 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Workflow to Efficiently Generate Dense Tissue Ground Truth Masks for Digital Breast Tomosynthesis
Apr 13, 2026Digital breast tomosynthesis (DBT) is now the standard of care for breast cancer screening in the USA. Accurate segmentation of fibroglandular tissue in DBT images is essential for personalized risk estimation, but algorithm development is limited by scarce human-delineated training data. In this study we introduce a time- and labor-saving framework to generate a human-annotated binary segmentation mask for dense tissue in DBT. Our framework enables a user to outline a rough region of interest (ROI) enclosing dense tissue on the central reconstructed slice of a DBT volume and select a segmentation threshold to generate the dense tissue mask. The algorithm then projects the ROI to the remaining slices and iteratively adjusts slice-specific thresholds to maintain consistent dense tissue delineation across the DBT volume. By requiring annotation only on the central slice, the framework substantially reduces annotation time and labor. We used 44 DBT volumes from the DBTex dataset for evaluation. Inter-reader agreement was assessed by computing patient-wise Dice similarity coefficients between segmentation masks produced by two radiologists, yielding a median of 0.84. Accuracy of the proposed method was evaluated by having a radiologist manually segment the 20th and 80th percentile slices from each volume (CC and MLO views; 176 slices total) and calculate Dice scores between the manual and proposed segmentations, yielding a median of 0.83.
DIA: The Adversarial Exposure of Deterministic Inversion in Diffusion Models
Oct 01, 2025Diffusion models have shown to be strong representation learners, showcasing state-of-the-art performance across multiple domains. Aside from accelerated sampling, DDIM also enables the inversion of real images back to their latent codes. A direct inheriting application of this inversion operation is real image editing, where the inversion yields latent trajectories to be utilized during the synthesis of the edited image. Unfortunately, this practical tool has enabled malicious users to freely synthesize misinformative or deepfake contents with greater ease, which promotes the spread of unethical and abusive, as well as privacy-, and copyright-infringing contents. While defensive algorithms such as AdvDM and Photoguard have been shown to disrupt the diffusion process on these images, the misalignment between their objectives and the iterative denoising trajectory at test time results in weak disruptive performance.In this work, we present the DDIM Inversion Attack (DIA) that attacks the integrated DDIM trajectory path. Our results support the effective disruption, surpassing previous defensive methods across various editing methods. We believe that our frameworks and results can provide practical defense methods against the malicious use of AI for both the industry and the research community. Our code is available here: https://anonymous.4open.science/r/DIA-13419/.
Fitting Image Diffusion Models on Video Datasets
Sep 04, 2025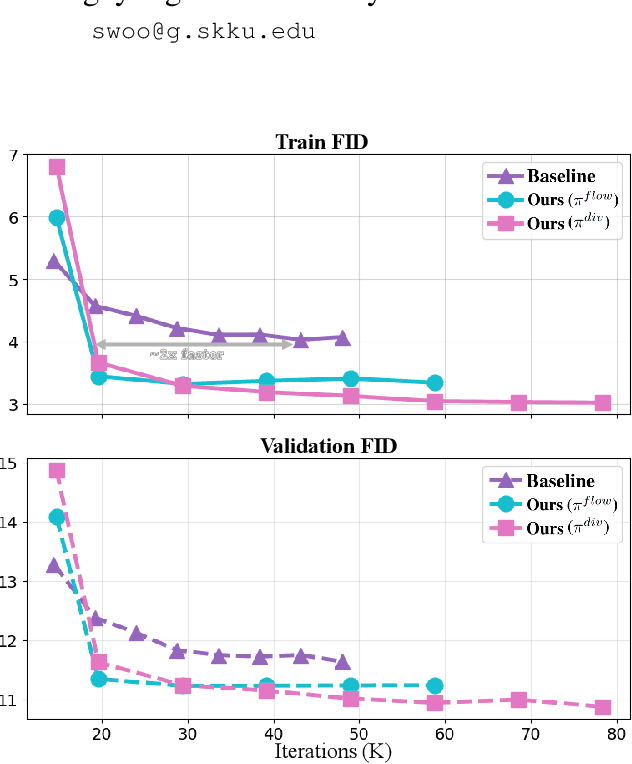
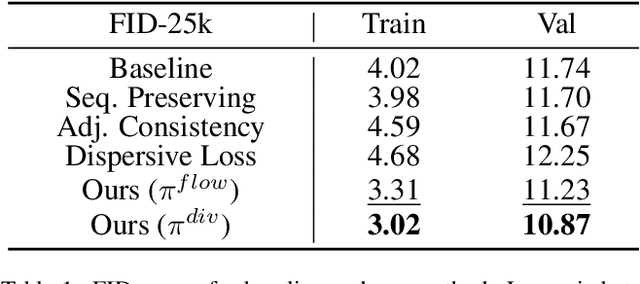
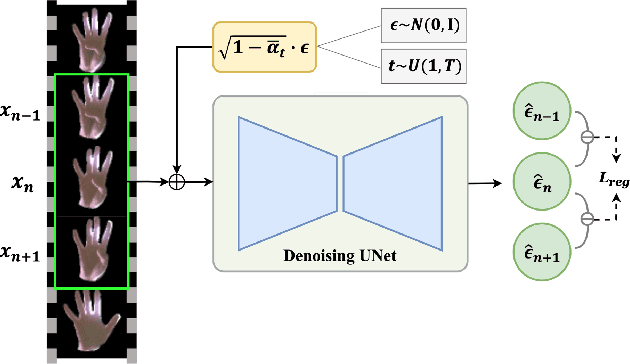
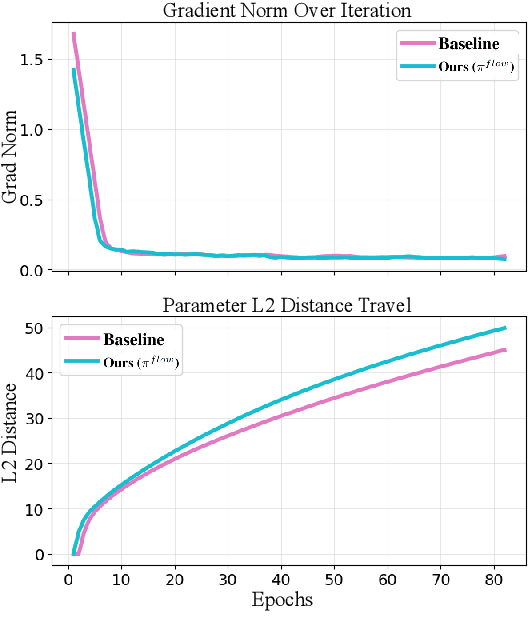
Image diffusion models are trained on independently sampled static images. While this is the bedrock task protocol in generative modeling, capturing the temporal world through the lens of static snapshots is information-deficient by design. This limitation leads to slower convergence, limited distributional coverage, and reduced generalization. In this work, we propose a simple and effective training strategy that leverages the temporal inductive bias present in continuous video frames to improve diffusion training. Notably, the proposed method requires no architectural modification and can be seamlessly integrated into standard diffusion training pipelines. We evaluate our method on the HandCo dataset, where hand-object interactions exhibit dense temporal coherence and subtle variations in finger articulation often result in semantically distinct motions. Empirically, our method accelerates convergence by over 2$\text{x}$ faster and achieves lower FID on both training and validation distributions. It also improves generative diversity by encouraging the model to capture meaningful temporal variations. We further provide an optimization analysis showing that our regularization reduces the gradient variance, which contributes to faster convergence.
Disrupting Diffusion-based Inpainters with Semantic Digression
Jul 14, 2024
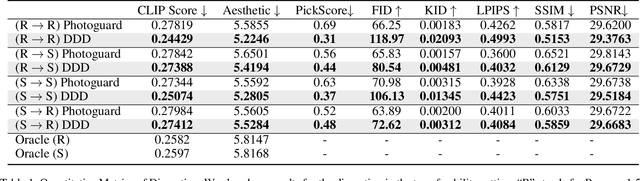
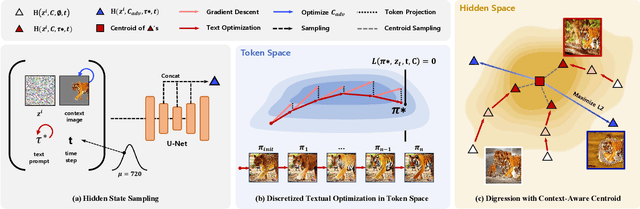

The fabrication of visual misinformation on the web and social media has increased exponentially with the advent of foundational text-to-image diffusion models. Namely, Stable Diffusion inpainters allow the synthesis of maliciously inpainted images of personal and private figures, and copyrighted contents, also known as deepfakes. To combat such generations, a disruption framework, namely Photoguard, has been proposed, where it adds adversarial noise to the context image to disrupt their inpainting synthesis. While their framework suggested a diffusion-friendly approach, the disruption is not sufficiently strong and it requires a significant amount of GPU and time to immunize the context image. In our work, we re-examine both the minimal and favorable conditions for a successful inpainting disruption, proposing DDD, a "Digression guided Diffusion Disruption" framework. First, we identify the most adversarially vulnerable diffusion timestep range with respect to the hidden space. Within this scope of noised manifold, we pose the problem as a semantic digression optimization. We maximize the distance between the inpainting instance's hidden states and a semantic-aware hidden state centroid, calibrated both by Monte Carlo sampling of hidden states and a discretely projected optimization in the token space. Effectively, our approach achieves stronger disruption and a higher success rate than Photoguard while lowering the GPU memory requirement, and speeding the optimization up to three times faster.
All but One: Surgical Concept Erasing with Model Preservation in Text-to-Image Diffusion Models
Dec 20, 2023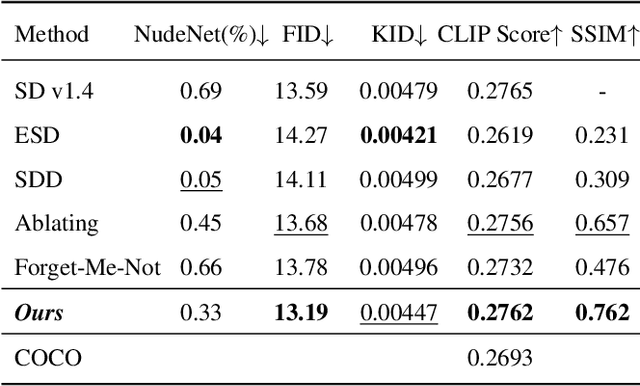

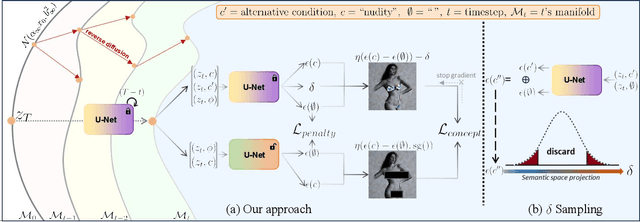
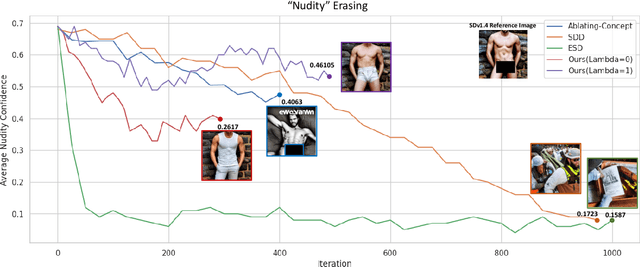
Text-to-Image models such as Stable Diffusion have shown impressive image generation synthesis, thanks to the utilization of large-scale datasets. However, these datasets may contain sexually explicit, copyrighted, or undesirable content, which allows the model to directly generate them. Given that retraining these large models on individual concept deletion requests is infeasible, fine-tuning algorithms have been developed to tackle concept erasing in diffusion models. While these algorithms yield good concept erasure, they all present one of the following issues: 1) the corrupted feature space yields synthesis of disintegrated objects, 2) the initially synthesized content undergoes a divergence in both spatial structure and semantics in the generated images, and 3) sub-optimal training updates heighten the model's susceptibility to utility harm. These issues severely degrade the original utility of generative models. In this work, we present a new approach that solves all of these challenges. We take inspiration from the concept of classifier guidance and propose a surgical update on the classifier guidance term while constraining the drift of the unconditional score term. Furthermore, our algorithm empowers the user to select an alternative to the erasing concept, allowing for more controllability. Our experimental results show that our algorithm not only erases the target concept effectively but also preserves the model's generation capability.
Identifying Women with Mammographically-Occult Breast Cancer Leveraging GAN-Simulated Mammograms
Sep 24, 2021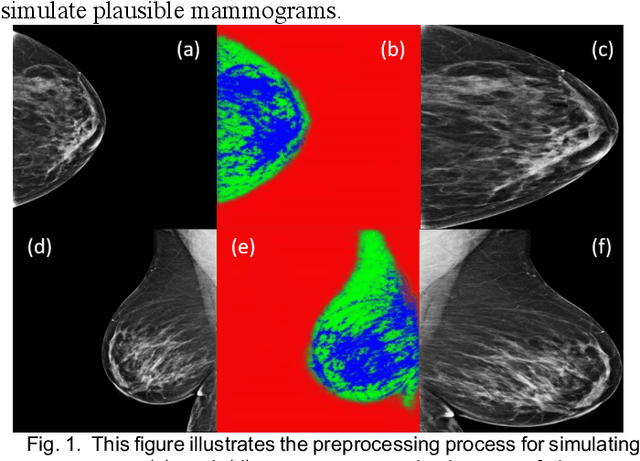



Our objective is to show the feasibility of using simulated mammograms to detect mammographically-occult (MO) cancer in women with dense breasts and a normal screening mammogram who could be triaged for additional screening with magnetic resonance imaging (MRI) or ultrasound. We developed a Conditional Generative Adversarial Network (CGAN) to simulate a mammogram with normal appearance using the opposite mammogram as the condition. We used a Convolutional Neural Network (CNN) trained on Radon Cumulative Distribution Transform (RCDT) processed mammograms to detect MO cancer. For training CGAN, we used screening mammograms of 1366 women. For MO cancer detection, we used screening mammograms of 333 women (97 MO cancer) with dense breasts. We simulated the right mammogram for normal controls and the cancer side for MO cancer cases. We created two RCDT images, one from a real mammogram pair and another from a real-simulated mammogram pair. We finetuned a VGG16 on resulting RCDT images to classify the women with MO cancer. We compared the classification performance of the CNN trained on fused RCDT images, CNN_{Fused} to that of trained only on real RCDT images, CNN_{Real}, and to that of trained only on simulated RCDT images, CNN_{Simulated}. The test AUC for CNN_{Fused} was 0.77 with a 95% confidence interval (95CI) of [0.71, 0.83], which was statistically better (p-value < 0.02) than the CNN_{Real} AUC of 0.70 with a 95CI of [0.64, 0.77] and CNN_{Simulated} AUC of 0.68 with a 95CI of [0.62, 0.75]. It showed that CGAN simulated mammograms can help MO cancer detection.