 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind-Match: Efficient Homomorphic Encryption-Based 1:N Matching for Privacy-Preserving Biometric Identification
Aug 12, 2024We present Blind-Match, a novel biometric identification system that leverages homomorphic encryption (HE) for efficient and privacy-preserving 1:N matching. Blind-Match introduces a HE-optimized cosine similarity computation method, where the key idea is to divide the feature vector into smaller parts for processing rather than computing the entire vector at once. By optimizing the number of these parts, Blind-Match minimizes execution time while ensuring data privacy through HE. Blind-Match achieves superior performance compared to state-of-the-art methods across various biometric datasets. On the LFW face dataset, Blind-Match attains a 99.63% Rank-1 accuracy with a 128-dimensional feature vector, demonstrating its robustness in face recognition tasks. For fingerprint identification, Blind-Match achieves a remarkable 99.55% Rank-1 accuracy on the PolyU dataset, even with a compact 16-dimensional feature vector, significantly outperforming the state-of-the-art method, Blind-Touch, which achieves only 59.17%. Furthermore, Blind-Match showcases practical efficiency in large-scale biometric identification scenarios, such as Naver Cloud's FaceSign, by processing 6,144 biometric samples in 0.74 seconds using a 128-dimensional feature vector.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
FaceFusion: Exploiting Full Spectrum of Multiple Datasets
May 24, 2023



The size of training dataset is known to be among the most dominating aspects of training high-performance face recognition embedding model. Building a large dataset from scratch could be cumbersome and time-intensive, while combining multiple already-built datasets poses the risk of introducing large amount of label noise. We present a novel training method, named FaceFusion. It creates a fused view of different datasets that is untainted by identity conflicts, while concurrently training an embedding network using the view in an end-to-end fashion. Using the unified view of combined datasets enables the embedding network to be trained against the entire spectrum of the datasets, leading to a noticeable performance boost. Extensive experiments confirm superiority of our method, whose performance in public evaluation datasets surpasses not only that of using a single training dataset, but also that of previously known methods under various training circumstances.
LightMove: A Lightweight Next-POI Recommendation for Taxicab Rooftop Advertising
Aug 18, 2021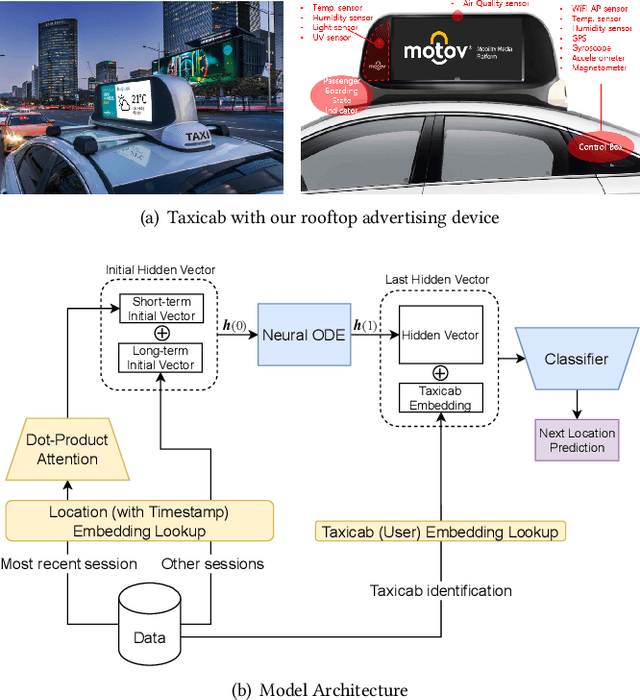

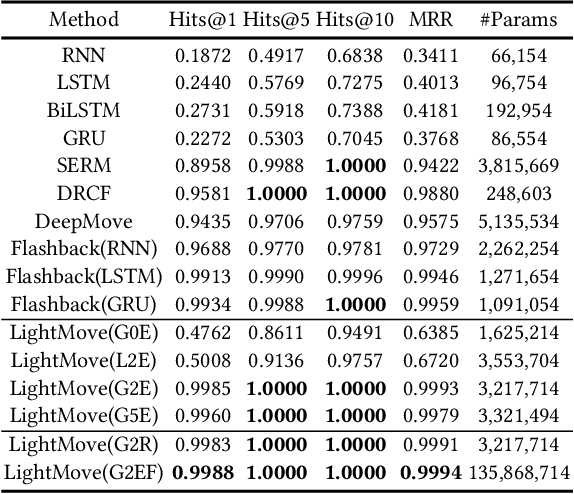
Mobile digital billboards are an effective way to augment brand-awareness. Among various such mobile billboards, taxicab rooftop devices are emerging in the market as a brand new media. Motov is a leading company in South Korea in the taxicab rooftop advertising market. In this work, we present a lightweight yet accurate deep learning-based method to predict taxicabs' next locations to better prepare for targeted advertising based on demographic information of locations. Considering the fact that next POI recommendation datasets are frequently sparse, we design our presented model based on neural ordinary differential equations (NODEs), which are known to be robust to sparse/incorrect input, with several enhancements. Our model, which we call LightMove, has a larger prediction accuracy, a smaller number of parameters, and/or a smaller training/inference time, when evaluating with various datasets, in comparison with state-of-the-art models.