 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecGuard: Spectral Projection-based Advanced Invisible Watermarking
Oct 08, 2025



Watermarking embeds imperceptible patterns into images for authenticity verification. However, existing methods often lack robustness against various transformations primarily including distortions, image regeneration, and adversarial perturbation, creating real-world challenges. In this work, we introduce SpecGuard, a novel watermarking approach for robust and invisible image watermarking. Unlike prior approaches, we embed the message inside hidden convolution layers by converting from the spatial domain to the frequency domain using spectral projection of a higher frequency band that is decomposed by wavelet projection. Spectral projection employs Fast Fourier Transform approximation to transform spatial data into the frequency domain efficiently. In the encoding phase, a strength factor enhances resilience against diverse attacks, including adversarial, geometric, and regeneration-based distortions, ensuring the preservation of copyrighted information. Meanwhile, the decoder leverages Parseval's theorem to effectively learn and extract the watermark pattern, enabling accurate retrieval under challenging transformations. We evaluate the proposed SpecGuard based on the embedded watermark's invisibility, capacity, and robustness. Comprehensive experiments demonstrate the proposed SpecGuard outperforms the state-of-the-art models. To ensure reproducibility, the full code is released on \href{https://github.com/inzamamulDU/SpecGuard_ICCV_2025}{\textcolor{blue}{\textbf{GitHub}}}.
SpecXNet: A Dual-Domain Convolutional Network for Robust Deepfake Detection
Sep 26, 2025



The increasing realism of content generated by GANs and diffusion models has made deepfake detection significantly more challenging. Existing approaches often focus solely on spatial or frequency-domain features, limiting their generalization to unseen manipulations. We propose the Spectral Cross-Attentional Network (SpecXNet), a dual-domain architecture for robust deepfake detection. The core \textbf{Dual-Domain Feature Coupler (DDFC)} decomposes features into a local spatial branch for capturing texture-level anomalies and a global spectral branch that employs Fast Fourier Transform to model periodic inconsistencies. This dual-domain formulation allows SpecXNet to jointly exploit localized detail and global structural coherence, which are critical for distinguishing authentic from manipulated images. We also introduce the \textbf{Dual Fourier Attention (DFA)} module, which dynamically fuses spatial and spectral features in a content-aware manner. Built atop a modified XceptionNet backbone, we embed the DDFC and DFA modules within a separable convolution block. Extensive experiments on multiple deepfake benchmarks show that SpecXNet achieves state-of-the-art accuracy, particularly under cross-dataset and unseen manipulation scenarios, while maintaining real-time feasibility. Our results highlight the effectiveness of unified spatial-spectral learning for robust and generalizable deepfake detection. To ensure reproducibility, we released the full code on \href{https://github.com/inzamamulDU/SpecXNet}{\textcolor{blue}{\textbf{GitHub}}}.
Saliency-Aware Diffusion Reconstruction for Effective Invisible Watermark Removal
Apr 17, 2025

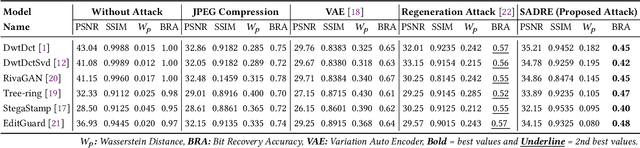
As digital content becomes increasingly ubiquitous, the need for robust watermark removal techniques has grown due to the inadequacy of existing embedding techniques, which lack robustness. This paper introduces a novel Saliency-Aware Diffusion Reconstruction (SADRE) framework for watermark elimination on the web, combining adaptive noise injection, region-specific perturbations, and advanced diffusion-based reconstruction. SADRE disrupts embedded watermarks by injecting targeted noise into latent representations guided by saliency masks although preserving essential image features. A reverse diffusion process ensures high-fidelity image restoration, leveraging adaptive noise levels determined by watermark strength. Our framework is theoretically grounded with stability guarantees and achieves robust watermark removal across diverse scenarios. Empirical evaluations on state-of-the-art (SOTA) watermarking techniques demonstrate SADRE's superiority in balancing watermark disruption and image quality. SADRE sets a new benchmark for watermark elimination, offering a flexible and reliable solution for real-world web content. Code is available on~\href{https://github.com/inzamamulDU/SADRE}{\textbf{https://github.com/inzamamulDU/SADRE}}.
LoLI-Street: Benchmarking Low-Light Image Enhancement and Beyond
Oct 13, 2024Low-light image enhancement (LLIE) is essential for numerous computer vision tasks, including object detection, tracking, segmentation, and scene understanding. Despite substantial research on improving low-quality images captured in underexposed conditions, clear vision remains critical for autonomous vehicles, which often struggle with low-light scenarios, signifying the need for continuous research. However, paired datasets for LLIE are scarce, particularly for street scenes, limiting the development of robust LLIE methods. Despite using advanced transformers and/or diffusion-based models, current LLIE methods struggle in real-world low-light conditions and lack training on street-scene datasets, limiting their effectiveness for autonomous vehicles. To bridge these gaps, we introduce a new dataset LoLI-Street (Low-Light Images of Streets) with 33k paired low-light and well-exposed images from street scenes in developed cities, covering 19k object classes for object detection. LoLI-Street dataset also features 1,000 real low-light test images for testing LLIE models under real-life conditions. Furthermore, we propose a transformer and diffusion-based LLIE model named "TriFuse". Leveraging the LoLI-Street dataset, we train and evaluate our TriFuse and SOTA models to benchmark on our dataset. Comparing various models, our dataset's generalization feasibility is evident in testing across different mainstream datasets by significantly enhancing images and object detection for practical applications in autonomous driving and surveillance systems. The complete code and dataset is available on https://github.com/tanvirnwu/TriFuse.
UGAD: Universal Generative AI Detector utilizing Frequency Fingerprints
Sep 12, 2024In the wake of a fabricated explosion image at the Pentagon, an ability to discern real images from fake counterparts has never been more critical. Our study introduces a novel multi-modal approach to detect AI-generated images amidst the proliferation of new generation methods such as Diffusion models. Our method, UGAD, encompasses three key detection steps: First, we transform the RGB images into YCbCr channels and apply an Integral Radial Operation to emphasize salient radial features. Secondly, the Spatial Fourier Extraction operation is used for a spatial shift, utilizing a pre-trained deep learning network for optimal feature extraction. Finally, the deep neural network classification stage processes the data through dense layers using softmax for classification. Our approach significantly enhances the accuracy of differentiating between real and AI-generated images, as evidenced by a 12.64% increase in accuracy and 28.43% increase in AUC compared to existing state-of-the-art methods.