Leech lattice shells, iii) propose fully-parallelisable dequantization kernel. Together this yields a practical algorithm, namely Leech Lattice Vector Quantization (LLVQ). LLVQ delivers state-of-the-art LLM quantization performance, outperforming recent methods such as Quip\#, QTIP, and PVQ. These results highlight the importance of high-dimensional lattices for scalable, theoretically grounded model compression.
Dissecting Quantization Error: A Concentration-Alignment Perspective
Mar 04, 2026Quantization can drastically increase the efficiency of large language and vision models, but typically incurs an accuracy drop. Recently, function-preserving transforms (e.g. rotations, Hadamard transform, channel-wise scaling) have been successfully applied to reduce post-training quantization error, yet a principled explanation remains elusive. We analyze linear-layer quantization via the signal-to-quantization-noise ratio (SQNR), showing that for uniform integer quantization at a fixed bit width, SQNR decomposes into (i) the concentration of weights and activations (capturing spread and outliers), and (ii) the alignment of their dominant variation directions. This reveals an actionable insight: beyond concentration - the focus of most prior transforms (e.g. rotations or Hadamard) - improving alignment between weight and activation can further reduce quantization error. Motivated by this, we introduce block Concentration-Alignment Transforms (CAT), a lightweight linear transformation that uses a covariance estimate from a small calibration set to jointly improve concentration and alignment, approximately maximizing SQNR. Experiments across several LLMs show that CAT consistently matches or outperforms prior transform-based quantization methods at 4-bit precision, confirming the insights gained in our framework.
PipeFlow: Pipelined Processing and Motion-Aware Frame Selection for Long-Form Video Editing
Dec 30, 2025Long-form video editing poses unique challenges due to the exponential increase in the computational cost from joint editing and Denoising Diffusion Implicit Models (DDIM) inversion across extended sequences. To address these limitations, we propose PipeFlow, a scalable, pipelined video editing method that introduces three key innovations: First, based on a motion analysis using Structural Similarity Index Measure (SSIM) and Optical Flow, we identify and propose to skip editing of frames with low motion. Second, we propose a pipelined task scheduling algorithm that splits a video into multiple segments and performs DDIM inversion and joint editing in parallel based on available GPU memory. Lastly, we leverage a neural network-based interpolation technique to smooth out the border frames between segments and interpolate the previously skipped frames. Our method uniquely scales to longer videos by dividing them into smaller segments, allowing PipeFlow's editing time to increase linearly with video length. In principle, this enables editing of infinitely long videos without the growing per-frame computational overhead encountered by other methods. PipeFlow achieves up to a 9.6X speedup compared to TokenFlow and a 31.7X speedup over Diffusion Motion Transfer (DMT).
STaMP: Sequence Transformation and Mixed Precision for Low-Precision Activation Quantization
Oct 30, 2025Quantization is the key method for reducing inference latency, power and memory footprint of generative AI models. However, accuracy often degrades sharply when activations are quantized below eight bits. Recent work suggests that invertible linear transformations (e.g. rotations) can aid quantization, by reparameterizing feature channels and weights. In this paper, we propose \textit{Sequence Transformation and Mixed Precision} (STaMP) quantization, a novel strategy that applies linear transformations along the \textit{sequence} dimension to exploit the strong local correlation in language and visual data. By keeping a small number of tokens in each intermediate activation at higher precision, we can maintain model accuracy at lower (average) activations bit-widths. We evaluate STaMP on recent LVM and LLM architectures, demonstrating that it significantly improves low bit width activation quantization and complements established activation and weight quantization methods including recent feature transformations.
HadaNorm: Diffusion Transformer Quantization through Mean-Centered Transformations
Jun 11, 2025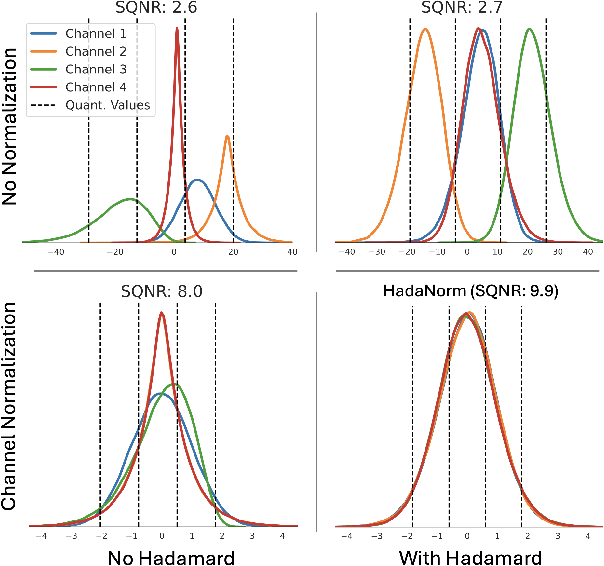
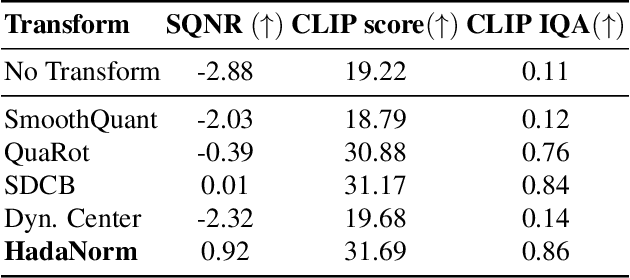
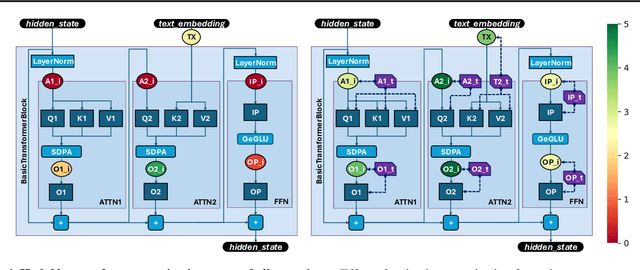
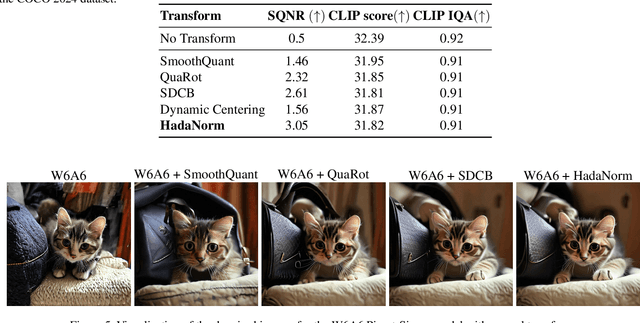
Diffusion models represent the cutting edge in image generation, but their high memory and computational demands hinder deployment on resource-constrained devices. Post-Training Quantization (PTQ) offers a promising solution by reducing the bitwidth of matrix operations. However, standard PTQ methods struggle with outliers, and achieving higher compression often requires transforming model weights and activations before quantization. In this work, we propose HadaNorm, a novel linear transformation that extends existing approaches and effectively mitigates outliers by normalizing activations feature channels before applying Hadamard transformations, enabling more aggressive activation quantization. We demonstrate that HadaNorm consistently reduces quantization error across the various components of transformer blocks, achieving superior efficiency-performance trade-offs when compared to state-of-the-art methods.
FPTQuant: Function-Preserving Transforms for LLM Quantization
Jun 05, 2025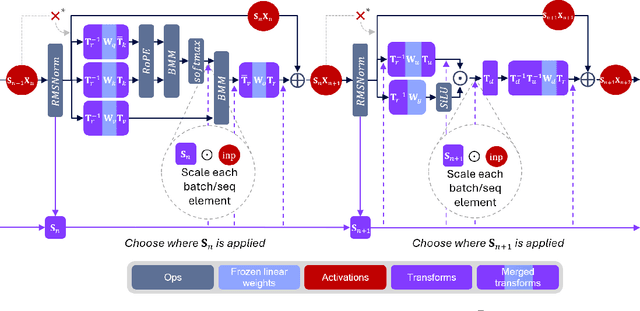
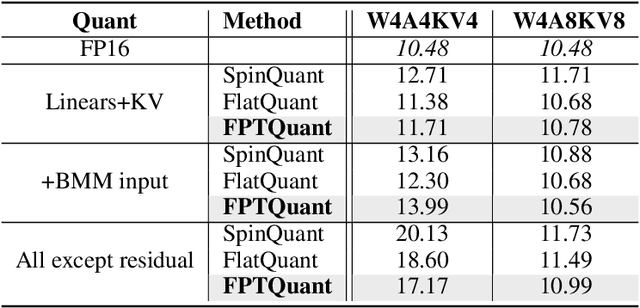
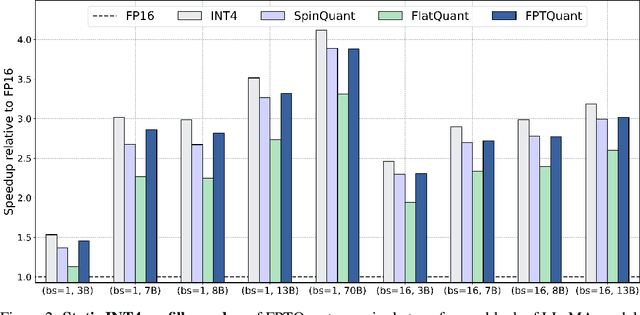
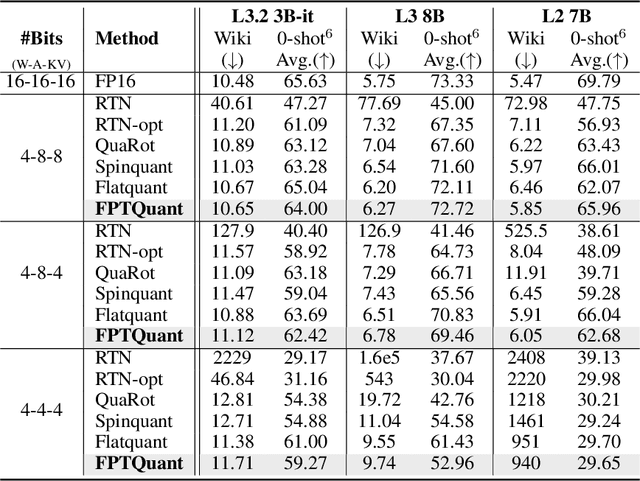
Large language models (LLMs) require substantial compute, and thus energy, at inference time. While quantizing weights and activations is effective at improving efficiency, naive quantization of LLMs can significantly degrade performance due to large magnitude outliers. This paper describes FPTQuant, which introduces four novel, lightweight, and expressive function-preserving transforms (FPTs) to facilitate quantization of transformers: (1) a mergeable pre-RoPE transform for queries and keys, (2) a mergeable transform for values, (3) a mergeable scaling transform within the MLP block, and (4) a cheap, dynamic scaling transform. By leveraging the equivariances and independencies inherent to canonical transformer operation, we designed these FPTs to maintain the model's function while shaping the intermediate activation distributions to be more quantization friendly. FPTQuant requires no custom kernels and adds virtually no overhead during inference. The FPTs are trained both locally to reduce outliers, and end-to-end such that the outputs of the quantized and full-precision models match. FPTQuant enables static INT4 quantization with minimal overhead and shows SOTA speed-up of up to 3.9 times over FP. Empirically, FPTQuant has an excellent accuracy-speed trade-off -- it is performing on par or exceeding most prior work and only shows slightly lower accuracy compared to a method that is up to 29% slower.
Efficient LLM Inference using Dynamic Input Pruning and Cache-Aware Masking
Dec 02, 2024



While mobile devices provide ever more compute power, improvements in DRAM bandwidth are much slower. This is unfortunate for large language model (LLM) token generation, which is heavily memory-bound. Previous work has proposed to leverage natural dynamic activation sparsity in ReLU-activated LLMs to reduce effective DRAM bandwidth per token. However, more recent LLMs use SwiGLU instead of ReLU, which result in little inherent sparsity. While SwiGLU activations can be pruned based on magnitude, the resulting sparsity patterns are difficult to predict, rendering previous approaches ineffective. To circumvent this issue, our work introduces Dynamic Input Pruning (DIP): a predictor-free dynamic sparsification approach, which preserves accuracy with minimal fine-tuning. DIP can further use lightweight LoRA adapters to regain some performance lost during sparsification. Lastly, we describe a novel cache-aware masking strategy, which considers the cache state and activation magnitude to further increase cache hit rate, improving LLM token rate on mobile devices. DIP outperforms other methods in terms of accuracy, memory and throughput trade-offs across simulated hardware settings. On Phi-3-Medium, DIP achieves a 46% reduction in memory and 40% increase in throughput with $<$ 0.1 loss in perplexity.
Mixture of Cache-Conditional Experts for Efficient Mobile Device Inference
Nov 27, 2024



Mixture of Experts (MoE) LLMs have recently gained attention for their ability to enhance performance by selectively engaging specialized subnetworks or "experts" for each input. However, deploying MoEs on memory-constrained devices remains challenging, particularly when generating tokens sequentially with a batch size of one, as opposed to typical high-throughput settings involving long sequences or large batches. In this work, we optimize MoE on memory-constrained devices where only a subset of expert weights fit in DRAM. We introduce a novel cache-aware routing strategy that leverages expert reuse during token generation to improve cache locality. We evaluate our approach on language modeling, MMLU, and GSM8K benchmarks and present on-device results demonstrating 2$\times$ speedups on mobile devices, offering a flexible, training-free solution to extend MoE's applicability across real-world applications.
Rapid Switching and Multi-Adapter Fusion via Sparse High Rank Adapters
Jul 22, 2024


In this paper, we propose Sparse High Rank Adapters (SHiRA) that directly finetune 1-2% of the base model weights while leaving others unchanged, thus, resulting in a highly sparse adapter. This high sparsity incurs no inference overhead, enables rapid switching directly in the fused mode, and significantly reduces concept-loss during multi-adapter fusion. Our extensive experiments on LVMs and LLMs demonstrate that finetuning merely 1-2% parameters in the base model is sufficient for many adapter tasks and significantly outperforms Low Rank Adaptation (LoRA). We also show that SHiRA is orthogonal to advanced LoRA methods such as DoRA and can be easily combined with existing techniques.
Sparse High Rank Adapters
Jun 19, 2024
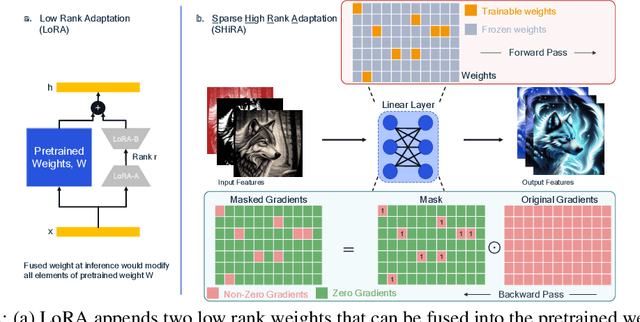
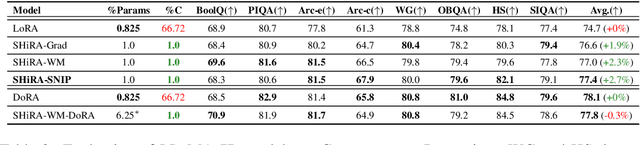
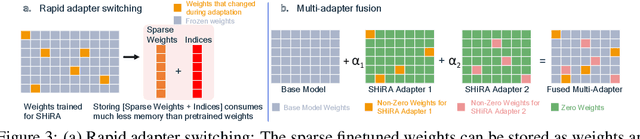
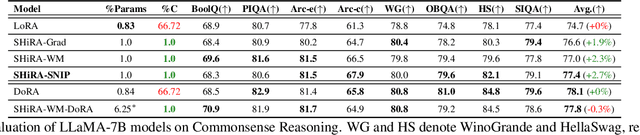
Low Rank Adaptation (LoRA) has gained massive attention in the recent generative AI research. One of the main advantages of LoRA is its ability to be fused with pretrained models adding no overhead during inference. However, from a mobile deployment standpoint, we can either avoid inference overhead in the fused mode but lose the ability to switch adapters rapidly, or suffer significant (up to 30% higher) inference latency while enabling rapid switching in the unfused mode. LoRA also exhibits concept-loss when multiple adapters are used concurrently. In this paper, we propose Sparse High Rank Adapters (SHiRA), a new paradigm which incurs no inference overhead, enables rapid switching, and significantly reduces concept-loss. Specifically, SHiRA can be trained by directly tuning only 1-2% of the base model weights while leaving others unchanged. This results in a highly sparse adapter which can be switched directly in the fused mode. We further provide theoretical and empirical insights on how high sparsity in SHiRA can aid multi-adapter fusion by reducing concept loss. Our extensive experiments on LVMs and LLMs demonstrate that finetuning only a small fraction of the parameters in the base model is sufficient for many tasks while enabling both rapid switching and multi-adapter fusion. Finally, we provide a latency- and memory-efficient SHiRA implementation based on Parameter-Efficient Finetuning (PEFT) Library. This implementation trains at nearly the same speed as LoRA while consuming lower peak GPU memory, thus making SHiRA easy to adopt for practical use cases.