 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecGuard: Spectral Projection-based Advanced Invisible Watermarking
Oct 08, 2025



Watermarking embeds imperceptible patterns into images for authenticity verification. However, existing methods often lack robustness against various transformations primarily including distortions, image regeneration, and adversarial perturbation, creating real-world challenges. In this work, we introduce SpecGuard, a novel watermarking approach for robust and invisible image watermarking. Unlike prior approaches, we embed the message inside hidden convolution layers by converting from the spatial domain to the frequency domain using spectral projection of a higher frequency band that is decomposed by wavelet projection. Spectral projection employs Fast Fourier Transform approximation to transform spatial data into the frequency domain efficiently. In the encoding phase, a strength factor enhances resilience against diverse attacks, including adversarial, geometric, and regeneration-based distortions, ensuring the preservation of copyrighted information. Meanwhile, the decoder leverages Parseval's theorem to effectively learn and extract the watermark pattern, enabling accurate retrieval under challenging transformations. We evaluate the proposed SpecGuard based on the embedded watermark's invisibility, capacity, and robustness. Comprehensive experiments demonstrate the proposed SpecGuard outperforms the state-of-the-art models. To ensure reproducibility, the full code is released on \href{https://github.com/inzamamulDU/SpecGuard_ICCV_2025}{\textcolor{blue}{\textbf{GitHub}}}.
DIA: The Adversarial Exposure of Deterministic Inversion in Diffusion Models
Oct 01, 2025Diffusion models have shown to be strong representation learners, showcasing state-of-the-art performance across multiple domains. Aside from accelerated sampling, DDIM also enables the inversion of real images back to their latent codes. A direct inheriting application of this inversion operation is real image editing, where the inversion yields latent trajectories to be utilized during the synthesis of the edited image. Unfortunately, this practical tool has enabled malicious users to freely synthesize misinformative or deepfake contents with greater ease, which promotes the spread of unethical and abusive, as well as privacy-, and copyright-infringing contents. While defensive algorithms such as AdvDM and Photoguard have been shown to disrupt the diffusion process on these images, the misalignment between their objectives and the iterative denoising trajectory at test time results in weak disruptive performance.In this work, we present the DDIM Inversion Attack (DIA) that attacks the integrated DDIM trajectory path. Our results support the effective disruption, surpassing previous defensive methods across various editing methods. We believe that our frameworks and results can provide practical defense methods against the malicious use of AI for both the industry and the research community. Our code is available here: https://anonymous.4open.science/r/DIA-13419/.
SpecXNet: A Dual-Domain Convolutional Network for Robust Deepfake Detection
Sep 26, 2025



The increasing realism of content generated by GANs and diffusion models has made deepfake detection significantly more challenging. Existing approaches often focus solely on spatial or frequency-domain features, limiting their generalization to unseen manipulations. We propose the Spectral Cross-Attentional Network (SpecXNet), a dual-domain architecture for robust deepfake detection. The core \textbf{Dual-Domain Feature Coupler (DDFC)} decomposes features into a local spatial branch for capturing texture-level anomalies and a global spectral branch that employs Fast Fourier Transform to model periodic inconsistencies. This dual-domain formulation allows SpecXNet to jointly exploit localized detail and global structural coherence, which are critical for distinguishing authentic from manipulated images. We also introduce the \textbf{Dual Fourier Attention (DFA)} module, which dynamically fuses spatial and spectral features in a content-aware manner. Built atop a modified XceptionNet backbone, we embed the DDFC and DFA modules within a separable convolution block. Extensive experiments on multiple deepfake benchmarks show that SpecXNet achieves state-of-the-art accuracy, particularly under cross-dataset and unseen manipulation scenarios, while maintaining real-time feasibility. Our results highlight the effectiveness of unified spatial-spectral learning for robust and generalizable deepfake detection. To ensure reproducibility, we released the full code on \href{https://github.com/inzamamulDU/SpecXNet}{\textcolor{blue}{\textbf{GitHub}}}.
Fitting Image Diffusion Models on Video Datasets
Sep 04, 2025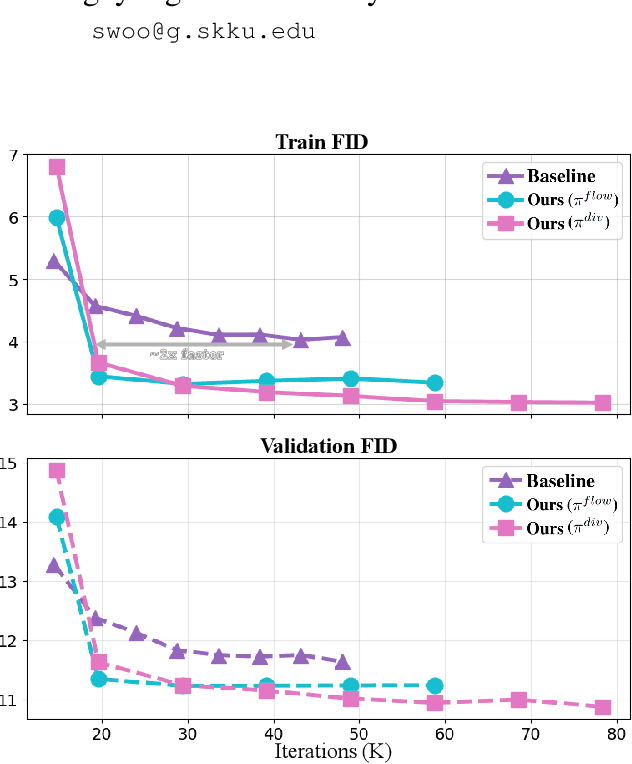
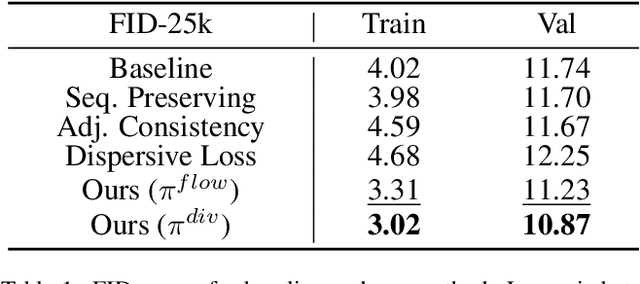
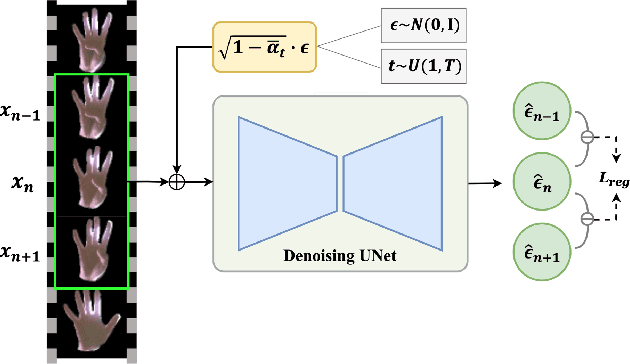
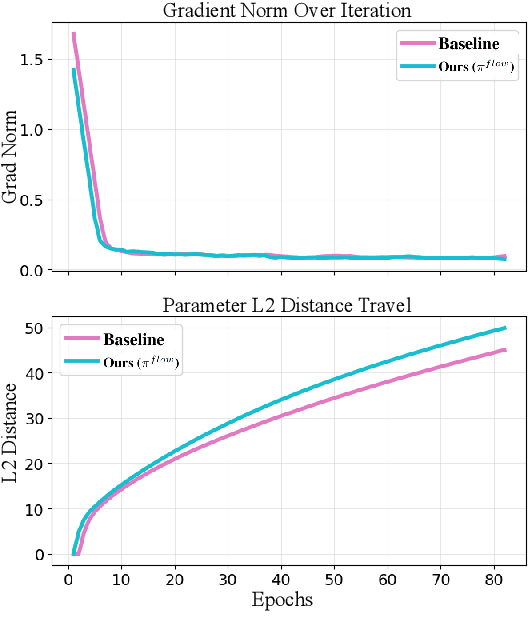
Image diffusion models are trained on independently sampled static images. While this is the bedrock task protocol in generative modeling, capturing the temporal world through the lens of static snapshots is information-deficient by design. This limitation leads to slower convergence, limited distributional coverage, and reduced generalization. In this work, we propose a simple and effective training strategy that leverages the temporal inductive bias present in continuous video frames to improve diffusion training. Notably, the proposed method requires no architectural modification and can be seamlessly integrated into standard diffusion training pipelines. We evaluate our method on the HandCo dataset, where hand-object interactions exhibit dense temporal coherence and subtle variations in finger articulation often result in semantically distinct motions. Empirically, our method accelerates convergence by over 2$\text{x}$ faster and achieves lower FID on both training and validation distributions. It also improves generative diversity by encouraging the model to capture meaningful temporal variations. We further provide an optimization analysis showing that our regularization reduces the gradient variance, which contributes to faster convergence.
Translation of Text Embedding via Delta Vector to Suppress Strongly Entangled Content in Text-to-Image Diffusion Models
Aug 14, 2025Text-to-Image (T2I) diffusion models have made significant progress in generating diverse high-quality images from textual prompts. However, these models still face challenges in suppressing content that is strongly entangled with specific words. For example, when generating an image of ``Charlie Chaplin", a ``mustache" consistently appears even if explicitly instructed not to include it, as the concept of ``mustache" is strongly entangled with ``Charlie Chaplin". To address this issue, we propose a novel approach to directly suppress such entangled content within the text embedding space of diffusion models. Our method introduces a delta vector that modifies the text embedding to weaken the influence of undesired content in the generated image, and we further demonstrate that this delta vector can be easily obtained through a zero-shot approach. Furthermore, we propose a Selective Suppression with Delta Vector (SSDV) method to adapt delta vector into the cross-attention mechanism, enabling more effective suppression of unwanted content in regions where it would otherwise be generated. Additionally, we enabled more precise suppression in personalized T2I models by optimizing delta vector, which previous baselines were unable to achieve. Extensive experimental results demonstrate that our approach significantly outperforms existing methods, both in terms of quantitative and qualitative metrics.
From Prediction to Explanation: Multimodal, Explainable, and Interactive Deepfake Detection Framework for Non-Expert Users
Aug 11, 2025The proliferation of deepfake technologies poses urgent challenges and serious risks to digital integrity, particularly within critical sectors such as forensics, journalism, and the legal system. While existing detection systems have made significant progress in classification accuracy, they typically function as black-box models, offering limited transparency and minimal support for human reasoning. This lack of interpretability hinders their usability in real-world decision-making contexts, especially for non-expert users. In this paper, we present DF-P2E (Deepfake: Prediction to Explanation), a novel multimodal framework that integrates visual, semantic, and narrative layers of explanation to make deepfake detection interpretable and accessible. The framework consists of three modular components: (1) a deepfake classifier with Grad-CAM-based saliency visualisation, (2) a visual captioning module that generates natural language summaries of manipulated regions, and (3) a narrative refinement module that uses a fine-tuned Large Language Model (LLM) to produce context-aware, user-sensitive explanations. We instantiate and evaluate the framework on the DF40 benchmark, the most diverse deepfake dataset to date. Experiments demonstrate that our system achieves competitive detection performance while providing high-quality explanations aligned with Grad-CAM activations. By unifying prediction and explanation in a coherent, human-aligned pipeline, this work offers a scalable approach to interpretable deepfake detection, advancing the broader vision of trustworthy and transparent AI systems in adversarial media environments.
Fairness and Robustness in Machine Unlearning
Apr 18, 2025Machine unlearning poses the challenge of ``how to eliminate the influence of specific data from a pretrained model'' in regard to privacy concerns. While prior research on approximated unlearning has demonstrated accuracy and efficiency in time complexity, we claim that it falls short of achieving exact unlearning, and we are the first to focus on fairness and robustness in machine unlearning algorithms. Our study presents fairness Conjectures for a well-trained model, based on the variance-bias trade-off characteristic, and considers their relevance to robustness. Our Conjectures are supported by experiments conducted on the two most widely used model architectures, ResNet and ViT, demonstrating the correlation between fairness and robustness: \textit{the higher fairness-gap is, the more the model is sensitive and vulnerable}. In addition, our experiments demonstrate the vulnerability of current state-of-the-art approximated unlearning algorithms to adversarial attacks, where their unlearned models suffer a significant drop in accuracy compared to the exact-unlearned models. We claim that our fairness-gap measurement and robustness metric should be used to evaluate the unlearning algorithm. Furthermore, we demonstrate that unlearning in the intermediate and last layers is sufficient and cost-effective for time and memory complexity.
Saliency-Aware Diffusion Reconstruction for Effective Invisible Watermark Removal
Apr 17, 2025

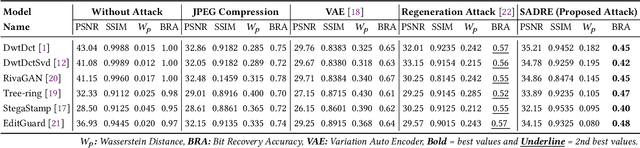
As digital content becomes increasingly ubiquitous, the need for robust watermark removal techniques has grown due to the inadequacy of existing embedding techniques, which lack robustness. This paper introduces a novel Saliency-Aware Diffusion Reconstruction (SADRE) framework for watermark elimination on the web, combining adaptive noise injection, region-specific perturbations, and advanced diffusion-based reconstruction. SADRE disrupts embedded watermarks by injecting targeted noise into latent representations guided by saliency masks although preserving essential image features. A reverse diffusion process ensures high-fidelity image restoration, leveraging adaptive noise levels determined by watermark strength. Our framework is theoretically grounded with stability guarantees and achieves robust watermark removal across diverse scenarios. Empirical evaluations on state-of-the-art (SOTA) watermarking techniques demonstrate SADRE's superiority in balancing watermark disruption and image quality. SADRE sets a new benchmark for watermark elimination, offering a flexible and reliable solution for real-world web content. Code is available on~\href{https://github.com/inzamamulDU/SADRE}{\textbf{https://github.com/inzamamulDU/SADRE}}.
Towards Safe Synthetic Image Generation On the Web: A Multimodal Robust NSFW Defense and Million Scale Dataset
Apr 16, 2025In the past years, we have witnessed the remarkable success of Text-to-Image (T2I) models and their widespread use on the web. Extensive research in making T2I models produce hyper-realistic images has led to new concerns, such as generating Not-Safe-For-Work (NSFW) web content and polluting the web society. To help prevent misuse of T2I models and create a safer web environment for users features like NSFW filters and post-hoc security checks are used in these models. However, recent work unveiled how these methods can easily fail to prevent misuse. In particular, adversarial attacks on text and image modalities can easily outplay defensive measures. %Exploiting such leads to the growing concern of preventing adversarial attacks on text and image modalities. Moreover, there is currently no robust multimodal NSFW dataset that includes both prompt and image pairs and adversarial examples. This work proposes a million-scale prompt and image dataset generated using open-source diffusion models. Second, we develop a multimodal defense to distinguish safe and NSFW text and images, which is robust against adversarial attacks and directly alleviates current challenges. Our extensive experiments show that our model performs well against existing SOTA NSFW detection methods in terms of accuracy and recall, drastically reducing the Attack Success Rate (ASR) in multimodal adversarial attack scenarios. Code: https://github.com/shahidmuneer/multimodal-nsfw-defense.
MIXAD: Memory-Induced Explainable Time Series Anomaly Detection
Oct 30, 2024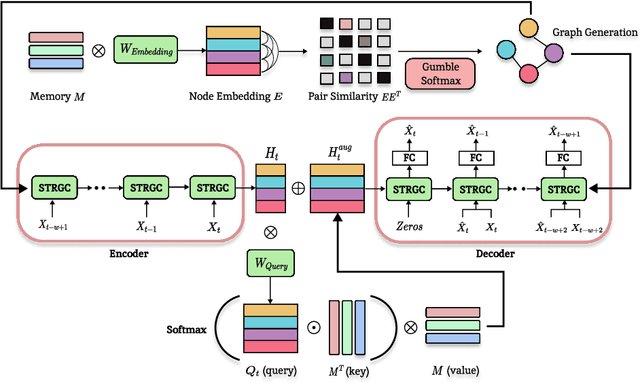


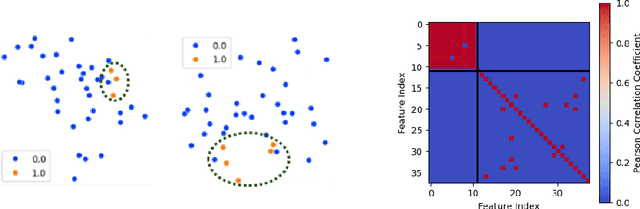
For modern industrial applications, accurately detecting and diagnosing anomalies in multivariate time series data is essential. Despite such need, most state-of-the-art methods often prioritize detection performance over model interpretability. Addressing this gap, we introduce MIXAD (Memory-Induced Explainable Time Series Anomaly Detection), a model designed for interpretable anomaly detection. MIXAD leverages a memory network alongside spatiotemporal processing units to understand the intricate dynamics and topological structures inherent in sensor relationships. We also introduce a novel anomaly scoring method that detects significant shifts in memory activation patterns during anomalies. Our approach not only ensures decent detection performance but also outperforms state-of-the-art baselines by 34.30% and 34.51% in interpretability metrics.