 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIA: The Adversarial Exposure of Deterministic Inversion in Diffusion Models
Oct 01, 2025Diffusion models have shown to be strong representation learners, showcasing state-of-the-art performance across multiple domains. Aside from accelerated sampling, DDIM also enables the inversion of real images back to their latent codes. A direct inheriting application of this inversion operation is real image editing, where the inversion yields latent trajectories to be utilized during the synthesis of the edited image. Unfortunately, this practical tool has enabled malicious users to freely synthesize misinformative or deepfake contents with greater ease, which promotes the spread of unethical and abusive, as well as privacy-, and copyright-infringing contents. While defensive algorithms such as AdvDM and Photoguard have been shown to disrupt the diffusion process on these images, the misalignment between their objectives and the iterative denoising trajectory at test time results in weak disruptive performance.In this work, we present the DDIM Inversion Attack (DIA) that attacks the integrated DDIM trajectory path. Our results support the effective disruption, surpassing previous defensive methods across various editing methods. We believe that our frameworks and results can provide practical defense methods against the malicious use of AI for both the industry and the research community. Our code is available here: https://anonymous.4open.science/r/DIA-13419/.
Preserving Old Memories in Vivid Detail: Human-Interactive Photo Restoration Framework
Oct 12, 2024Photo restoration technology enables preserving visual memories in photographs. However, physical prints are vulnerable to various forms of deterioration, ranging from physical damage to loss of image quality, etc. While restoration by human experts can improve the quality of outcomes, it often comes at a high price in terms of cost and time for restoration. In this work, we present the AI-based photo restoration framework composed of multiple stages, where each stage is tailored to enhance and restore specific types of photo damage, accelerating and automating the photo restoration process. By integrating these techniques into a unified architecture, our framework aims to offer a one-stop solution for restoring old and deteriorated photographs. Furthermore, we present a novel old photo restoration dataset because we lack a publicly available dataset for our evaluation.
Disrupting Diffusion-based Inpainters with Semantic Digression
Jul 14, 2024
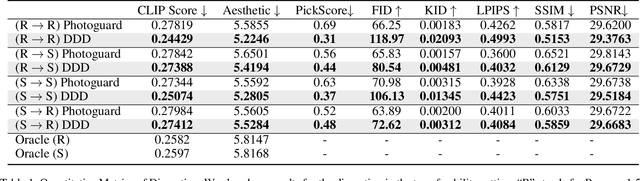
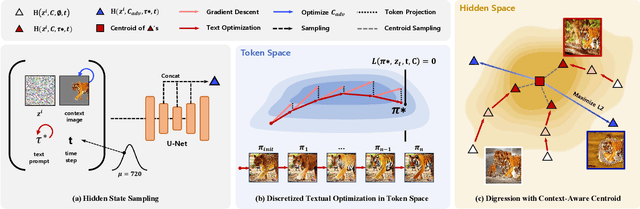

The fabrication of visual misinformation on the web and social media has increased exponentially with the advent of foundational text-to-image diffusion models. Namely, Stable Diffusion inpainters allow the synthesis of maliciously inpainted images of personal and private figures, and copyrighted contents, also known as deepfakes. To combat such generations, a disruption framework, namely Photoguard, has been proposed, where it adds adversarial noise to the context image to disrupt their inpainting synthesis. While their framework suggested a diffusion-friendly approach, the disruption is not sufficiently strong and it requires a significant amount of GPU and time to immunize the context image. In our work, we re-examine both the minimal and favorable conditions for a successful inpainting disruption, proposing DDD, a "Digression guided Diffusion Disruption" framework. First, we identify the most adversarially vulnerable diffusion timestep range with respect to the hidden space. Within this scope of noised manifold, we pose the problem as a semantic digression optimization. We maximize the distance between the inpainting instance's hidden states and a semantic-aware hidden state centroid, calibrated both by Monte Carlo sampling of hidden states and a discretely projected optimization in the token space. Effectively, our approach achieves stronger disruption and a higher success rate than Photoguard while lowering the GPU memory requirement, and speeding the optimization up to three times faster.