 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Quantization Error: A Concentration-Alignment Perspective
Mar 04, 2026Quantization can drastically increase the efficiency of large language and vision models, but typically incurs an accuracy drop. Recently, function-preserving transforms (e.g. rotations, Hadamard transform, channel-wise scaling) have been successfully applied to reduce post-training quantization error, yet a principled explanation remains elusive. We analyze linear-layer quantization via the signal-to-quantization-noise ratio (SQNR), showing that for uniform integer quantization at a fixed bit width, SQNR decomposes into (i) the concentration of weights and activations (capturing spread and outliers), and (ii) the alignment of their dominant variation directions. This reveals an actionable insight: beyond concentration - the focus of most prior transforms (e.g. rotations or Hadamard) - improving alignment between weight and activation can further reduce quantization error. Motivated by this, we introduce block Concentration-Alignment Transforms (CAT), a lightweight linear transformation that uses a covariance estimate from a small calibration set to jointly improve concentration and alignment, approximately maximizing SQNR. Experiments across several LLMs show that CAT consistently matches or outperforms prior transform-based quantization methods at 4-bit precision, confirming the insights gained in our framework.
STaMP: Sequence Transformation and Mixed Precision for Low-Precision Activation Quantization
Oct 30, 2025Quantization is the key method for reducing inference latency, power and memory footprint of generative AI models. However, accuracy often degrades sharply when activations are quantized below eight bits. Recent work suggests that invertible linear transformations (e.g. rotations) can aid quantization, by reparameterizing feature channels and weights. In this paper, we propose \textit{Sequence Transformation and Mixed Precision} (STaMP) quantization, a novel strategy that applies linear transformations along the \textit{sequence} dimension to exploit the strong local correlation in language and visual data. By keeping a small number of tokens in each intermediate activation at higher precision, we can maintain model accuracy at lower (average) activations bit-widths. We evaluate STaMP on recent LVM and LLM architectures, demonstrating that it significantly improves low bit width activation quantization and complements established activation and weight quantization methods including recent feature transformations.
HadaNorm: Diffusion Transformer Quantization through Mean-Centered Transformations
Jun 11, 2025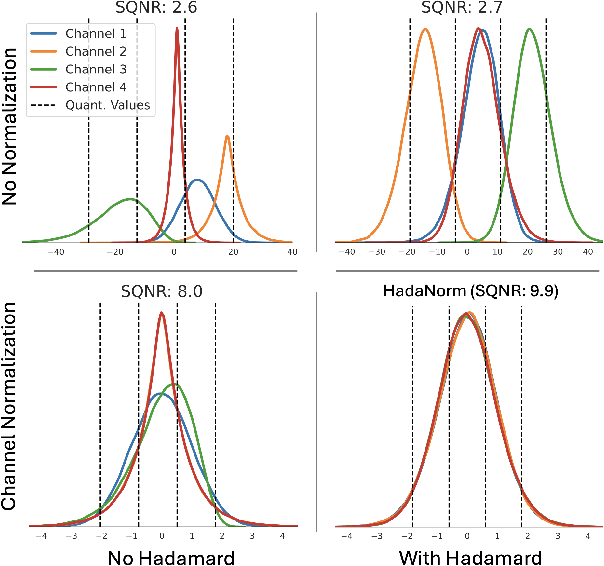
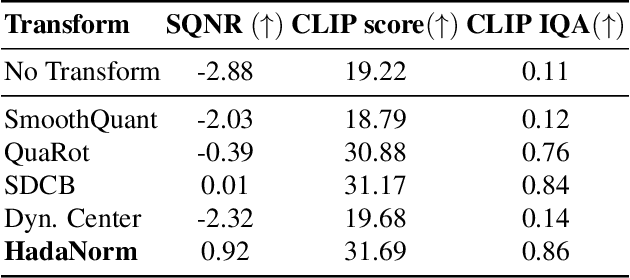
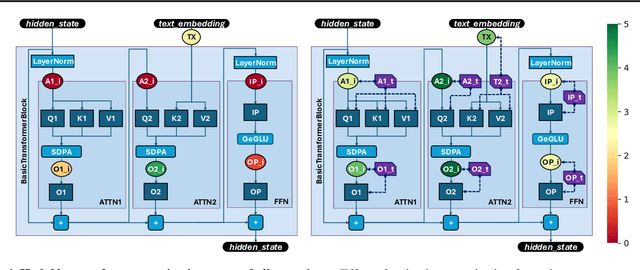
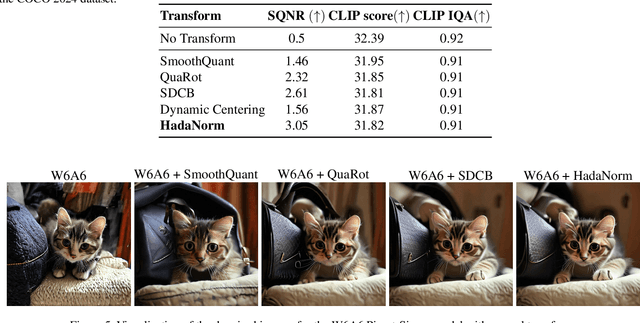
Diffusion models represent the cutting edge in image generation, but their high memory and computational demands hinder deployment on resource-constrained devices. Post-Training Quantization (PTQ) offers a promising solution by reducing the bitwidth of matrix operations. However, standard PTQ methods struggle with outliers, and achieving higher compression often requires transforming model weights and activations before quantization. In this work, we propose HadaNorm, a novel linear transformation that extends existing approaches and effectively mitigates outliers by normalizing activations feature channels before applying Hadamard transformations, enabling more aggressive activation quantization. We demonstrate that HadaNorm consistently reduces quantization error across the various components of transformer blocks, achieving superior efficiency-performance trade-offs when compared to state-of-the-art methods.
Bridge the Inference Gaps of Neural Processes via Expectation Maximization
Jan 04, 2025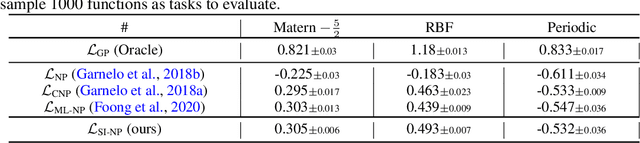
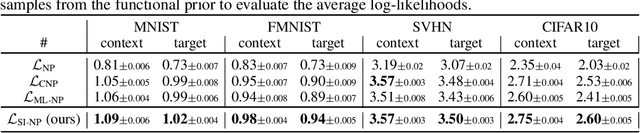

The neural process (NP) is a family of computationally efficient models for learning distributions over functions. However, it suffers from under-fitting and shows suboptimal performance in practice. Researchers have primarily focused on incorporating diverse structural inductive biases, \textit{e.g.} attention or convolution, in modeling. The topic of inference suboptimality and an analysis of the NP from the optimization objective perspective has hardly been studied in earlier work. To fix this issue, we propose a surrogate objective of the target log-likelihood of the meta dataset within the expectation maximization framework. The resulting model, referred to as the Self-normalized Importance weighted Neural Process (SI-NP), can learn a more accurate functional prior and has an improvement guarantee concerning the target log-likelihood. Experimental results show the competitive performance of SI-NP over other NPs objectives and illustrate that structural inductive biases, such as attention modules, can also augment our method to achieve SOTA performance. Our code is available at \url{https://github.com/hhq123gogogo/SI_NPs}.
Efficient LLM Inference using Dynamic Input Pruning and Cache-Aware Masking
Dec 02, 2024



While mobile devices provide ever more compute power, improvements in DRAM bandwidth are much slower. This is unfortunate for large language model (LLM) token generation, which is heavily memory-bound. Previous work has proposed to leverage natural dynamic activation sparsity in ReLU-activated LLMs to reduce effective DRAM bandwidth per token. However, more recent LLMs use SwiGLU instead of ReLU, which result in little inherent sparsity. While SwiGLU activations can be pruned based on magnitude, the resulting sparsity patterns are difficult to predict, rendering previous approaches ineffective. To circumvent this issue, our work introduces Dynamic Input Pruning (DIP): a predictor-free dynamic sparsification approach, which preserves accuracy with minimal fine-tuning. DIP can further use lightweight LoRA adapters to regain some performance lost during sparsification. Lastly, we describe a novel cache-aware masking strategy, which considers the cache state and activation magnitude to further increase cache hit rate, improving LLM token rate on mobile devices. DIP outperforms other methods in terms of accuracy, memory and throughput trade-offs across simulated hardware settings. On Phi-3-Medium, DIP achieves a 46% reduction in memory and 40% increase in throughput with $<$ 0.1 loss in perplexity.
Simulation-based Inference with the Generalized Kullback-Leibler Divergence
Oct 03, 2023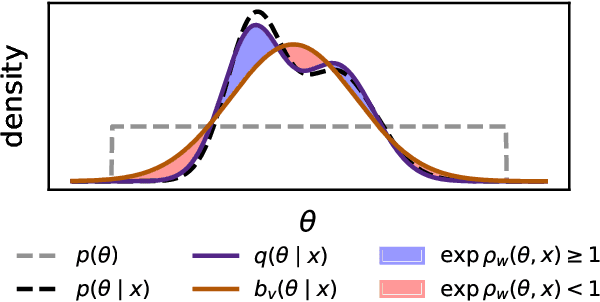
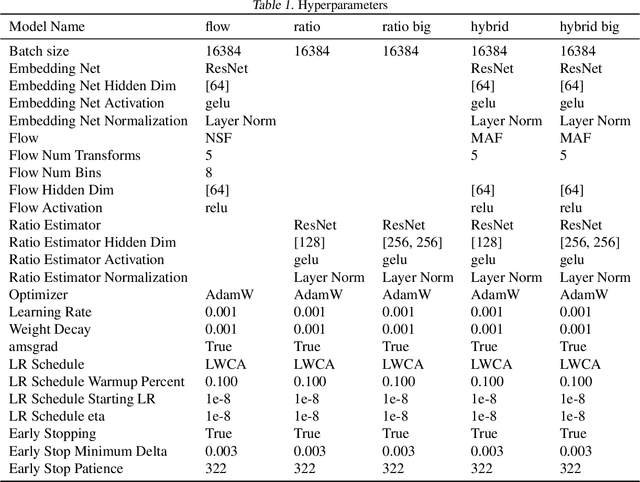
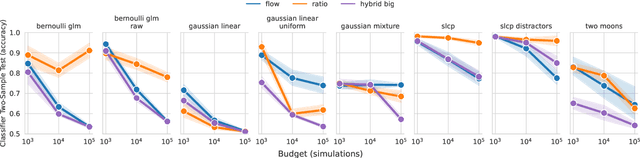
In Simulation-based Inference, the goal is to solve the inverse problem when the likelihood is only known implicitly. Neural Posterior Estimation commonly fits a normalized density estimator as a surrogate model for the posterior. This formulation cannot easily fit unnormalized surrogates because it optimizes the Kullback-Leibler divergence. We propose to optimize a generalized Kullback-Leibler divergence that accounts for the normalization constant in unnormalized distributions. The objective recovers Neural Posterior Estimation when the model class is normalized and unifies it with Neural Ratio Estimation, combining both into a single objective. We investigate a hybrid model that offers the best of both worlds by learning a normalized base distribution and a learned ratio. We also present benchmark results.
Latent Representation and Simulation of Markov Processes via Time-Lagged Information Bottleneck
Sep 13, 2023



Markov processes are widely used mathematical models for describing dynamic systems in various fields. However, accurately simulating large-scale systems at long time scales is computationally expensive due to the short time steps required for accurate integration. In this paper, we introduce an inference process that maps complex systems into a simplified representational space and models large jumps in time. To achieve this, we propose Time-lagged Information Bottleneck (T-IB), a principled objective rooted in information theory, which aims to capture relevant temporal features while discarding high-frequency information to simplify the simulation task and minimize the inference error. Our experiments demonstrate that T-IB learns information-optimal representations for accurately modeling the statistical properties and dynamics of the original process at a selected time lag, outperforming existing time-lagged dimensionality reduction methods.
On the Effectiveness of Hybrid Mutual Information Estimation
Jun 02, 2023Estimating the mutual information from samples from a joint distribution is a challenging problem in both science and engineering. In this work, we realize a variational bound that generalizes both discriminative and generative approaches. Using this bound, we propose a hybrid method to mitigate their respective shortcomings. Further, we propose Predictive Quantization (PQ): a simple generative method that can be easily combined with discriminative estimators for minimal computational overhead. Our propositions yield a tighter bound on the information thanks to the reduced variance of the estimator. We test our methods on a challenging task of correlated high-dimensional Gaussian distributions and a stochastic process involving a system of free particles subjected to a fixed energy landscape. Empirical results show that hybrid methods consistently improved mutual information estimates when compared to the corresponding discriminative counterpart.
Two for One: Diffusion Models and Force Fields for Coarse-Grained Molecular Dynamics
Feb 01, 2023Coarse-grained (CG) molecular dynamics enables the study of biological processes at temporal and spatial scales that would be intractable at an atomistic resolution. However, accurately learning a CG force field remains a challenge. In this work, we leverage connections between score-based generative models, force fields and molecular dynamics to learn a CG force field without requiring any force inputs during training. Specifically, we train a diffusion generative model on protein structures from molecular dynamics simulations, and we show that its score function approximates a force field that can directly be used to simulate CG molecular dynamics. While having a vastly simplified training setup compared to previous work, we demonstrate that our approach leads to improved performance across several small- to medium-sized protein simulations, reproducing the CG equilibrium distribution, and preserving dynamics of all-atom simulations such as protein folding events.
Compositional Mixture Representations for Vision and Text
Jun 13, 2022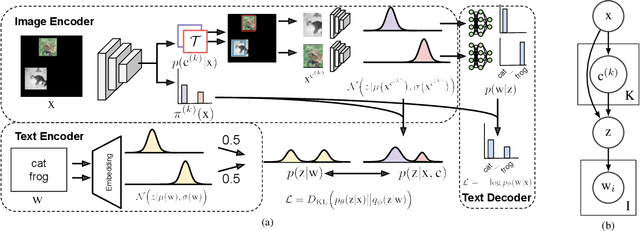
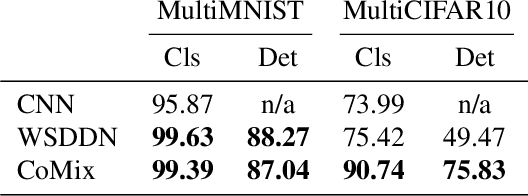

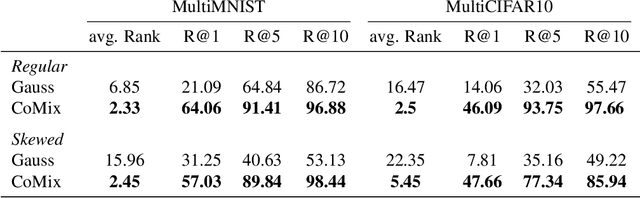
Learning a common representation space between vision and language allows deep networks to relate objects in the image to the corresponding semantic meaning. We present a model that learns a shared Gaussian mixture representation imposing the compositionality of the text onto the visual domain without having explicit location supervision. By combining the spatial transformer with a representation learning approach we learn to split images into separately encoded patches to associate visual and textual representations in an interpretable manner. On variations of MNIST and CIFAR10, our model is able to perform weakly supervised object detection and demonstrates its ability to extrapolate to unseen combination of objects.