 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepiSign: Invisible Fragile Watermark to Protect the Integrityand Authenticity of CNN
Paper and Code
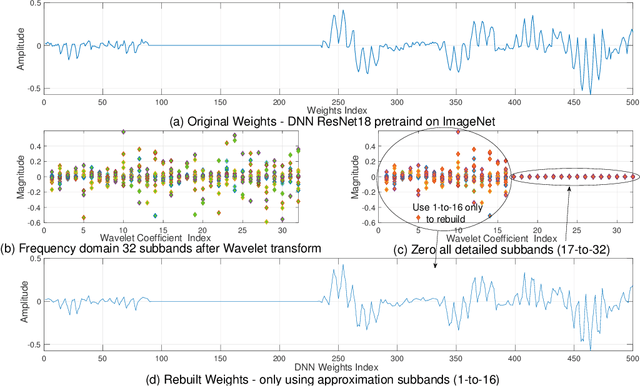
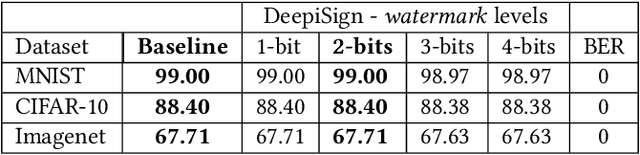
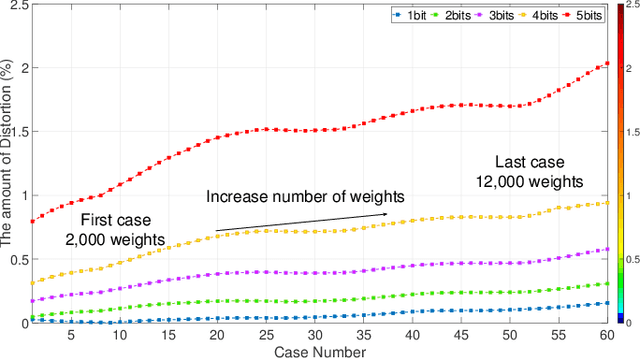

Convolutional Neural Networks (CNNs) deployed in real-life applications such as autonomous vehicles have shown to be vulnerable to manipulation attacks, such as poisoning attacks and fine-tuning. Hence, it is essential to ensure the integrity and authenticity of CNNs because compromised models can produce incorrect outputs and behave maliciously. In this paper, we propose a self-contained tamper-proofing method, called DeepiSign, to ensure the integrity and authenticity of CNN models against such manipulation attacks. DeepiSign applies the idea of fragile invisible watermarking to securely embed a secret and its hash value into a CNN model. To verify the integrity and authenticity of the model, we retrieve the secret from the model, compute the hash value of the secret, and compare it with the embedded hash value. To minimize the effects of the embedded secret on the CNN model, we use a wavelet-based technique to transform weights into the frequency domain and embed the secret into less significant coefficients. Our theoretical analysis shows that DeepiSign can hide up to 1KB secret in each layer with minimal loss of the model's accuracy. To evaluate the security and performance of DeepiSign, we performed experiments on four pre-trained models (ResNet18, VGG16, AlexNet, and MobileNet) using three datasets (MNIST, CIFAR-10, and Imagenet) against three types of manipulation attacks (targeted input poisoning, output poisoning, and fine-tuning). The results demonstrate that DeepiSign is verifiable without degrading the classification accuracy, and robust against representative CNN manipulation attacks.