Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian Approach to Invariant Deep Neural Networks
Jul 20, 2021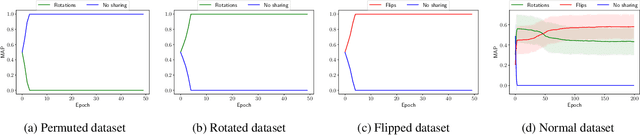
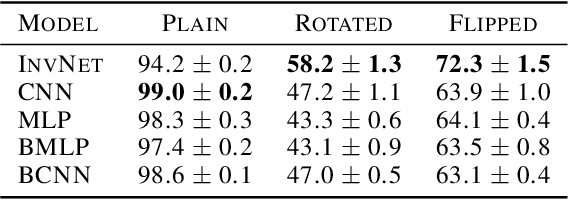
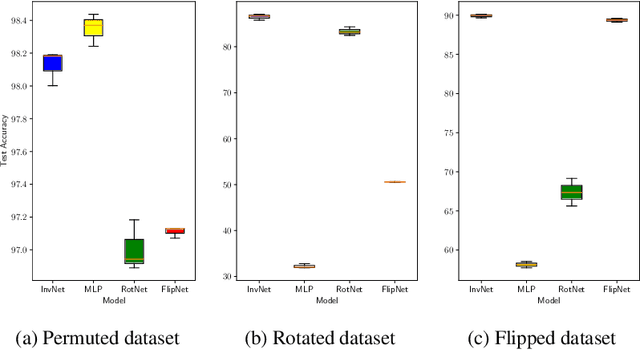
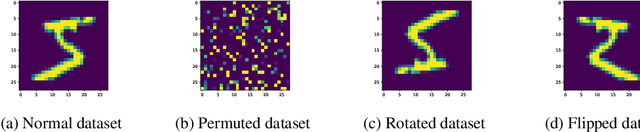
We propose a novel Bayesian neural network architecture that can learn invariances from data alone by inferring a posterior distribution over different weight-sharing schemes. We show that our model outperforms other non-invariant architectures, when trained on datasets that contain specific invariances. The same holds true when no data augmentation is performed.
* 8 pages, 3 figures, To be published in ICML UDL 2021
Via