 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Tool Dependency Retrieval for Efficient Function Calling
Dec 23, 2025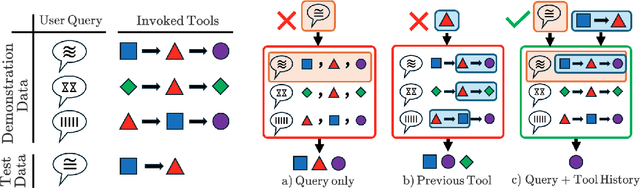

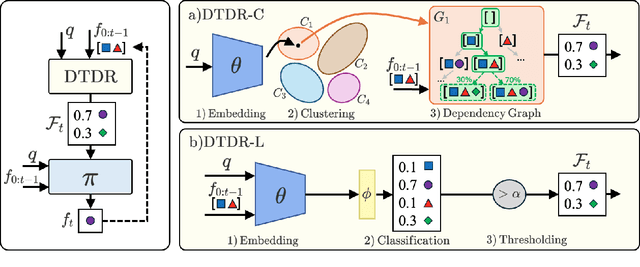
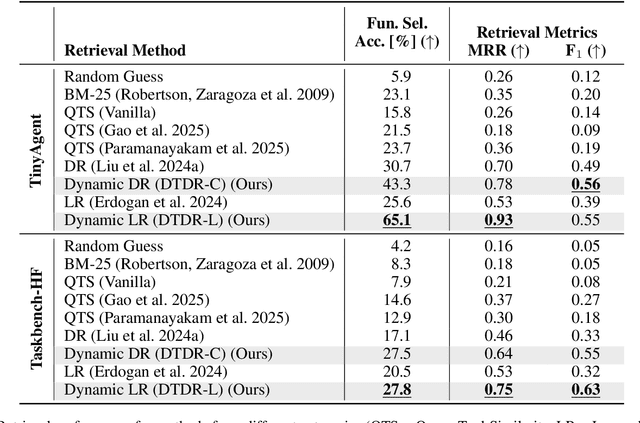
Function calling agents powered by Large Language Models (LLMs) select external tools to automate complex tasks. On-device agents typically use a retrieval module to select relevant tools, improving performance and reducing context length. However, existing retrieval methods rely on static and limited inputs, failing to capture multi-step tool dependencies and evolving task context. This limitation often introduces irrelevant tools that mislead the agent, degrading efficiency and accuracy. We propose Dynamic Tool Dependency Retrieval (DTDR), a lightweight retrieval method that conditions on both the initial query and the evolving execution context. DTDR models tool dependencies from function calling demonstrations, enabling adaptive retrieval as plans unfold. We benchmark DTDR against state-of-the-art retrieval methods across multiple datasets and LLM backbones, evaluating retrieval precision, downstream task accuracy, and computational efficiency. Additionally, we explore strategies to integrate retrieved tools into prompts. Our results show that dynamic tool retrieval improves function calling success rates between $23\%$ and $104\%$ compared to state-of-the-art static retrievers.
Efficient LLM Inference using Dynamic Input Pruning and Cache-Aware Masking
Dec 02, 2024



While mobile devices provide ever more compute power, improvements in DRAM bandwidth are much slower. This is unfortunate for large language model (LLM) token generation, which is heavily memory-bound. Previous work has proposed to leverage natural dynamic activation sparsity in ReLU-activated LLMs to reduce effective DRAM bandwidth per token. However, more recent LLMs use SwiGLU instead of ReLU, which result in little inherent sparsity. While SwiGLU activations can be pruned based on magnitude, the resulting sparsity patterns are difficult to predict, rendering previous approaches ineffective. To circumvent this issue, our work introduces Dynamic Input Pruning (DIP): a predictor-free dynamic sparsification approach, which preserves accuracy with minimal fine-tuning. DIP can further use lightweight LoRA adapters to regain some performance lost during sparsification. Lastly, we describe a novel cache-aware masking strategy, which considers the cache state and activation magnitude to further increase cache hit rate, improving LLM token rate on mobile devices. DIP outperforms other methods in terms of accuracy, memory and throughput trade-offs across simulated hardware settings. On Phi-3-Medium, DIP achieves a 46% reduction in memory and 40% increase in throughput with $<$ 0.1 loss in perplexity.
GNSS Positioning using Cost Function Regulated Multilateration and Graph Neural Networks
Feb 28, 2024



In urban environments, where line-of-sight signals from GNSS satellites are frequently blocked by high-rise objects, GNSS receivers are subject to large errors in measuring satellite ranges. Heuristic methods are commonly used to estimate these errors and reduce the impact of noisy measurements on localization accuracy. In our work, we replace these error estimation heuristics with a deep learning model based on Graph Neural Networks. Additionally, by analyzing the cost function of the multilateration process, we derive an optimal method to utilize the estimated errors. Our approach guarantees that the multilateration converges to the receiver's location as the error estimation accuracy increases. We evaluate our solution on a real-world dataset containing more than 100k GNSS epochs, collected from multiple cities with diverse characteristics. The empirical results show improvements from 40% to 80% in the horizontal localization error against recent deep learning baselines as well as classical localization approaches.
Image-Conditioned Graph Generation for Road Network Extraction
Oct 31, 2019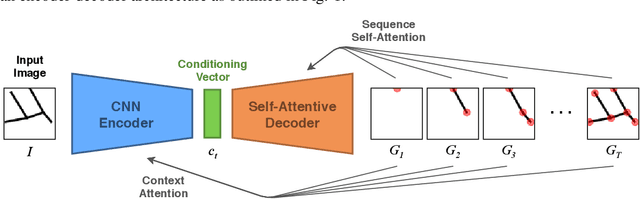

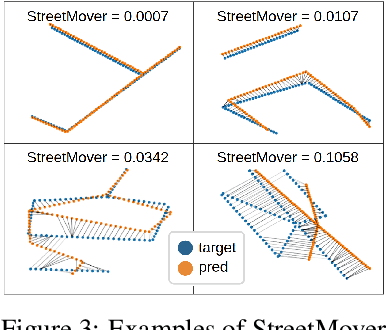

Deep generative models for graphs have shown great promise in the area of drug design, but have so far found little application beyond generating graph-structured molecules. In this work, we demonstrate a proof of concept for the challenging task of road network extraction from image data. This task can be framed as image-conditioned graph generation, for which we develop the Generative Graph Transformer (GGT), a deep autoregressive model that makes use of attention mechanisms for image conditioning and the recurrent generation of graphs. We benchmark GGT on the application of road network extraction from semantic segmentation data. For this, we introduce the Toulouse Road Network dataset, based on real-world publicly-available data. We further propose the StreetMover distance: a metric based on the Sinkhorn distance for effectively evaluating the quality of road network generation. The code and dataset are publicly available.
Chest X-Rays Image Inpainting with Context Encoders
Dec 03, 2018


Chest X-rays are one of the most commonly used technologies for medical diagnosis. Many deep learning models have been proposed to improve and automate the abnormality detection task on this type of data. In this paper, we propose a different approach based on image inpainting under adversarial training first introduced by Goodfellow et al. We configure the context encoder model for this task and train it over 1.1M 128x128 images from healthy X-rays. The goal of our model is to reconstruct the missing central 64x64 patch. Once the model has learned how to inpaint healthy tissue, we test its performance on images with and without abnormalities. We discuss and motivate our results considering PSNR, MSE and SSIM scores as evaluation metrics. In addition, we conduct a 2AFC observer study showing that in half of the times an expert is unable to distinguish real images from the ones reconstructed using our model. By computing and visualizing the pixel-wise difference between source and reconstructed images, we can highlight abnormalities to simplify further detection and classification tasks.
Chest X-ray Inpainting with Deep Generative Models
Aug 29, 2018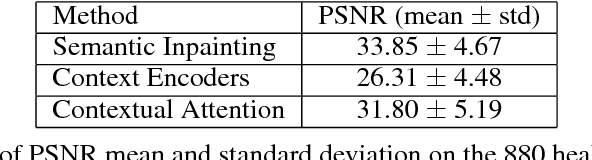
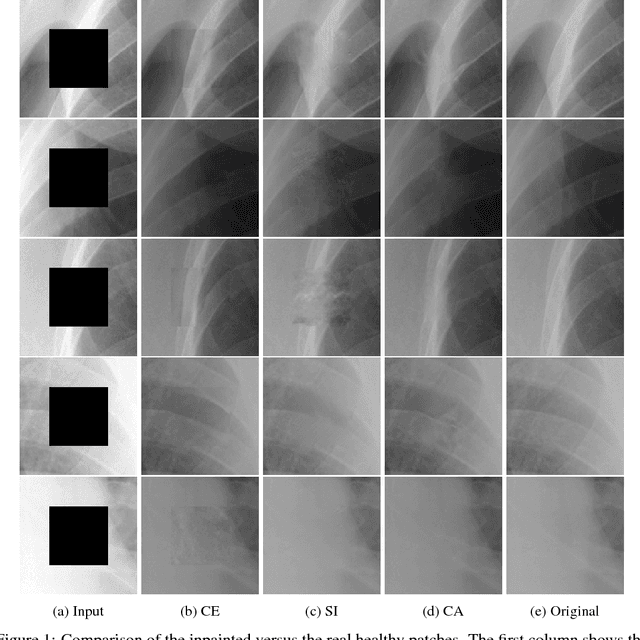
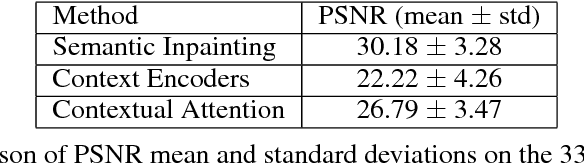

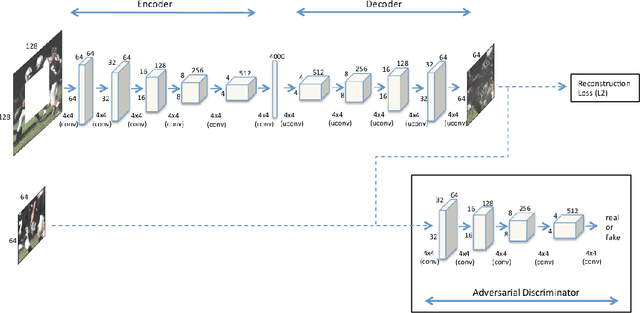
Generative adversarial networks have been successfully applied to inpainting in natural images. However, the current state-of-the-art models have not yet been widely adopted in the medical imaging domain. In this paper, we investigate the performance of three recently published deep learning based inpainting models: context encoders, semantic image inpainting, and the contextual attention model, applied to chest x-rays, as the chest exam is the most commonly performed radiological procedure. We train these generative models on 1.2M 128 $\times$ 128 patches from 60K healthy x-rays, and learn to predict the center 64 $\times$ 64 region in each patch. We test the models on both the healthy and abnormal radiographs. We evaluate the results by visual inspection and comparing the PSNR scores. The outputs of the models are in most cases highly realistic. We show that the methods have potential to enhance and detect abnormalities. In addition, we perform a 2AFC observer study and show that an experienced human observer performs poorly in detecting inpainted regions, particularly those generated by the contextual attention model.