 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTaMP: Sequence Transformation and Mixed Precision for Low-Precision Activation Quantization
Oct 30, 2025Quantization is the key method for reducing inference latency, power and memory footprint of generative AI models. However, accuracy often degrades sharply when activations are quantized below eight bits. Recent work suggests that invertible linear transformations (e.g. rotations) can aid quantization, by reparameterizing feature channels and weights. In this paper, we propose \textit{Sequence Transformation and Mixed Precision} (STaMP) quantization, a novel strategy that applies linear transformations along the \textit{sequence} dimension to exploit the strong local correlation in language and visual data. By keeping a small number of tokens in each intermediate activation at higher precision, we can maintain model accuracy at lower (average) activations bit-widths. We evaluate STaMP on recent LVM and LLM architectures, demonstrating that it significantly improves low bit width activation quantization and complements established activation and weight quantization methods including recent feature transformations.
HadaNorm: Diffusion Transformer Quantization through Mean-Centered Transformations
Jun 11, 2025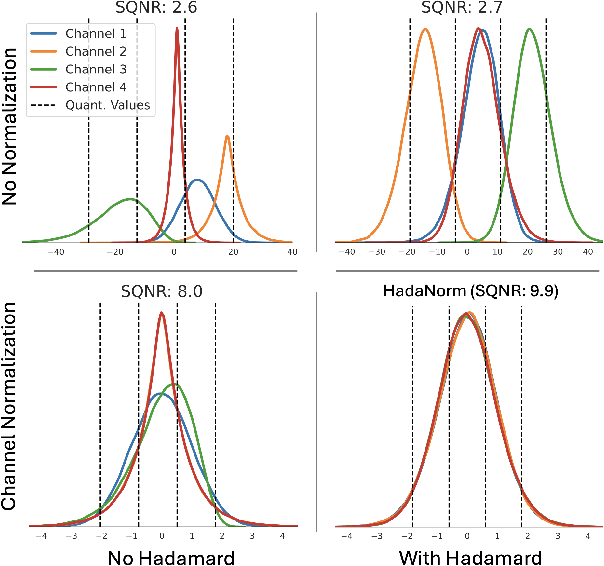
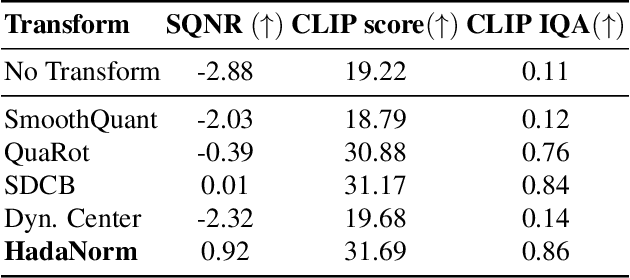
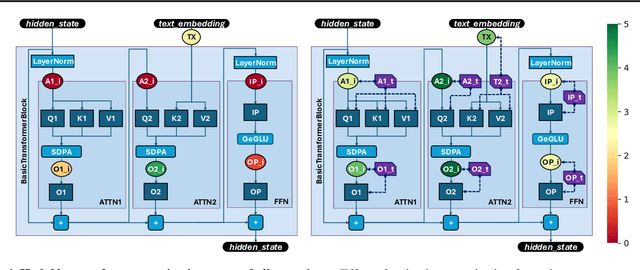
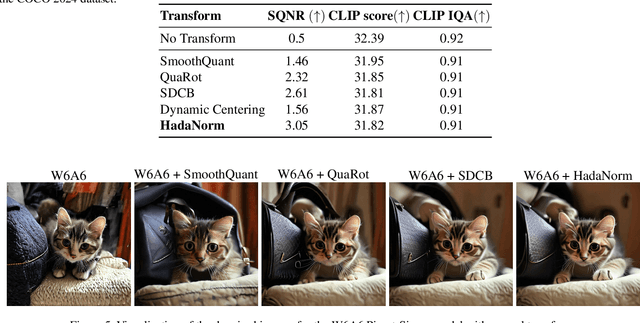
Diffusion models represent the cutting edge in image generation, but their high memory and computational demands hinder deployment on resource-constrained devices. Post-Training Quantization (PTQ) offers a promising solution by reducing the bitwidth of matrix operations. However, standard PTQ methods struggle with outliers, and achieving higher compression often requires transforming model weights and activations before quantization. In this work, we propose HadaNorm, a novel linear transformation that extends existing approaches and effectively mitigates outliers by normalizing activations feature channels before applying Hadamard transformations, enabling more aggressive activation quantization. We demonstrate that HadaNorm consistently reduces quantization error across the various components of transformer blocks, achieving superior efficiency-performance trade-offs when compared to state-of-the-art methods.
Low-Rank Quantization-Aware Training for LLMs
Jun 10, 2024



Large language models (LLMs) are omnipresent, however their practical deployment is challenging due to their ever increasing computational and memory demands. Quantization is one of the most effective ways to make them more compute and memory efficient. Quantization-aware training (QAT) methods, generally produce the best quantized performance, however it comes at the cost of potentially long training time and excessive memory usage, making it impractical when applying for LLMs. Inspired by parameter-efficient fine-tuning (PEFT) and low-rank adaptation (LoRA) literature, we propose LR-QAT -- a lightweight and memory-efficient QAT algorithm for LLMs. LR-QAT employs several components to save memory without sacrificing predictive performance: (a) low-rank auxiliary weights that are aware of the quantization grid; (b) a downcasting operator using fixed-point or double-packed integers and (c) checkpointing. Unlike most related work, our method (i) is inference-efficient, leading to no additional overhead compared to traditional PTQ; (ii) can be seen as a general extended pretraining framework, meaning that the resulting model can still be utilized for any downstream task afterwards; (iii) can be applied across a wide range of quantization settings, such as different choices quantization granularity, activation quantization, and seamlessly combined with many PTQ techniques. We apply LR-QAT to the LLaMA-2/3 and Mistral model families and validate its effectiveness on several downstream tasks. Our method outperforms common post-training quantization (PTQ) approaches and reaches the same model performance as full-model QAT at the fraction of its memory usage. Specifically, we can train a 7B LLM on a single consumer grade GPU with 24GB of memory.
RATT: Recurrent Attention to Transient Tasks for Continual Image Captioning
Jul 13, 2020

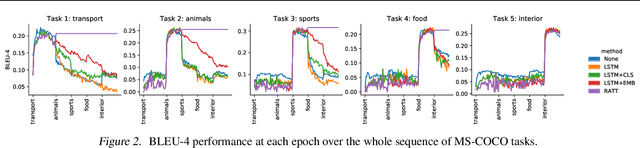
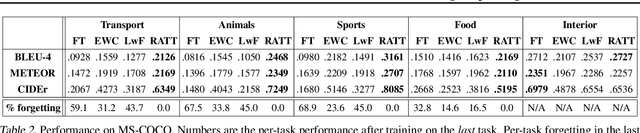
Research on continual learning has led to a variety of approaches to mitigating catastrophic forgetting in feed-forward classification networks. Until now surprisingly little attention has been focused on continual learning of recurrent models applied to problems like image captioning. In this paper we take a systematic look at continual learning of LSTM-based models for image captioning. We propose an attention-based approach that explicitly accommodates the transient nature of vocabularies in continual image captioning tasks -- i.e. that task vocabularies are not disjoint. We call our method Recurrent Attention to Transient Tasks (RATT), and also show how to adapt continual learning approaches based on weight egularization and knowledge distillation to recurrent continual learning problems. We apply our approaches to incremental image captioning problem on two new continual learning benchmarks we define using the MS-COCO and Flickr30 datasets. Our results demonstrate that RATT is able to sequentially learn five captioning tasks while incurring no forgetting of previously learned ones.