 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIA: The Adversarial Exposure of Deterministic Inversion in Diffusion Models
Oct 01, 2025Diffusion models have shown to be strong representation learners, showcasing state-of-the-art performance across multiple domains. Aside from accelerated sampling, DDIM also enables the inversion of real images back to their latent codes. A direct inheriting application of this inversion operation is real image editing, where the inversion yields latent trajectories to be utilized during the synthesis of the edited image. Unfortunately, this practical tool has enabled malicious users to freely synthesize misinformative or deepfake contents with greater ease, which promotes the spread of unethical and abusive, as well as privacy-, and copyright-infringing contents. While defensive algorithms such as AdvDM and Photoguard have been shown to disrupt the diffusion process on these images, the misalignment between their objectives and the iterative denoising trajectory at test time results in weak disruptive performance.In this work, we present the DDIM Inversion Attack (DIA) that attacks the integrated DDIM trajectory path. Our results support the effective disruption, surpassing previous defensive methods across various editing methods. We believe that our frameworks and results can provide practical defense methods against the malicious use of AI for both the industry and the research community. Our code is available here: https://anonymous.4open.science/r/DIA-13419/.
Translation of Text Embedding via Delta Vector to Suppress Strongly Entangled Content in Text-to-Image Diffusion Models
Aug 14, 2025Text-to-Image (T2I) diffusion models have made significant progress in generating diverse high-quality images from textual prompts. However, these models still face challenges in suppressing content that is strongly entangled with specific words. For example, when generating an image of ``Charlie Chaplin", a ``mustache" consistently appears even if explicitly instructed not to include it, as the concept of ``mustache" is strongly entangled with ``Charlie Chaplin". To address this issue, we propose a novel approach to directly suppress such entangled content within the text embedding space of diffusion models. Our method introduces a delta vector that modifies the text embedding to weaken the influence of undesired content in the generated image, and we further demonstrate that this delta vector can be easily obtained through a zero-shot approach. Furthermore, we propose a Selective Suppression with Delta Vector (SSDV) method to adapt delta vector into the cross-attention mechanism, enabling more effective suppression of unwanted content in regions where it would otherwise be generated. Additionally, we enabled more precise suppression in personalized T2I models by optimizing delta vector, which previous baselines were unable to achieve. Extensive experimental results demonstrate that our approach significantly outperforms existing methods, both in terms of quantitative and qualitative metrics.
All but One: Surgical Concept Erasing with Model Preservation in Text-to-Image Diffusion Models
Dec 20, 2023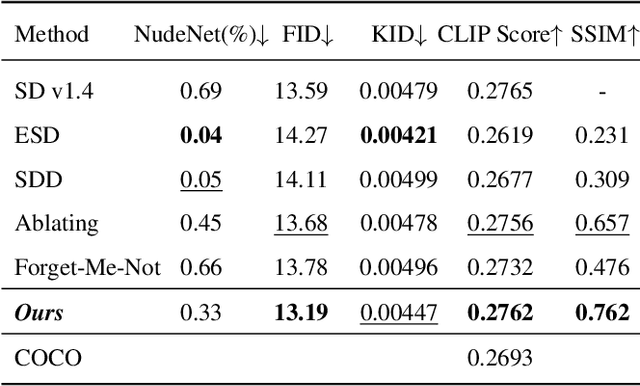

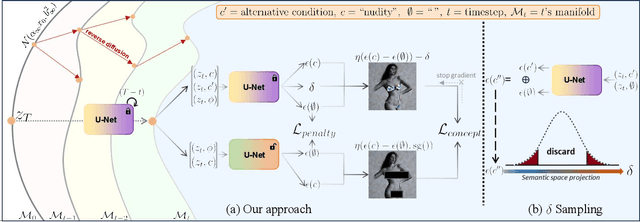
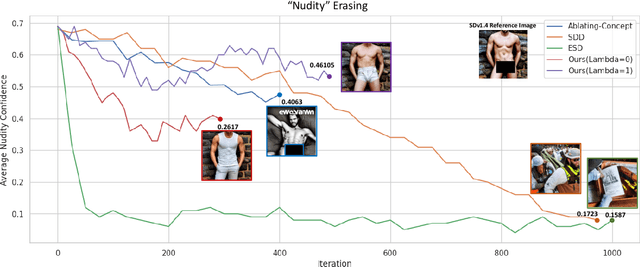
Text-to-Image models such as Stable Diffusion have shown impressive image generation synthesis, thanks to the utilization of large-scale datasets. However, these datasets may contain sexually explicit, copyrighted, or undesirable content, which allows the model to directly generate them. Given that retraining these large models on individual concept deletion requests is infeasible, fine-tuning algorithms have been developed to tackle concept erasing in diffusion models. While these algorithms yield good concept erasure, they all present one of the following issues: 1) the corrupted feature space yields synthesis of disintegrated objects, 2) the initially synthesized content undergoes a divergence in both spatial structure and semantics in the generated images, and 3) sub-optimal training updates heighten the model's susceptibility to utility harm. These issues severely degrade the original utility of generative models. In this work, we present a new approach that solves all of these challenges. We take inspiration from the concept of classifier guidance and propose a surgical update on the classifier guidance term while constraining the drift of the unconditional score term. Furthermore, our algorithm empowers the user to select an alternative to the erasing concept, allowing for more controllability. Our experimental results show that our algorithm not only erases the target concept effectively but also preserves the model's generation capability.