 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Buzz: A Pragmatic Take on Inference Disaggregation
Jun 05, 2025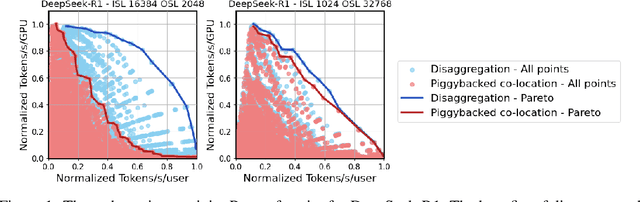

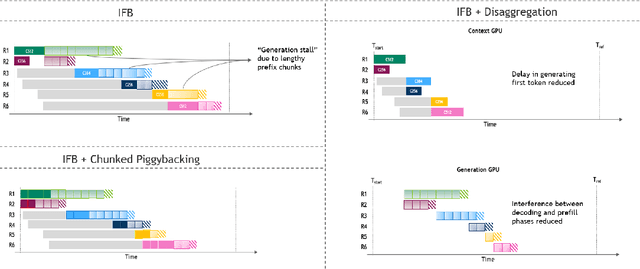
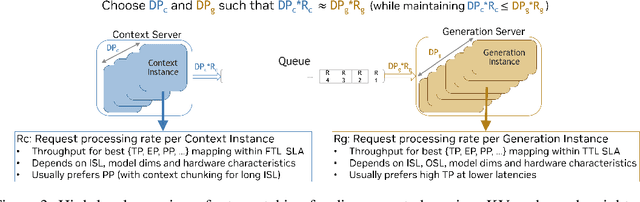
As inference scales to multi-node deployments, disaggregation - splitting inference into distinct phases - offers a promising path to improving the throughput-interactivity Pareto frontier. Despite growing enthusiasm and a surge of open-source efforts, practical deployment of disaggregated serving remains limited due to the complexity of the optimization search space and system-level coordination. In this paper, we present the first systematic study of disaggregated inference at scale, evaluating hundreds of thousands of design points across diverse workloads and hardware configurations. We find that disaggregation is most effective for prefill-heavy traffic patterns and larger models. Our results highlight the critical role of dynamic rate matching and elastic scaling in achieving Pareto-optimal performance. Our findings offer actionable insights for efficient disaggregated deployments to navigate the trade-off between system throughput and interactivity.
PerfSAGE: Generalized Inference Performance Predictor for Arbitrary Deep Learning Models on Edge Devices
Jan 26, 2023The ability to accurately predict deep neural network (DNN) inference performance metrics, such as latency, power, and memory footprint, for an arbitrary DNN on a target hardware platform is essential to the design of DNN based models. This ability is critical for the (manual or automatic) design, optimization, and deployment of practical DNNs for a specific hardware deployment platform. Unfortunately, these metrics are slow to evaluate using simulators (where available) and typically require measurement on the target hardware. This work describes PerfSAGE, a novel graph neural network (GNN) that predicts inference latency, energy, and memory footprint on an arbitrary DNN TFlite graph (TFL, 2017). In contrast, previously published performance predictors can only predict latency and are restricted to pre-defined construction rules or search spaces. This paper also describes the EdgeDLPerf dataset of 134,912 DNNs randomly sampled from four task search spaces and annotated with inference performance metrics from three edge hardware platforms. Using this dataset, we train PerfSAGE and provide experimental results that demonstrate state-of-the-art prediction accuracy with a Mean Absolute Percentage Error of <5% across all targets and model search spaces. These results: (1) Outperform previous state-of-art GNN-based predictors (Dudziak et al., 2020), (2) Accurately predict performance on accelerators (a shortfall of non-GNN-based predictors (Zhang et al., 2021)), and (3) Demonstrate predictions on arbitrary input graphs without modifications to the feature extractor.
UDC: Unified DNAS for Compressible TinyML Models
Jan 21, 2022
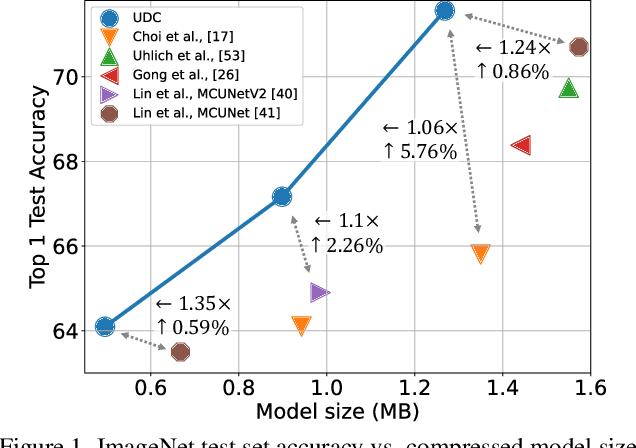
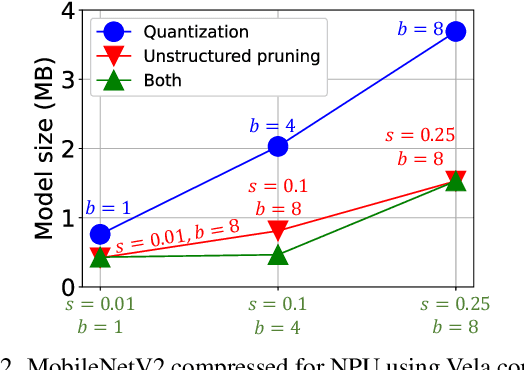
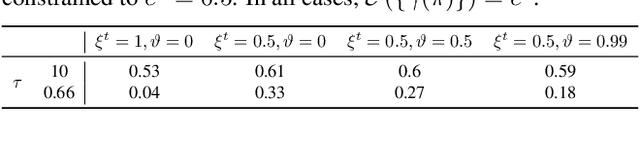
Emerging Internet-of-things (IoT) applications are driving deployment of neural networks (NNs) on heavily constrained low-cost hardware (HW) platforms, where accuracy is typically limited by memory capacity. To address this TinyML challenge, new HW platforms like neural processing units (NPUs) have support for model compression, which exploits aggressive network quantization and unstructured pruning optimizations. The combination of NPUs with HW compression and compressible models allows more expressive models in the same memory footprint. However, adding optimizations for compressibility on top of conventional NN architecture choices expands the design space across which we must make balanced trade-offs. This work bridges the gap between NPU HW capability and NN model design, by proposing a neural architecture search (NAS) algorithm to efficiently search a large design space, including: network depth, operator type, layer width, bitwidth, sparsity, and more. Building on differentiable NAS (DNAS) with several key improvements, we demonstrate Unified DNAS for Compressible models (UDC) on CIFAR100, ImageNet, and DIV2K super resolution tasks. On ImageNet, we find Pareto dominant compressible models, which are 1.9x smaller or 5.76% more accurate.
Collapsible Linear Blocks for Super-Efficient Super Resolution
Mar 17, 2021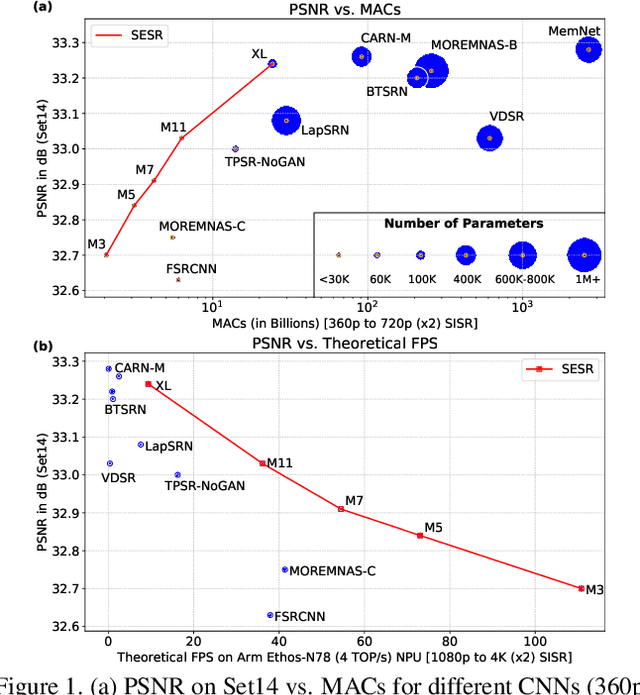
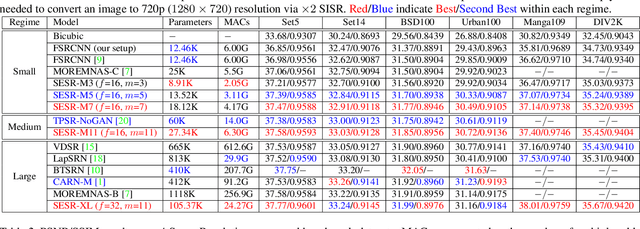
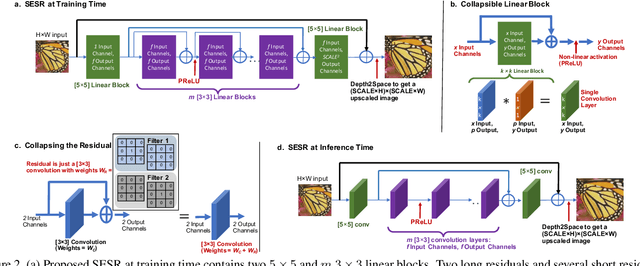
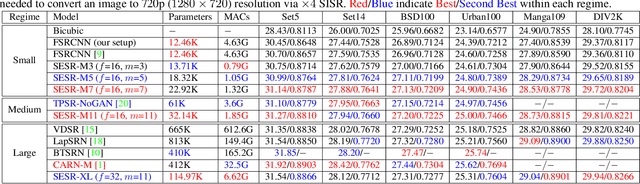
With the advent of smart devices that support 4K and 8K resolution, Single Image Super Resolution (SISR) has become an important computer vision problem. However, most super resolution deep networks are computationally very expensive. In this paper, we propose SESR, a new class of Super-Efficient Super Resolution networks that significantly improve image quality and reduce computational complexity. Detailed experiments across six benchmark datasets demonstrate that SESR achieves similar or better image quality than state-of-the-art models while requiring 2x to 330x fewer Multiply-Accumulate (MAC) operations. As a result, SESR can be used on constrained hardware to perform x2 (1080p to 4K) and x4 SISR (1080p to 8K). Towards this, we simulate hardware performance numbers for a commercial mobile Neural Processing Unit (NPU) for 1080p to 4K (x2) and 1080p to 8K (x4) SISR. Our results highlight the challenges faced by super resolution on AI accelerators and demonstrate that SESR is significantly faster than existing models. Overall, SESR establishes a new Pareto frontier on the quality (PSNR)-computation relationship for the super resolution task.