 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFalcon-H1R: Pushing the Reasoning Frontiers with a Hybrid Model for Efficient Test-Time Scaling
Jan 05, 2026This work introduces Falcon-H1R, a 7B-parameter reasoning-optimized model that establishes the feasibility of achieving competitive reasoning performance with small language models (SLMs). Falcon-H1R stands out for its parameter efficiency, consistently matching or outperforming SOTA reasoning models that are $2\times$ to $7\times$ larger across a variety of reasoning-intensive benchmarks. These results underscore the importance of careful data curation and targeted training strategies (via both efficient SFT and RL scaling) in delivering significant performance gains without increasing model size. Furthermore, Falcon-H1R advances the 3D limits of reasoning efficiency by combining faster inference (through its hybrid-parallel architecture design), token efficiency, and higher accuracy. This unique blend makes Falcon-H1R-7B a practical backbone for scaling advanced reasoning systems, particularly in scenarios requiring extensive chain-of-thoughts generation and parallel test-time scaling. Leveraging the recently introduced DeepConf approach, Falcon-H1R achieves state-of-the-art test-time scaling efficiency, offering substantial improvements in both accuracy and computational cost. As a result, Falcon-H1R demonstrates that compact models, through targeted model training and architectural choices, can deliver robust and scalable reasoning performance.
Falcon-H1: A Family of Hybrid-Head Language Models Redefining Efficiency and Performance
Jul 30, 2025In this report, we introduce Falcon-H1, a new series of large language models (LLMs) featuring hybrid architecture designs optimized for both high performance and efficiency across diverse use cases. Unlike earlier Falcon models built solely on Transformer or Mamba architectures, Falcon-H1 adopts a parallel hybrid approach that combines Transformer-based attention with State Space Models (SSMs), known for superior long-context memory and computational efficiency. We systematically revisited model design, data strategy, and training dynamics, challenging conventional practices in the field. Falcon-H1 is released in multiple configurations, including base and instruction-tuned variants at 0.5B, 1.5B, 1.5B-deep, 3B, 7B, and 34B parameters. Quantized instruction-tuned models are also available, totaling over 30 checkpoints on Hugging Face Hub. Falcon-H1 models demonstrate state-of-the-art performance and exceptional parameter and training efficiency. The flagship Falcon-H1-34B matches or outperforms models up to 70B scale, such as Qwen3-32B, Qwen2.5-72B, and Llama3.3-70B, while using fewer parameters and less data. Smaller models show similar trends: the Falcon-H1-1.5B-Deep rivals current leading 7B-10B models, and Falcon-H1-0.5B performs comparably to typical 7B models from 2024. These models excel across reasoning, mathematics, multilingual tasks, instruction following, and scientific knowledge. With support for up to 256K context tokens and 18 languages, Falcon-H1 is suitable for a wide range of applications. All models are released under a permissive open-source license, underscoring our commitment to accessible and impactful AI research.
Adversarial Defense via Image Denoising with Chaotic Encryption
Mar 19, 2022

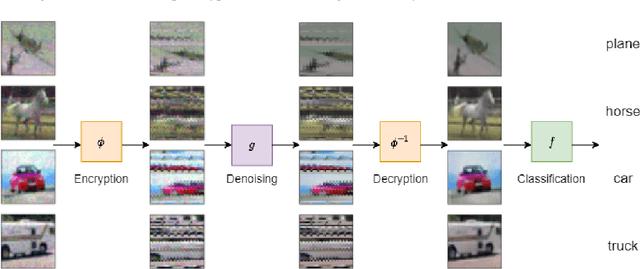

In the literature on adversarial examples, white box and black box attacks have received the most attention. The adversary is assumed to have either full (white) or no (black) access to the defender's model. In this work, we focus on the equally practical gray box setting, assuming an attacker has partial information. We propose a novel defense that assumes everything but a private key will be made available to the attacker. Our framework uses an image denoising procedure coupled with encryption via a discretized Baker map. Extensive testing against adversarial images (e.g. FGSM, PGD) crafted using various gradients shows that our defense achieves significantly better results on CIFAR-10 and CIFAR-100 than the state-of-the-art gray box defenses in both natural and adversarial accuracy.
Simple and Accurate Uncertainty Quantification from Bias-Variance Decomposition
Feb 13, 2020
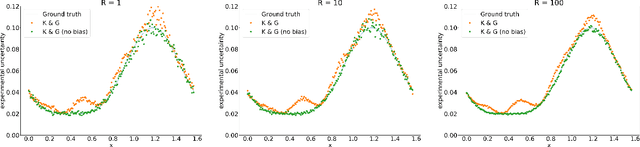
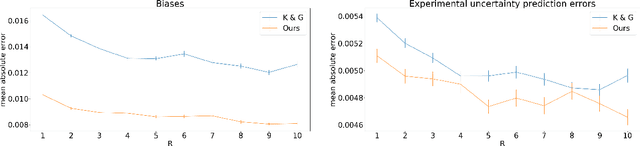
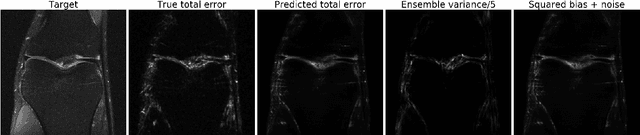
Accurate uncertainty quantification is crucial for many applications where decisions are in play. Examples include medical diagnosis and self-driving vehicles. We propose a new method that is based directly on the bias-variance decomposition, where the parameter uncertainty is given by the variance of an ensemble divided by the number of members in the ensemble, and the aleatoric uncertainty plus the squared bias is estimated by training a separate model that is regressed directly on the errors of the predictor. We demonstrate that this simple sequential procedure provides much more accurate uncertainty estimates than the current state-of-the-art on two MRI reconstruction tasks.
Supervised Uncertainty Quantification for Segmentation with Multiple Annotations
Jul 03, 2019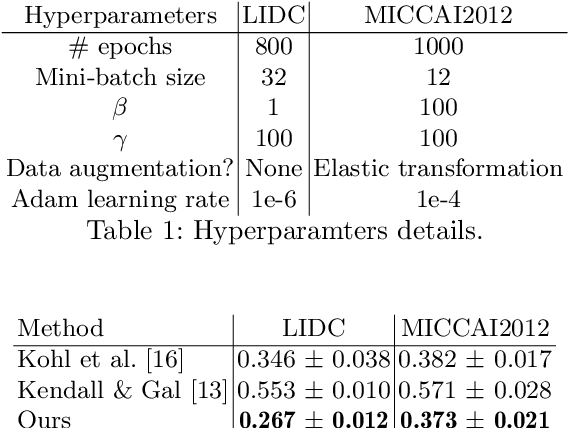

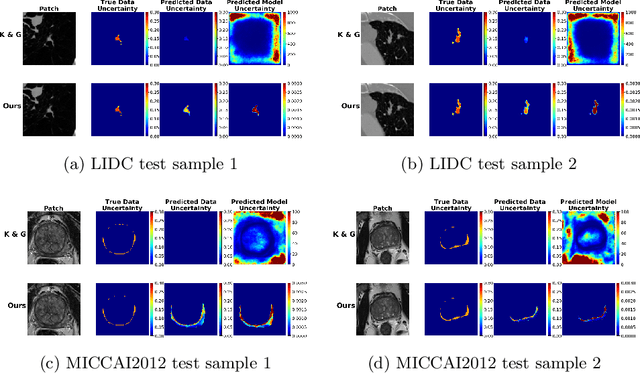
The accurate estimation of predictive uncertainty carries importance in medical scenarios such as lung node segmentation. Unfortunately, most existing works on predictive uncertainty do not return calibrated uncertainty estimates, which could be used in practice. In this work we exploit multi-grader annotation variability as a source of 'groundtruth' aleatoric uncertainty, which can be treated as a target in a supervised learning problem. We combine this groundtruth uncertainty with a Probabilistic U-Net and test on the LIDC-IDRI lung nodule CT dataset and MICCAI2012 prostate MRI dataset. We find that we are able to improve predictive uncertainty estimates. We also find that we can improve sample accuracy and sample diversity.
Chest X-Rays Image Inpainting with Context Encoders
Dec 03, 2018

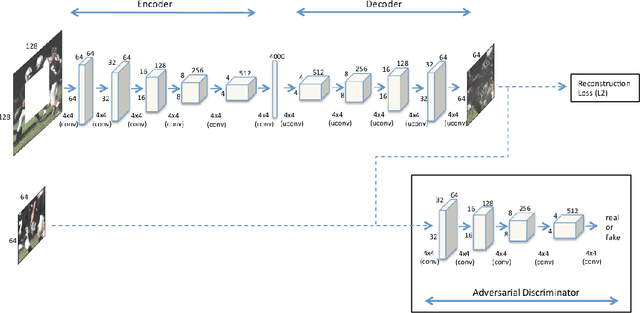

Chest X-rays are one of the most commonly used technologies for medical diagnosis. Many deep learning models have been proposed to improve and automate the abnormality detection task on this type of data. In this paper, we propose a different approach based on image inpainting under adversarial training first introduced by Goodfellow et al. We configure the context encoder model for this task and train it over 1.1M 128x128 images from healthy X-rays. The goal of our model is to reconstruct the missing central 64x64 patch. Once the model has learned how to inpaint healthy tissue, we test its performance on images with and without abnormalities. We discuss and motivate our results considering PSNR, MSE and SSIM scores as evaluation metrics. In addition, we conduct a 2AFC observer study showing that in half of the times an expert is unable to distinguish real images from the ones reconstructed using our model. By computing and visualizing the pixel-wise difference between source and reconstructed images, we can highlight abnormalities to simplify further detection and classification tasks.
Chest X-ray Inpainting with Deep Generative Models
Aug 29, 2018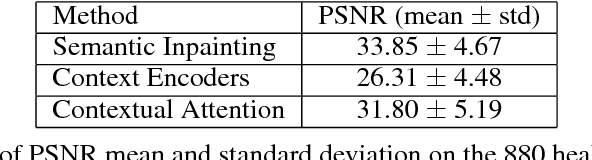
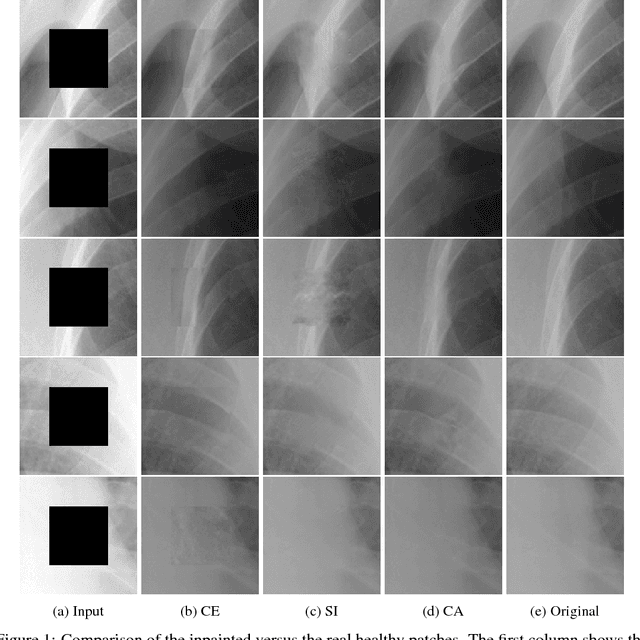
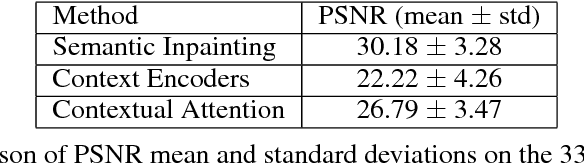

Generative adversarial networks have been successfully applied to inpainting in natural images. However, the current state-of-the-art models have not yet been widely adopted in the medical imaging domain. In this paper, we investigate the performance of three recently published deep learning based inpainting models: context encoders, semantic image inpainting, and the contextual attention model, applied to chest x-rays, as the chest exam is the most commonly performed radiological procedure. We train these generative models on 1.2M 128 $\times$ 128 patches from 60K healthy x-rays, and learn to predict the center 64 $\times$ 64 region in each patch. We test the models on both the healthy and abnormal radiographs. We evaluate the results by visual inspection and comparing the PSNR scores. The outputs of the models are in most cases highly realistic. We show that the methods have potential to enhance and detect abnormalities. In addition, we perform a 2AFC observer study and show that an experienced human observer performs poorly in detecting inpainted regions, particularly those generated by the contextual attention model.